【Flink】基于 Flink 的流式数据实时去重

在实时计算 PV 信息时,用户短时间内重复点击并不会增加点击次数,基于此需求,我们需要对流式数据进行实时去重。
一想到大数据去重,我们立刻可以想到布隆过滤器、HyperLogLog 去重、Bitmap 去重等方法。对于实时数据处理引擎 Flink 来说,除了上述方法外还可以通过 Flink SQL 方式或 Flink 状态管理的方式进行去重。
本文主要介绍基于 Flink 状态管理的方式进行实时去重。
1.状态管理
虽然 Flink 的很多操作都是基于事件解析器进行一次的事件处理,但也有很多操作需要记住多个事件的信息,比如窗口运算等。这些操作便称为有状态的操作。
有状态的操作有一些经典案例,比如说:
-
计算每分钟/小时/天的统计量等; -
实时计算 PV、UV,需要维护目前已有的 PV、UV 信息; -
实时更新机器学习模型,需要记住模型的参数;
我们在上一篇内容中介绍了如何计算分钟级的统计量,我们采用的方法是开一个窗口函数进行统计;而现在的任务是数据去重,对于增量数据来说没法进行开窗运算。
针对这种情况,Flink 提供了基于事件驱动的处理函数(ProcessFunction),其将事件处理与 Timer、State 结合在一起,提供了更加强大和丰富的功能。
Flink 子任务状态更新和获取的流程如下图所示,一个算子子任务接收输入流,获取对应的状态,根据新的计算结果更新状态。
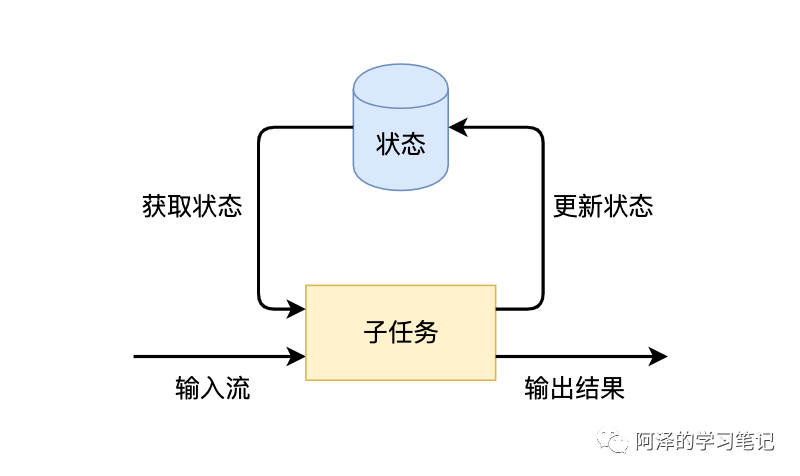
获取和更新状态的逻辑其实并不复杂,但流处理框架还需要解决以下几类问题:
-
数据的产出要保证实时性,延迟不能太高; -
需要保证数据不丢不重,恰好计算一次,尤其是当状态数据非常大或者应用出现故障需要恢复时,要保证状态的计算不出任何错误; -
一般流处理任务都是 7*24 小时运行的,程序的可靠性需要非常高。
基于上述要求,我们不能将状态仅交由内存管理,因为内存的容量是有限制的,当状态数据稍微大一些时,就会出现内存不够的问题。由于 Flink 本身提供了有状态的计算,并且封装了一些底层的实现,比如状态的高效存储、Checkpoint 和 Savepoint 持久化备份机制、计算资源扩缩容等问题,所以我们只需要调用 Flink API,专注于业务逻辑即可。
2.状态类型
Managed State 和 Raw State
Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(Raw State)。从名称中也能读出两者的区别:Managed State 是由 Flink 管理的,Flink 帮忙存储、恢复和优化,Raw State 是开发者自己管理的,需要自己序列化。两者对比如下:
| Managed State | Raw State | |
|---|---|---|
| 状态管理方式 | Flink Runtime 托管,自动存储、自动恢复、自动伸缩 | 用户自己管理 |
| 状态数据结构 | Flink提供的常用数据结构,如 ListState、MapState 等 | 字节数组:byte[] |
| 使用场景 | 绝大多数 Flink 算子 | 用户自定义算子 |
大部分情况下我们使用 Managed State 便可满足需求。
Keyed State 和 Operator State
我们对 Managed State 继续细分,它又有两种类型:Keyed State 和 Operator State。
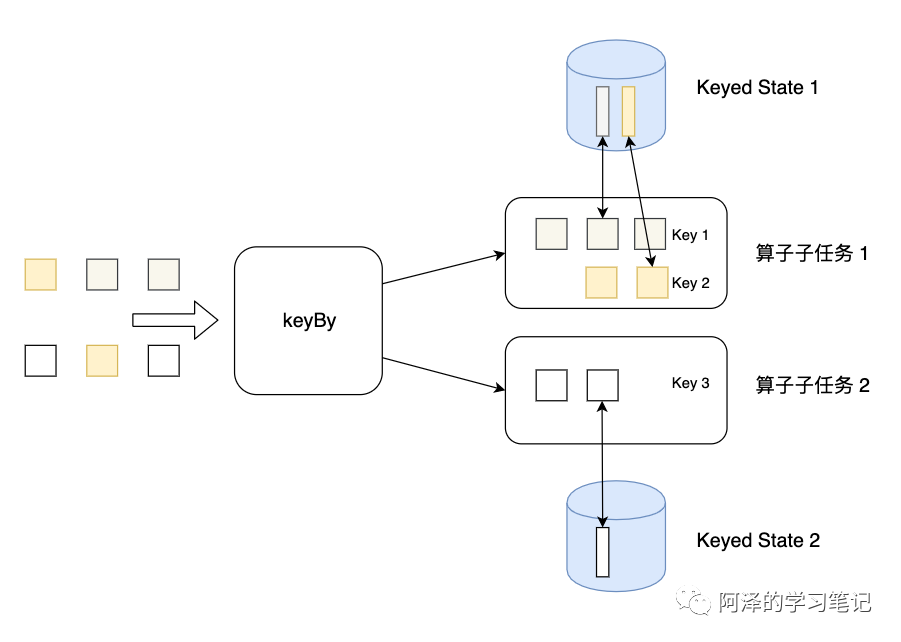
Keyed State 是 KeyedStream 上的状态。假如输入流按照 id 为 Key 进行了 keyBy 分组,形成一个 KeyedStream。下图为 Keyed State,因为一个算子子任务可以处理一到多个Key,算子子任务 1 处理了两种 Key,两种 Key 分别对应自己的状态。
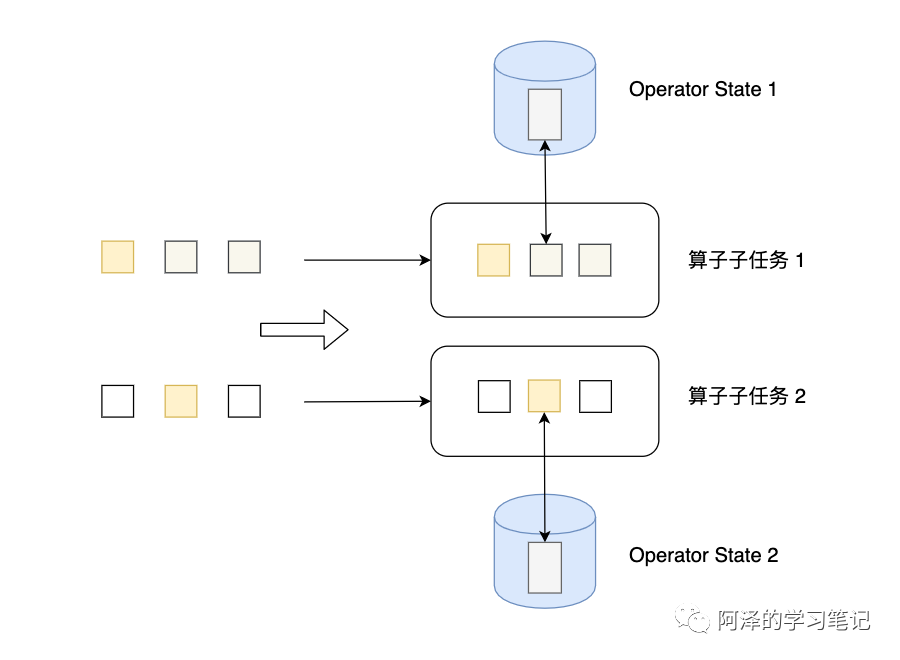
Operator State 可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。下图为 Operator State。
下图为两者的区别:
| Keyed State | Operator State | |
|---|---|---|
| 适用算子类型 | 只适用于KeyedStream上的算子 |
可以用于所有算子 |
| 状态分配 | 每个 Key 对应一个状态 | 一个算子子任务对应一个状态 |
| 创建和访问方式 | 重写 Rich Function 通过里面的 RuntimeContext 访问 | 实现 CheckpointedFunction 等接口 |
