![]() 摘要—生成性人工智能(AI)通过使机器能够以空前的复杂性创建和解释视觉数据,迅速推动了计算机视觉领域的发展。这一变革建立在生成模型的基础上,能够生成逼真的图像、视频以及3D/4D内容。传统上,生成模型主要关注视觉逼真度,而往往忽视了生成内容的物理合理性。这一差距限制了其在需要遵守现实世界物理法则的应用中的效果,如机器人技术、自动化系统和科学模拟。随着生成性人工智能不断融入物理现实和动态仿真,其作为“世界模拟器”的潜力不断扩大——能够模拟由物理法则主导的交互,架起虚拟与物理现实之间的桥梁。本综述系统地回顾了这一新兴领域——计算机视觉中的物理感知生成性AI,按其如何融入物理知识对方法进行了分类——无论是通过显式仿真还是隐式学习。我们分析了关键范式,讨论了评估协议,并指出了未来的研究方向。通过提供全面的概述,本综述旨在帮助未来在视觉领域的物理基础生成方面的发展。综述中提到的论文汇总在
摘要—生成性人工智能(AI)通过使机器能够以空前的复杂性创建和解释视觉数据,迅速推动了计算机视觉领域的发展。这一变革建立在生成模型的基础上,能够生成逼真的图像、视频以及3D/4D内容。传统上,生成模型主要关注视觉逼真度,而往往忽视了生成内容的物理合理性。这一差距限制了其在需要遵守现实世界物理法则的应用中的效果,如机器人技术、自动化系统和科学模拟。随着生成性人工智能不断融入物理现实和动态仿真,其作为“世界模拟器”的潜力不断扩大——能够模拟由物理法则主导的交互,架起虚拟与物理现实之间的桥梁。本综述系统地回顾了这一新兴领域——计算机视觉中的物理感知生成性AI,按其如何融入物理知识对方法进行了分类——无论是通过显式仿真还是隐式学习。我们分析了关键范式,讨论了评估协议,并指出了未来的研究方向。通过提供全面的概述,本综述旨在帮助未来在视觉领域的物理基础生成方面的发展。综述中提到的论文汇总在
https://github.com/BestJunYu/Awesome-Physics-aware-Generation
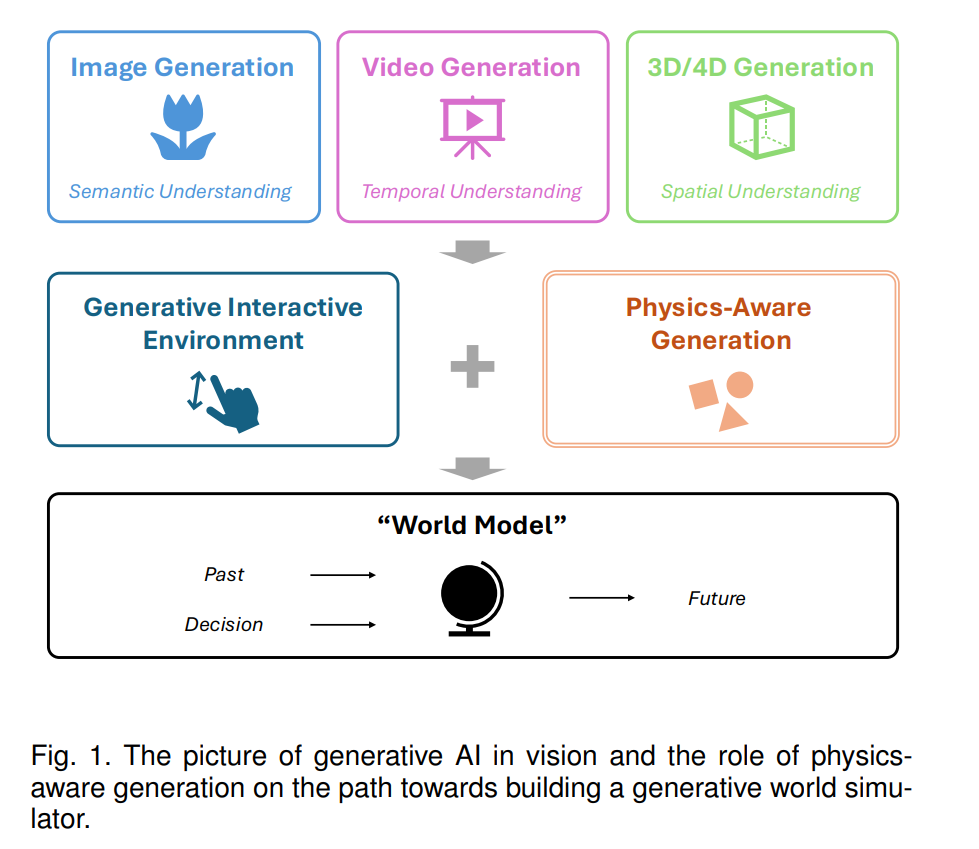
![]() 1 引言生成学习一直是现代计算机视觉的基础支柱,解决了理解、合成和操作视觉数据中的关键挑战。在过去的十年里,该领域见证了多种生成模型的快速发展,包括变分自编码器(VAE)[1]、生成对抗网络(GAN)[3]、扩散模型(DM)[4]、[5]、[6]、神经辐射场(NeRF)[7]、高斯溅射(GS)[8] 和视觉自回归模型(VAR)[9]。这些模型不断推动生成学习的边界,利用越来越强大的架构来捕捉视觉数据的潜在分布。其目标是使机器能够以类似人类的创造性和理解方式推理视觉世界,通过在未见过的场景中想象新的视觉内容实例。在这些进展中,扩散模型因其能够生成高度逼真的输出而成为特别值得注意的技术。通过通过学习到的去噪过程迭代地精炼随机噪声,扩散模型展现出卓越的鲁棒性和多功能性,成为近期生成方法学的基石。生成模型的应用跨越了多种视觉内容的模态,包括具有语义理解的图像生成、具有动态时间理解的视频生成、具有增强空间理解的3D内容生成[10]、[11]、[12]以及具有更复杂和综合理解的4D内容[13]、[14]、[15]、[16]、[17]、[18]、[19]。