

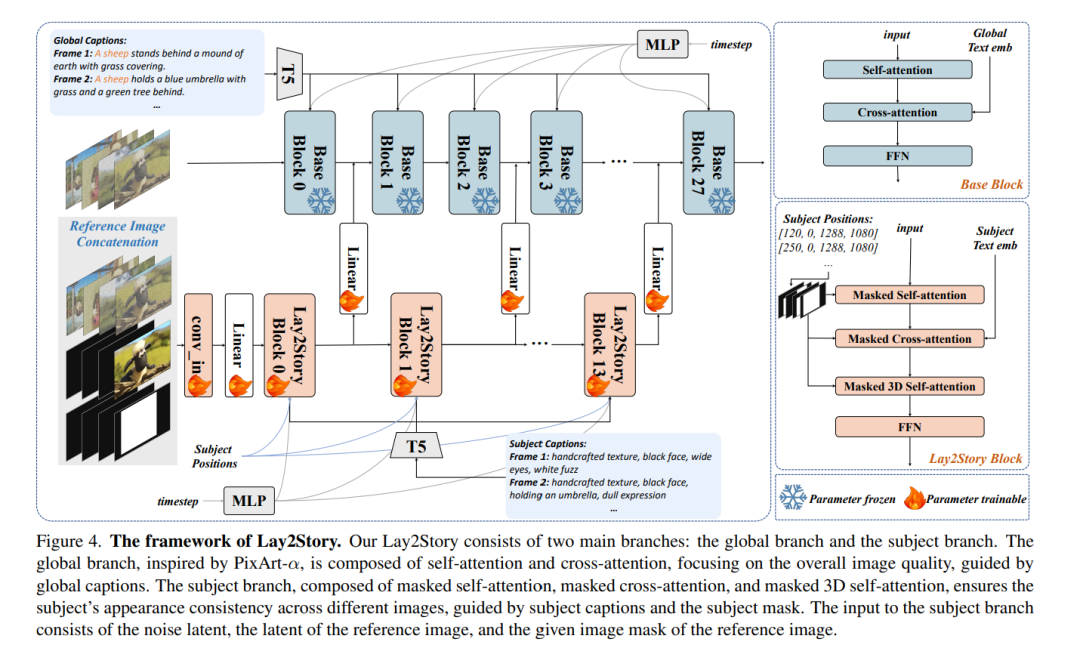
近年来,涉及生成具有一致主体(consistent subjects)的故事生成任务引起了广泛关注。然而,现有方法——无论是免训练(training-free)还是基于训练(training-based)——由于缺乏细粒度的引导与帧间交互,仍然难以保持主体一致性。此外,该领域高质量数据的稀缺,使得在故事生成任务中精确控制主体的位置、外观、服装、表情和姿态变得困难,从而阻碍了进一步发展。 在本文中,我们证明了布局条件(layout conditions)——例如主体的位置与细节属性——能够有效促进帧与帧之间的细粒度交互。这不仅增强了生成帧序列的一致性,还能够精确控制主体的位置、外观以及其他关键细节。基于这一观察,我们引入了一项更高级的故事生成任务:可切换布局的故事生成(Layout-Togglable Storytelling),该任务通过引入布局条件来实现对主体的精确控制。 为了解决此任务缺乏带有布局标注的高质量数据集的问题,我们构建了 Lay2Story-1M,该数据集包含超过 100 万张分辨率为 720p 及以上的图像,这些图像来源于约 11,300 小时的卡通视频并经过处理。在 Lay2Story-1M 的基础上,我们进一步创建了 Lay2Story-Bench,一个包含 3,000 条提示词(prompt)的基准测试集,用于评估不同方法在该任务上的表现。 此外,我们提出了 Lay2Story,这是一个基于 Diffusion Transformers (DiTs) 架构、面向可切换布局故事生成任务的鲁棒框架。通过定性与定量实验,我们发现该方法在一致性、语义相关性以及美学质量方面均优于先前的最新技术(state-of-the-art, SOTA),取得了最佳结果。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日


相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日