WWW2020|基于知识图谱的负采样模型在推荐系统中的应用(已开源)

来源:机器学习blog




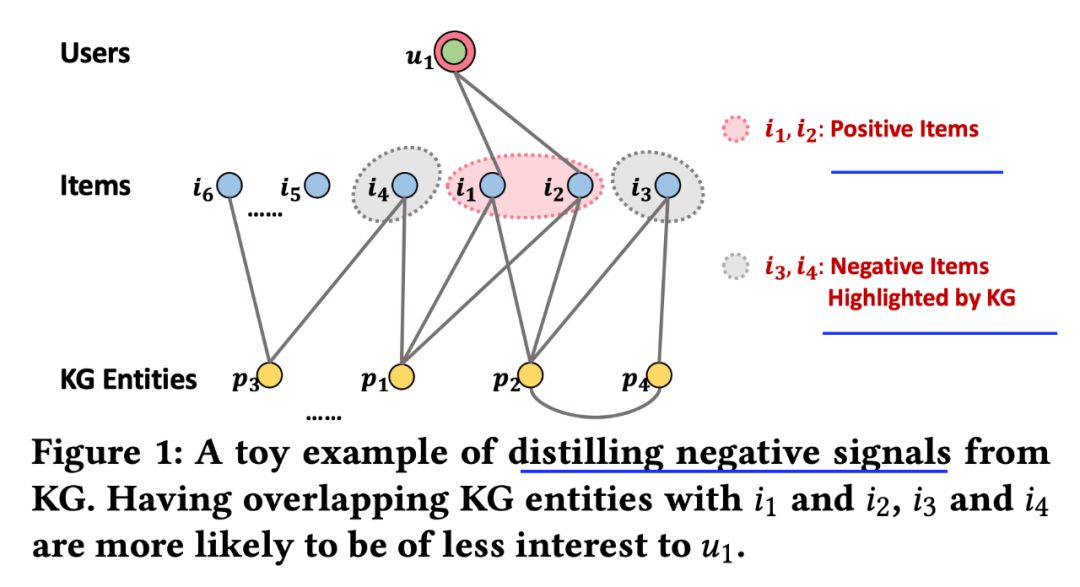






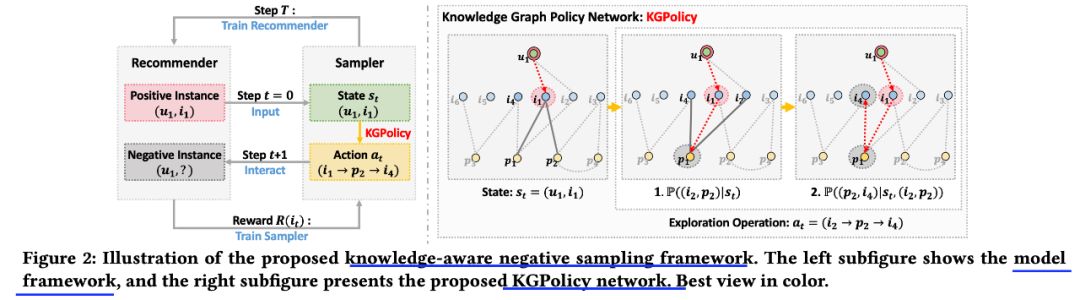





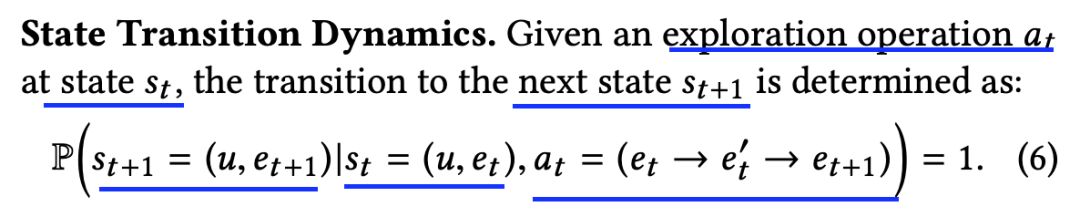