这些进展突显了生成学习在日益复杂的视觉任务中的巨大潜力。在这些不同的视觉模态中,视频生成最近在生成学习领域获得了显著关注,它为扩展大型生成模型处理更高维数据提供了一个更加具有挑战性的试验平台。这一复杂性不仅源于单个帧的空间复杂性,还来自于跨序列所需的时间一致性。许多商业视频生成模型已被开发并引起了广泛的公众关注,如OpenAI的Sora [20]、Google的Veo2 [21]、腾讯的Hunyuan [22]和快手的Kling [23]。视频生成已在多种形式和设置中得到深入研究,从最基本的无条件生成[24]、[25]到图像到视频生成[26]、[27]、[28]、[29]、[30]、[31]、[32]、[33]、文本到视频生成[24]、[25]、[26]、[29]、[30]、[30]、[34]、[35]、[36]、[37]、视频到视频生成[38]、[39]、以及视频编辑或定制[40]、[41]、[42]、[43]。这些设置各自解决了独特的挑战,从保持时间连续性到结合来自文本或视觉输入的语义引导。更重要的是,视频在生成AI视觉的未来中占据了关键地位。互联网上可用的大量视频数据封装了关于现实世界的丰富信息,使视频成为生成AI可以学习建模复杂现实世界现象的媒介。在这个背景下,视频可以被视为现实世界决策的“语言”,具有弥合数字和物理领域的潜力[44]。视频生成有望提供一个统一的接口作为“世界模型”[45],处理物理知识,类似于文本大语言模型(LLM)处理抽象知识的方式。这种模型可以促进大量下游任务的执行,包括自动驾驶、科学仿真、机器人[46]、[47]、[48]、[49]、[50]以及其他形式的具身智能。为了实现这一潜力,生成过程应能够与人类或其他系统的外部控制进行交互。这种互动性促进了动态决策制定和基于互动优化结果的能力,催生了可以描述为生成交互环境的概念[44]、[51]、[52]、[53]。视频生成已经与多种交互控制信号相结合,如运动向量或轨迹[54]、[55]、[56]、[57]、[58]、手部掩码[59]、潜在动作[53]、[60]、机器人操作[47]、相机运动[61]、演示[62]和自然语言描述[63]、[64]、[65]。这些互动元素突显了生成视频模型的多功能性和适应性,为其演变为世界模型铺平了道路。然而,从生成到稳健世界建模的过渡仍然存在一个关键差距:真实世界物理的忠实理解和复制能力[66](见图1)。当前的最先进模型主要针对像素空间中的视觉真实感进行优化,而非在实体或概念空间中的物理合理性。为了使生成模型能够作为物理世界的模拟器,它们必须融入对物理法则的深刻理解,如动力学、因果关系和材料属性。这种物理意识对于超越仅生成视觉上吸引人的输出至关重要,以确保内容与物理世界的约束和行为一致。因此,我们提供本综述,作为对现有文献的及时而全面的回顾,旨在将物理感知嵌入生成模型。通过审视这些努力,我们希望突出至今所取得的进展,提供清晰的范式结构,并识别未来的潜在研究方向。