【2022新书】算法高维鲁棒统计,296页pdf与98页ppt

鲁棒统计领域研究的一般问题是设计即使在数据显著偏离理想化建模假设的情况下也能表现良好的估计量。对鲁棒统计过程的系统研究可以追溯到20世纪60年代Tukey和Huber的开创性工作。经典统计理论对大多数常见问题的鲁棒估计的信息理论极限进行了表征。另一方面,直到最近,人们对这个领域的计算方面知之甚少。计算机科学最近的一项工作为一系列学习任务提供了第一个计算高效的高维鲁棒估计器。具体而言,2016年两项独立且并行的研究开发了第一个用于基本高维鲁棒统计任务的高效算法,包括均值和协方差估计。自这些著作的传播以来,人们对各种背景下的高维鲁棒估计算法进行了大量的研究。本书概述了算法高维鲁棒统计的最新发展。
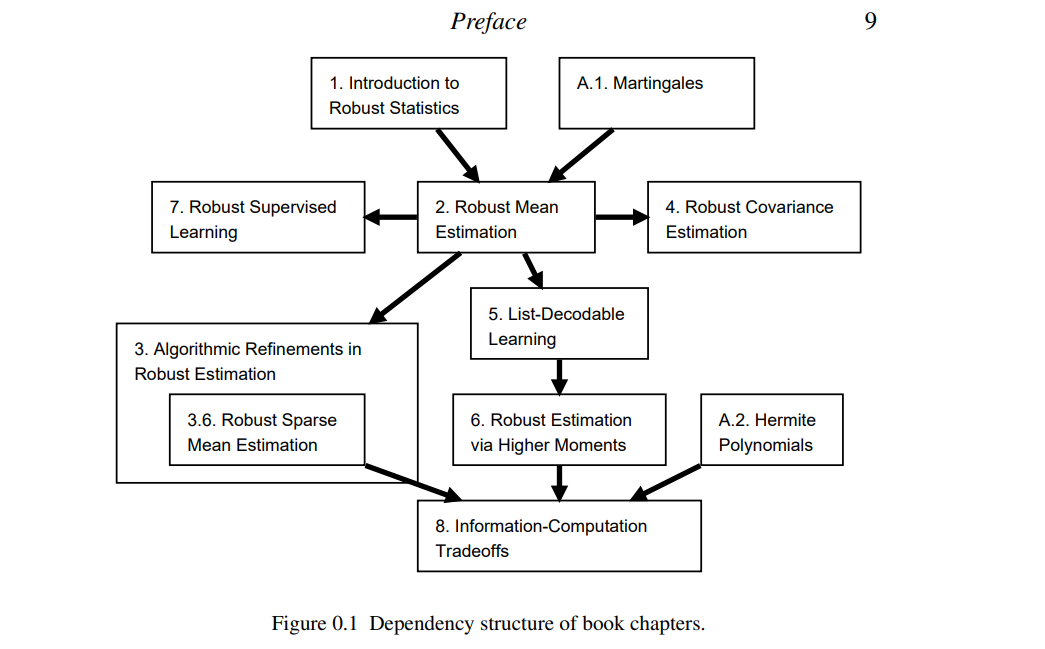
将一个模型与一组观察结果相匹配是统计学和机器学习中的典型问题之一。典型的假设是,数据是由给定类型的模型生成的(例如,混合模型)。这是一个简化的假设,仅近似有效,因为真实数据集通常暴露于某些污染源。因此,为特定模型设计的任何估计器在存在损坏/噪声数据时也必须是鲁棒的。经典的鲁棒统计研究,从20世纪60年代的Tukey和Huber的开创性工作开始,确定了高维鲁棒估计的基本信息理论方面。相比之下,直到最近,人们对计算方面的了解还很少。特别是,即使是对高维数据集均值的鲁棒估计这一基本问题,所有已知的鲁棒估计量都很难计算。此外,已知的启发式(如RANSAC)的准确性随着维数的增加呈多项式递减。这种情况自然引起了以下问题:
高维估计的鲁棒性和计算效率能否协调一致?
理论计算机科学的最近一行工作获得了第一个计算高效的鲁棒估计器,用于一系列高维估计任务。在本教程中,我们将研究这些估计器的算法技术以及它们之间的联系。我们将针对以下问题和设置说明这些技术:鲁棒均值和协方差估计、鲁棒随机优化、稀疏性假设下的鲁棒估计、列表可解码学习和混合模型、高阶矩的鲁棒估计、计算鲁棒权衡。最后,我们将讨论未来工作的新方向和机遇。




专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“M173” 就可以获取《【牛津大学博士论文】多模态概率推理的机器学习预测与协调,173页pdf》专知下载链接