| 支持的数据结构 | ValueState、ListState、MapState 等 | ListState、BroadcastState 等 |
无论是 Keyed State 还是 Operator State,Flink 的状态都是基于本地的,即每个算子子任务维护着这个算子子任务对应的状态存储,算子子任务之间的状态不能相互访问。
3.代码实践
3.1 数据准备
准备一些数据 demo,数据格式和之前的一样,依次为 user、item、catelog、behavior、timestamp。
其中第一个数据和最后一行数据视为重复数据(两次点击间隔一秒)。
952483,310884,4580532,pv,1511712000
794777,5119439,982926,pv,1511712000
875914,4484065,1320293,pv,1511712000
980877,5097906,149192,pv,1511712000
944074,2348702,3002561,pv,1511712000
973127,1132597,4181361,pv,1511712000
84681,3505100,2465336,pv,1511712000
732136,3815446,2342116,pv,1511712000
940143,2157435,1013319,pv,1511712000
655789,4945338,4145813,pv,1511712000
952483,310884,4580532,pv,1511713000
##3.2 数据源
package com.aze.producer;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.io.BufferedReader;
import java.io.FileReader;
/**
* @Author: aze
* @Date: 2020-09-16 14:41
*/
public class ReadLineSource implements SourceFunction<String> {
private String filePath;
private boolean canceled = false;
public ReadLineSource(String filePath){
this.filePath = filePath;
}
@Override
public void run(SourceContext<String> sourceContext) throws Exception {
BufferedReader reader = new BufferedReader(new FileReader(filePath));
while (!canceled && reader.ready()){
String line = reader.readLine();
sourceContext.collect(line);
Thread.sleep(10);
}
}
@Override
public void cancel() {
canceled = true;
}
}
3.3 主程序
为了增加可读性,主程序介绍时不采用链式编程,后面放出完整程序时会采用链式编程。
3.3.1 创建环境
val env = StreamExecutionEnvironment.getExecutionEnvironment();
// 注意设置 EventTime,而不是默认的 ProcessTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
3.3.2 数据接入及清洗
这里用 lombok 包的 val 进行修饰,这样便不必编写实际类型。
我们利用 flatMap 清洗掉出了 "pv" 外的其他用户行为,并传出 Tuple2<String, Long> 类型。String 为 key,Long 为 timestamp。
val dataStream = env.addSource(new ReadLineSource("src/main/resources/data.txt"))
// 注意 FlatMapFunction 不要写成 Lambda 表达式
// 我们使用了泛型,所以没有显式地指明返回值的类型的话会出错
.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Long>> out) {
String[] split = s.split(",");
if ("pv".equals(split[3])) {