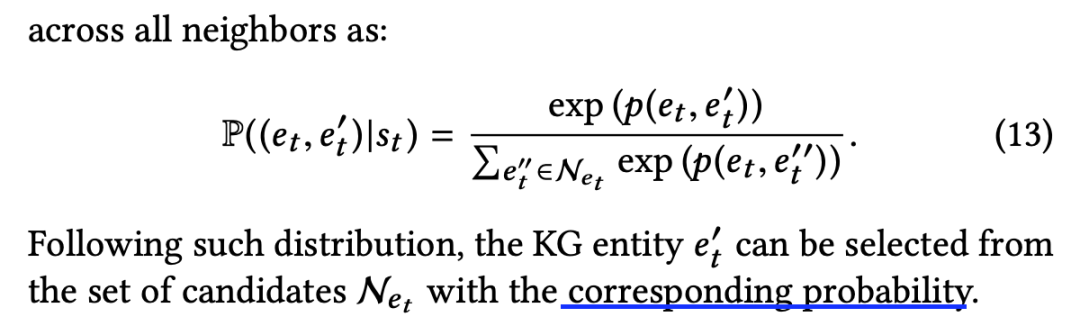



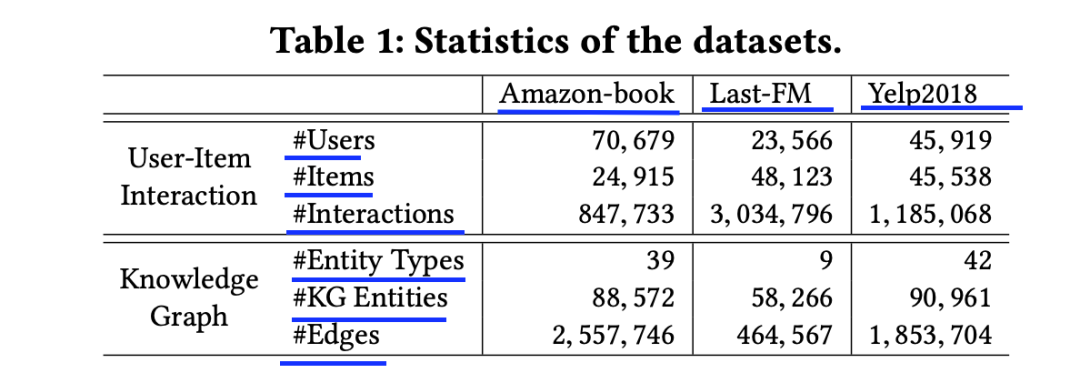




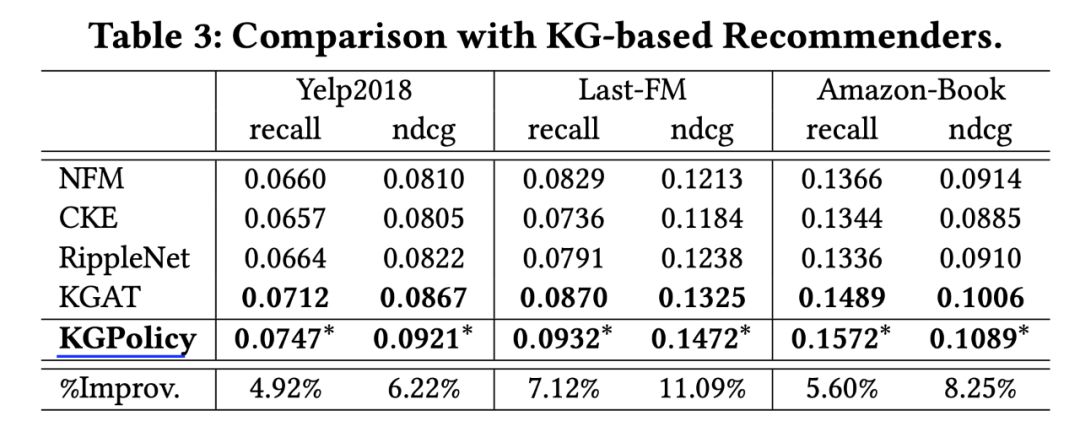
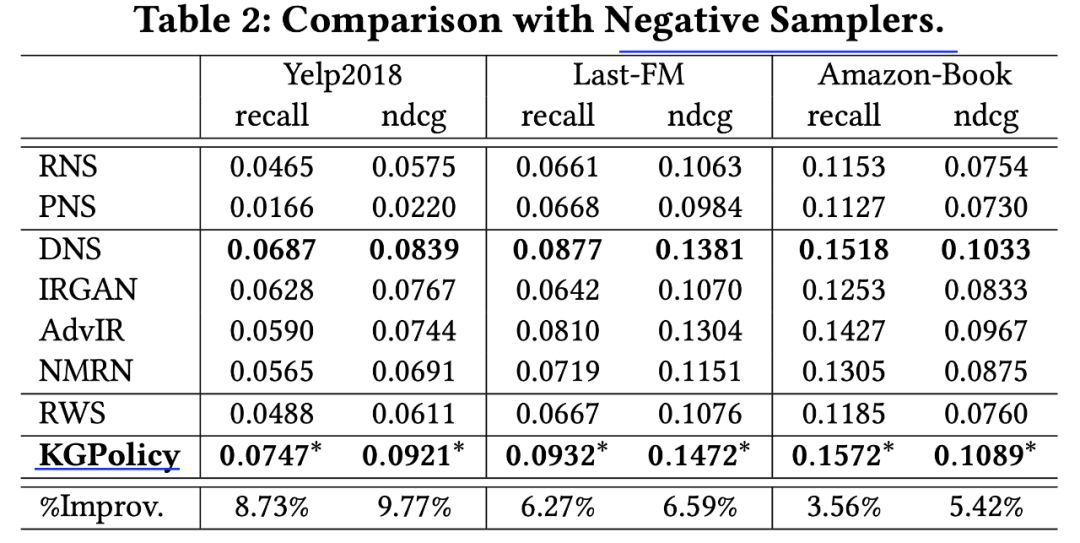
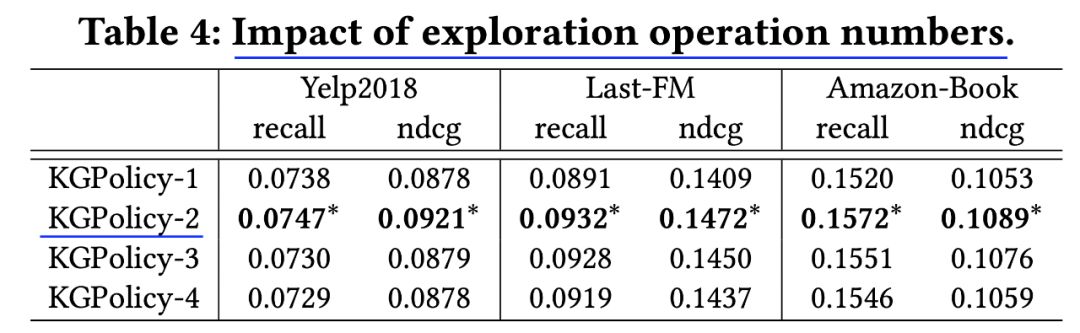
来源:机器学习blog