综述范围:本综述的范围是关于增强生成输出物理感知的计算机视觉生成模型。因此,我们不包括将物理原理作为先验知识或归纳偏置融入模型或神经架构设计的文献,例如物理信息神经网络(PINN)[67]、[68],即使任务与生成学习相关,例如[69]、[70]、[71]。我们专注于生成任务,因此不包括图像处理任务,如去模糊、去雾和增强,尽管我们注意到这些工作中有大量的物理相关内容。为了专注于计算机视觉,我们还排除了纯图形和渲染研究与物理仿真相结合的文献。与其他综述的比较:如同在我们的范围中所述,本综述与现有的关于物理信息机器学习[72]、物理信息计算机视觉[73]和物理信息人工智能[74]的综述不同,因为它们强调的是在物理先验知识下的模型设计方面。我们的综述专注于具有物理感知的生成,因此与现有的关于生成模型[75]、扩散模型[76]、[77]、视频扩散模型[78]、基于扩散的视频编辑[79]的综述有所不同。与专注于特定领域的综述,如人类视频或运动生成[80]、[81]、[82]相比,我们的综述也有不同的范围。
1 引言生成学习一直是现代计算机视觉的基础支柱,解决了理解、合成和操作视觉数据中的关键挑战。在过去的十年里,该领域见证了多种生成模型的快速发展,包括变分自编码器(VAE)[1]、生成对抗网络(GAN)[3]、扩散模型(DM)[4]、[5]、[6]、神经辐射场(NeRF)[7]、高斯溅射(GS)[8] 和视觉自回归模型(VAR)[9]。这些模型不断推动生成学习的边界,利用越来越强大的架构来捕捉视觉数据的潜在分布。其目标是使机器能够以类似人类的创造性和理解方式推理视觉世界,通过在未见过的场景中想象新的视觉内容实例。在这些进展中,扩散模型因其能够生成高度逼真的输出而成为特别值得注意的技术。通过通过学习到的去噪过程迭代地精炼随机噪声,扩散模型展现出卓越的鲁棒性和多功能性,成为近期生成方法学的基石。生成模型的应用跨越了多种视觉内容的模态,包括具有语义理解的图像生成、具有动态时间理解的视频生成、具有增强空间理解的3D内容生成[10]、[11]、[12]以及具有更复杂和综合理解的4D内容[13]、[14]、[15]、[16]、[17]、[18]、[19]。这些进展突显了生成学习在日益复杂的视觉任务中的巨大潜力。在这些不同的视觉模态中,视频生成最近在生成学习领域获得了显著关注,它为扩展大型生成模型处理更高维数据提供了一个更加具有挑战性的试验平台。这一复杂性不仅源于单个帧的空间复杂性,还来自于跨序列所需的时间一致性。许多商业视频生成模型已被开发并引起了广泛的公众关注,如OpenAI的Sora [20]、Google的Veo2 [21]、腾讯的Hunyuan [22]和快手的Kling [23]。视频生成已在多种形式和设置中得到深入研究,从最基本的无条件生成[24]、[25]到图像到视频生成[26]、[27]、[28]、[29]、[30]、[31]、[32]、[33]、文本到视频生成[24]、[25]、[26]、[29]、[30]、[30]、[34]、[35]、[36]、[37]、视频到视频生成[38]、[39]、以及视频编辑或定制[40]、[41]、[42]、[43]。