val res = new Tuple2<>(split[0] + "-" + split[1], Long.parseLong(split[4]));
out.collect(res);
}
}
});
3.3.3 定义事件时间
val process = dataStream.assignTimestampsAndWatermarks(WatermarkStrategy
.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofMillis(1000))
.withTimestampAssigner((SerializableTimestampAssigner<Tuple2<String, Long>>)
(s, l) -> s.f1));
我们为 flatMap 传出的 Tuple2<String, Long> 类型的数据定义一下时间时间。
3.3.4 定义内部类
为了方便处理,我们定义个内部类方便进行状态存储。
同样我们也引用了 lombok 为类添加注解(减少代码量)。
@Data
@ToString
@AllArgsConstructor
private static class UserBehavior {
private String id;
private long timestamp;
}
3.3.5 事件处理
通过注释的形式讲解下这段代码
// 基于 key 进行分流
process.keyBy(s -> s.f0)
// 每一个 key 都会维护一个 KeyedProcessFunction
.process(new KeyedProcessFunction<String, Tuple2<String, Long>, Object>() {
// 为每个 key 创建一个私有的状态
private ValueState<UserBehavior> state;
// KeyedProcessFunction 创建时会调用 open 方法
@Override
public void open(Configuration parameters) {
// 创建一个状态描述器
val stateDescriptor = new ValueStateDescriptor<>("mystate", UserBehavior.class);
// 设置状态的生存时间,过时销毁,主要是为减少内存
stateDescriptor.enableTimeToLive(StateTtlConfig.newBuilder(Time.seconds(60)).build());
// 完成 Keyed State 的创建。
state = getRuntimeContext().getState(stateDescriptor);
}
// 处理事件
@Override
public void processElement(Tuple2<String, Long> in,
Context ctx,
Collector<Object> out) throws Exception {
// 从状态中拿出对象
UserBehavior cur = state.value();
// 如果为空则为新数据,否则就是重复数据
if (cur == null) {
cur = new UserBehavior(in.f0, in.f1);
// 记得更新下状态
state.update(cur);
// 注册个定时器任务,60 秒后可以不算是新数据
// 即用户 60 秒点击多次只能算一次有效点击
ctx.timerService().registerEventTimeTimer(cur.getTimestamp() + 60000);
// 新数据可以向下传递
out.collect(cur);
} else {
// 打印一下
System.out.println("[Duplicate Data] " + in.f0 + " " + in.f1);
}
}
// 触发定时任务
@Override
public void onTimer(long timestamp,
OnTimerContext ctx,
Collector<Object> out) throws Exception {
UserBehavior cur = state.value();
// 利用定时任务将状态清空
if (cur.getTimestamp() + 60000 <= timestamp) {
System.out.printf("[Overdue] now: %d obj_time: %d Date: %s%n",
timestamp, cur.getTimestamp(), cur.getId());
