

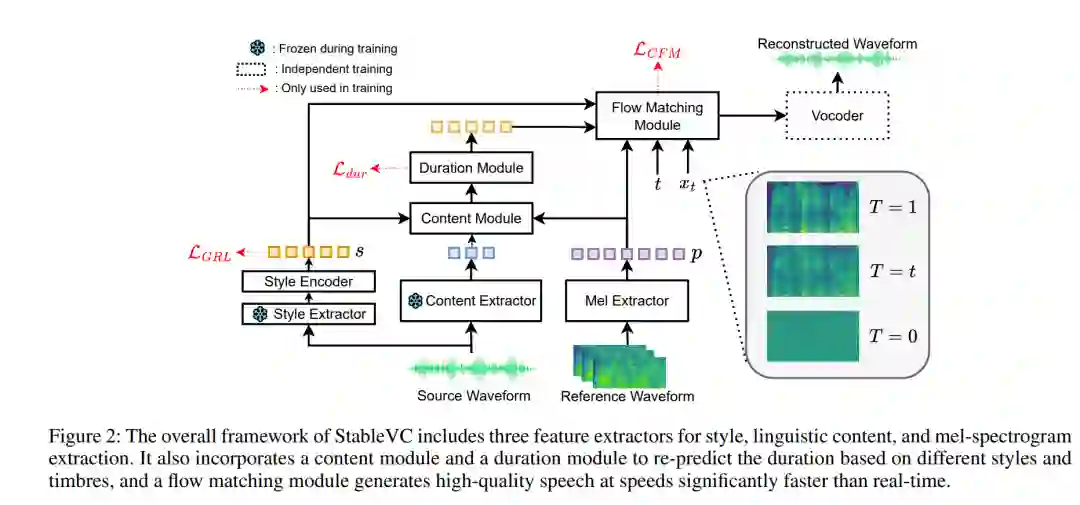
零-shot语音转换(VC)旨在将源说话人的音色转换为任意未见说话人的音色,同时保持原始的语言内容。尽管基于语言模型或扩散方法的零-shot VC在最近取得了一些进展,但仍然面临一些挑战:1)当前的方法主要集中在适应未见说话人的音色,无法独立地将风格和音色转换为不同的未见说话人;2)这些方法通常由于自回归建模方法或需要多个采样步骤,导致推理速度较慢;3)转换样本的质量和相似度仍然未能完全令人满意。为了解决这些挑战,我们提出了一种名为StableVC的风格可控零-shot VC方法,旨在将音色和风格从源语音转换到不同的未见目标说话人。具体来说,我们将语音分解为语言内容、音色和风格,然后采用条件流匹配模块,根据这些分解的特征重建高质量的梅尔频谱图。为了有效地以零-shot的方式捕捉音色和风格,我们引入了一种新颖的双重注意机制,配合自适应门控,而不是使用传统的特征拼接。凭借这种非自回归设计,StableVC能够高效地捕捉来自不同未见说话人的复杂音色和风格,并以显著高于实时的速度生成高质量的语音。实验表明,我们提出的StableVC在零-shot VC任务中优于最先进的基准系统,并在不同未见说话人的音色和风格控制方面具有灵活性。此外,与自回归和基于扩散的基准方法相比,StableVC的采样速度提高了约25倍和1.65倍。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
225+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
225+阅读 · 2023年4月7日