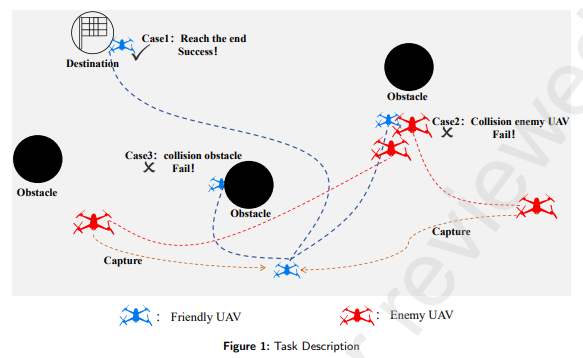
随着无人机(UAV)技术应用日益广泛,如何在不确定性环境中实现高效安全的自主导航成为重要研究课题。本文针对动态不确定环境中的无人机路径规划问题,构建了空域场景下执行任务的仿真环境。该环境支持灵活参数配置,可调整障碍物数量、敌方无人机数量及其行为策略(如"随机巡逻"或"追击")。将无人机路径规划问题建模为部分可观测马尔可夫决策过程(POMDP),充分考虑无人机运动模型与环境特征,据此设计相关状态空间、动作空间及奖励函数。进一步提出融合快速扩展随机树(RRT)算法与柔性行动者-评价者(SAC)算法的新型RRT-SAC算法:RRT负责全局路径规划为无人机提供导航指引,SAC专注局部动作选择以应对动态环境中的突发状况。实验结果表明,在多组测试环境中RRT-SAC算法在任务完成率、耗时、轨迹长度等指标上均优于对比算法,展现出卓越的泛化能力与稳定性。
无人机(UAV)在现代社会的应用日趋广泛。其灵活性、高效性和多功能性使其成为解决传统方法难以应对挑战的关键工具(Fraga-Lamas等,2019)。在农业领域,无人机可实现作物生长精准监测(Wang等,2019);环境管理领域则可采集空气质量与水污染数据支撑现代环境监测(Valenti等,2016)。随着智能决策与航空设备性能的飞速发展,无人机在灾害救援与军事领域亦获广泛应用(Bai等,2021)。更智能化、信息化的无人机可快速抵达指定区域执行搜救、物资投送等任务,大幅降低人力资源成本(Valente等,2013)。但无论何种任务类型,自主路径规划始终是完成无人机任务的核心要素。高效路径规划可优化飞行轨迹并最小化能耗,智能避障策略则能保障无人机在复杂环境中的安全运行,从而降低事故风险(Dewangan等,2019)。
路径规划算法主要分为两类:非学习型方法与学习型方法。非学习型方法主要基于预定义规则和数学模型进行搜索或采样。其中搜索类算法(如Dijkstra算法)通过正向遍历所有节点获取最优路径(Dijkstra,2022);A*算法改进Dijkstra算法,利用启发函数缩小搜索范围提升效率(Dewangan等,2019)。快速扩展随机树(RRT)作为采样类算法,通过在状态空间随机采样点自然处理运动学约束,为实际应用提供高效可靠方案(Fan等,2022)。然而由于路径规划属于经典NP难问题,传统建模与搜索算法在复杂环境中计算复杂度急剧增加,有时甚至无法求得解,该现象常称为"维度灾难"(Dewangan等,2019)。
为规避维度灾难,学习型方法应用日益广泛。强化学习(RL)采用试错训练机制,无需人类知识或预设规则,通过探索能获取最大回报的行为使智能体达到类人高级智能水平(Li等,2023)。经典RL算法(如SARSA与Q-learning)已成为无人机路径规划的重要方法(Liu和Lu,2013)。尤其2013年提出融合深度学习的深度Q网络(DQN)算法,解决了强化学习中高维状态空间表征难题(Mnih等,2013)。DQN在雅达利游戏中的表现远超既有机器学习方法。2015年改进版DQN在雅达利游戏中显著超越人类专业玩家(Mnih等,2015)。越来越多研究者开始初步应用深度强化学习(DRL)算法进行无人机任务模拟与规划。此类算法融合强化学习的决策能力与深度学习的感知能力,为动态路径规划问题提供新解法(HUANG等,2024)。Keong构建空战博弈环境,采用DQN实现无人机自主避障与射击策略(Keong等,2019);Xu改进DQN提出D3Q方法有效缓解估值过高问题(Xu等,2024);Yu提出带安全约束的RL路径规划算法,在保障路线安全同时兼顾任务完成率(Yu等,2021)。但仿真环境与现实存在显著差异:DQN本质上仅能输出离散动作,难以实际部署。而深度确定性策略梯度(DDPG)算法的提出使DRL可输出连续动作,在现实动态环境中展现强大探索能力(Hou等,2017)。Lan应用DDPG算法实现多移动机器人在未知环境的避障任务,并成功应用于大规模现实场景(Lan等,2022);Hadi基于DDPG采用双延迟DDPG(TD3)算法解决自主水下机器人运动规划与避障技术(Hadi等,2022);柔性行动者-评价者(SAC)在DDPG基础上将策略熵纳入优化目标以激励探索,赋予算法在复杂动态路径规划场景中更强的适应性(Zhao等,2024)。
但当环境发生剧变时,上述算法常存在泛化能力不足问题。例如军事对抗场景中,敌方单位可能突变为更高级智能体,被视为动态障碍的敌机可能突然开始追击我方无人机。此时在原环境训练的算法往往失效(Zhang等,2022)。为应对此类剧变环境,Fu采用课程学习(CL)方法(Xiaowei等,2022):将敌机策略制定划分为随机游走、线性追击、转向追击三阶段,逐步提升追击方智能水平并渐进训练逃脱方策略。但CL方法仍需大量样本收敛,实际无人机系统通过物理实验获取样本的成本极高,制约了算法应用;且CL策略演进仅覆盖有限模式。为提升样本效率并增强无人机泛化能力,本文提出融合RRT-SAC算法:规划前由RRT执行全局搜索提供航向指引,SAC负责局部动作选择应对动态环境突发状况,二者通过动态加权混合策略集成。相比既有工作,本文主要贡献如下:
• 开发模拟我方无人机与敌机对抗的空域场景。该环境可灵活配置障碍物数量、敌方无人机数量及其行为策略(如"随机游走"或"追击")。不仅可作为无人机强化学习训练环境,更具强迁移性,可扩展至自动驾驶车辆或地面机器人应用。例如自动驾驶车辆可通过类似方法训练预测邻近来车路径并优化自身驾驶策略。
• 融合传统路径规划算法与DRL算法,有效解决SAC算法在追击场景的收敛问题。每次动作执行前,根据当前状态分别计算RRT与SAC动作,通过距离指标动态确定归一化权重选择最终动作。此举既保障动作遵循全局路径,又能灵活避障。
• 将无人机路径规划问题建模为部分可观测马尔可夫决策过程(POMDP),采用所提RRT-SAC算法求解。实验结果验证了算法的有效性与优越性。