state.clear();
}
}
})
.print();
注意,我这里用的是 ValueState,如果想要更好的性能,可以使用 MapState。
3.3.6 执行
env.execute("flink");
输出为:
DataDeduplicate.UserBehavior(id=952483-310884, timestamp=1511712000)
DataDeduplicate.UserBehavior(id=794777-5119439, timestamp=1511712000)
DataDeduplicate.UserBehavior(id=875914-4484065, timestamp=1511712000)
DataDeduplicate.UserBehavior(id=980877-5097906, timestamp=1511712000)
DataDeduplicate.UserBehavior(id=944074-2348702, timestamp=1511712000)
DataDeduplicate.UserBehavior(id=973127-1132597, timestamp=1511712000)
DataDeduplicate.UserBehavior(id=84681-3505100, timestamp=1511712000)
DataDeduplicate.UserBehavior(id=732136-3815446, timestamp=1511712000)
DataDeduplicate.UserBehavior(id=940143-2157435, timestamp=1511712000)
DataDeduplicate.UserBehavior(id=655789-4945338, timestamp=1511712000)
[Duplicate Data] 952483-310884 1511713000
[Overdue] now: 1511772000 obj_time: 1511712000 Date: 952483-310884
[Overdue] now: 1511772000 obj_time: 1511712000 Date: 655789-4945338
[Overdue] now: 1511772000 obj_time: 1511712000 Date: 940143-2157435
[Overdue] now: 1511772000 obj_time: 1511712000 Date: 732136-3815446
[Overdue] now: 1511772000 obj_time: 1511712000 Date: 84681-3505100
[Overdue] now: 1511772000 obj_time: 1511712000 Date: 973127-1132597
[Overdue] now: 1511772000 obj_time: 1511712000 Date: 944074-2348702
[Overdue] now: 1511772000 obj_time: 1511712000 Date: 980877-5097906
[Overdue] now: 1511772000 obj_time: 1511712000 Date: 875914-4484065
[Overdue] now: 1511772000 obj_time: 1511712000 Date: 794777-5119439
可以看到,碰到最后一条数据是提示了为重复数据。
后面定时器也全部触发了,大概率是因为触发水印。。。
3.4 完整程序
放上完整程序。
package com.aze.consumer;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.ToString;
import lombok.val;
import com.aze.producer.ReadLineSource;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.time.Duration;
/**
* @Author: aze
* @Date: 2020-09-16 14:45
*/
public class DataDeduplicate {
public static void main(String[] args) throws Exception {
val env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
