强化学习
·


在本文中,我们简要介绍了强化学习(RL),特别强调随机逼近(SA)作为一个统一的主题。本文的范围包括马尔科夫奖励过程,马尔科夫决策过程,随机逼近算法,以及广泛使用的算法,如时间差分学习和Q-学习。 https://arxiv.org/pdf/2304.00803.pdf
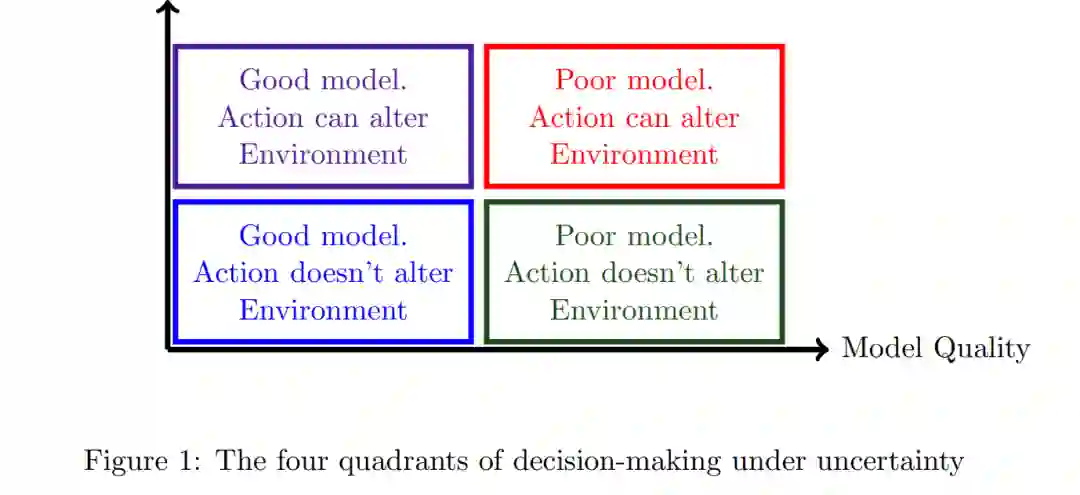
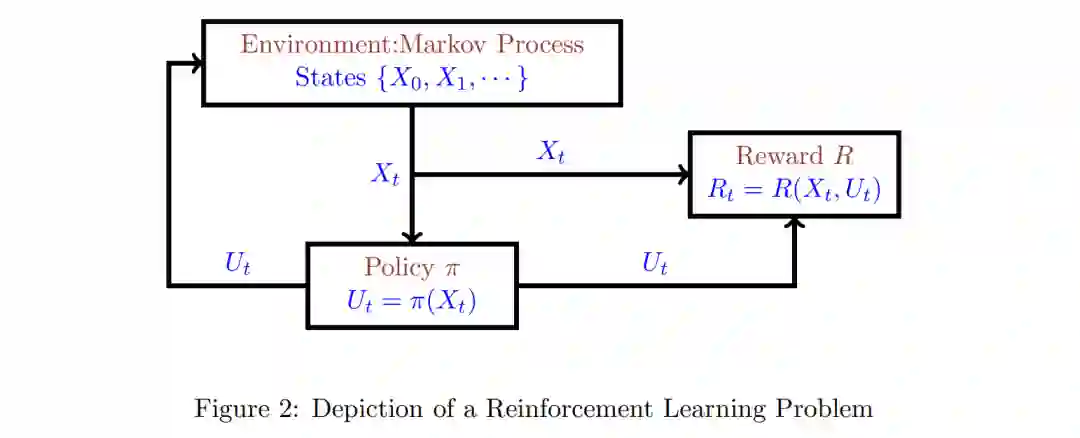
本文对强化学习(RL)进行了简要的综述,特别强调随机逼近(SA)作为一个统一的主题。本文的范围包括马尔可夫奖励过程、马尔可夫决策过程、随机近似方法以及时间差分学习和Q-learning等广泛使用的算法。强化学习是一个庞大的主题,这篇简短的综述几乎无法准确地描述这个主题。有一些关于RL的优秀文本,如[4,27,34,33]。[25, 22, 3, 23, 2, 9, 10]对随机近似(SA)算法的动力学进行了分析。有兴趣的读者可以查阅这些来源以获得更多信息。在本综述中,用"强化学习"一词来指具有不确定模型的决策,当前的行动会改变系统的未来行为。因此,如果在未来的某个时间采取相同的行动,结果可能就不一样了。这个额外的特征将强化学习与不确定性下的“单纯”决策区分开来。图1相当武断地将决策问题分为四个象限。现在对每个象限的例子作简要说明。

成为VIP会员查看完整内容
相关内容
Arxiv
10+阅读 · 2022年7月30日
Arxiv
12+阅读 · 2021年12月28日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2022年7月30日
Arxiv
12+阅读 · 2021年12月28日