这些设置各自解决了独特的挑战,从保持时间连续性到结合来自文本或视觉输入的语义引导。更重要的是,视频在生成AI视觉的未来中占据了关键地位。互联网上可用的大量视频数据封装了关于现实世界的丰富信息,使视频成为生成AI可以学习建模复杂现实世界现象的媒介。在这个背景下,视频可以被视为现实世界决策的“语言”,具有弥合数字和物理领域的潜力[44]。视频生成有望提供一个统一的接口作为“世界模型”[45],处理物理知识,类似于文本大语言模型(LLM)处理抽象知识的方式。这种模型可以促进大量下游任务的执行,包括自动驾驶、科学仿真、机器人[46]、[47]、[48]、[49]、[50]以及其他形式的具身智能。为了实现这一潜力,生成过程应能够与人类或其他系统的外部控制进行交互。这种互动性促进了动态决策制定和基于互动优化结果的能力,催生了可以描述为生成交互环境的概念[44]、[51]、[52]、[53]。视频生成已经与多种交互控制信号相结合,如运动向量或轨迹[54]、[55]、[56]、[57]、[58]、手部掩码[59]、潜在动作[53]、[60]、机器人操作[47]、相机运动[61]、演示[62]和自然语言描述[63]、[64]、[65]。这些互动元素突显了生成视频模型的多功能性和适应性,为其演变为世界模型铺平了道路。然而,从生成到稳健世界建模的过渡仍然存在一个关键差距:真实世界物理的忠实理解和复制能力[66](见图1)。当前的最先进模型主要针对像素空间中的视觉真实感进行优化,而非在实体或概念空间中的物理合理性。为了使生成模型能够作为物理世界的模拟器,它们必须融入对物理法则的深刻理解,如动力学、因果关系和材料属性。这种物理意识对于超越仅生成视觉上吸引人的输出至关重要,以确保内容与物理世界的约束和行为一致。因此,我们提供本综述,作为对现有文献的及时而全面的回顾,旨在将物理感知嵌入生成模型。通过审视这些努力,我们希望突出至今所取得的进展,提供清晰的范式结构,并识别未来的潜在研究方向。综述范围:本综述的范围是关于增强生成输出物理感知的计算机视觉生成模型。因此,我们不包括将物理原理作为先验知识或归纳偏置融入模型或神经架构设计的文献,例如物理信息神经网络(PINN)[67]、[68],即使任务与生成学习相关,例如[69]、[70]、[71]。我们专注于生成任务,因此不包括图像处理任务,如去模糊、去雾和增强,尽管我们注意到这些工作中有大量的物理相关内容。为了专注于计算机视觉,我们还排除了纯图形和渲染研究与物理仿真相结合的文献。与其他综述的比较:如同在我们的范围中所述,本综述与现有的关于物理信息机器学习[72]、物理信息计算机视觉[73]和物理信息人工智能[74]的综述不同,因为它们强调的是在物理先验知识下的模型设计方面。我们的综述专注于具有物理感知的生成,因此与现有的关于生成模型[75]、扩散模型[76]、[77]、视频扩散模型[78]、基于扩散的视频编辑[79]的综述有所不同。与专注于特定领域的综述,如人类视频或运动生成[80]、[81]、[82]相比,我们的综述也有不同的范围。
![]()