val dataStream = env.addSource(new ReadLineSource("src/main/resources/data.txt"));
val process = dataStream
.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Long>> out) throws Exception {
String[] split = s.split(",");
if ("pv".equals(split[3])) {
val res = new Tuple2<>(split[0] + "-" + split[1], Long.parseLong(split[4]));
out.collect(res);
}
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy
.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofMillis(1000))
.withTimestampAssigner((SerializableTimestampAssigner<Tuple2<String, Long>>)
(s, l) -> s.f1))
.keyBy(s -> s.f0)
.process(new KeyedProcessFunction<String, Tuple2<String, Long>, Object>() {
private ValueState<UserBehavior> state;
@Override
public void open(Configuration parameters) {
val stateDescriptor = new ValueStateDescriptor<>("mystate", UserBehavior.class);
stateDescriptor.enableTimeToLive(StateTtlConfig.newBuilder(Time.seconds(60)).build());
state = getRuntimeContext().getState(stateDescriptor);
}
@Override
public void processElement(Tuple2<String, Long> in,
Context ctx,
Collector<Object> out) throws Exception {
UserBehavior cur = state.value();
if (cur == null) {
cur = new UserBehavior(in.f0, in.f1);
state.update(cur);
ctx.timerService().registerEventTimeTimer(cur.getTimestamp() + 60000);
out.collect(cur);
} else {
System.out.println("[Duplicate Data] " + in.f0 + " " + in.f1);
}
}
@Override
public void onTimer(long timestamp,
OnTimerContext ctx,
Collector<Object> out) throws Exception {
UserBehavior cur = state.value();
if (cur.getTimestamp() + 1000 <= timestamp) {
System.out.printf("[Overdue] now: %d obj_time: %d Date: %s%n",
timestamp, cur.getTimestamp(), cur.getId());
state.clear();
}
}
});
process.print();
env.execute("flink");
}
@Data
@ToString
@AllArgsConstructor
private static class UserBehavior {
private String id;
private long timestamp;
}
}
4.总结
以上便是基于 Flink 数据实时去重的所有情况,目前还只是单机处理,也不知道碰到大数据集会不会出现内存爆炸的情况。
5.参考
-
《Flink状态管理详解:Keyed State和Operator List State深度解析》 -
《有状态流处理》 -
《事件驱动应用》
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




