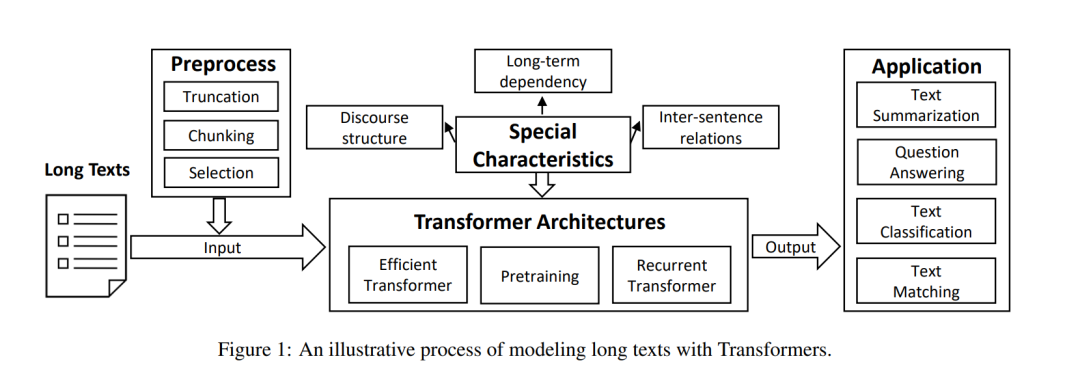
本综述的其余部分组织如下(见图1)。首先,我们在第2节中给出长文本建模的正式定义。为了对任意长度的长文本进行建模,本文介绍了第3节中处理PLM长度限制的预处理方法,以及第4节中有效扩展最大上下文大小同时保持计算效率的Transformer架构。由于长文本具有特殊的特性,我们将在第5节中解释如何设计模型架构以满足这些特性。随后,在第6节介绍了典型的应用。最后,对全文进行了总结,并在第7节提出了未来的研究方向。
**长文本建模 **首先,提供了长文本建模的正式定义。在本综述中,长文本表示为单词序列X = (x1,…, xn),与可以直接由Transformer处理的短文本或普通文本相比,它可能包含数千个或更多的标记。由于PLM的预定最大上下文长度,Transformer模型对整个长序列进行编码是具有挑战性的。因此,使用预处理函数g(·)将冗长的输入转换为较短的序列或片段集合(第3节)。此外,冗长的文档将包含在建模过程中必须考虑的特殊特征C,例如长期依存关系、句子间关系和篇章结构(第5节)。使用Transformer架构M从输入数据中捕获上下文信息,并建模从输入X到期望输出Y的语义映射关系(第4节)。基于这些概念,建模长文本的任务被形式化描述如下:
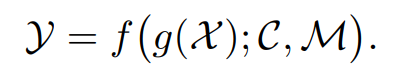
预处理输入长文本
现有的基于transformer的PLMs [Devlin等人,2018;Radford等人,2019;Lewis等人,2019]预定义了最大序列长度,例如,BERT只能处理多达512个token。根据第2节,当序列长度n超过最大上下文大小t时,使用预处理函数g(·)将输入文档转换为一个或多个短段(见公式1)。在本节中,我们介绍了三种主要的文本预处理技术,以规避plm的长度限制,即截断、分块和内容选择,如表1所示 * 文本截断(Truncating Long Texts):从头开始对输入文本进行截断到PLM最大长度,将截断后的文本送入PLM。 * 文本分块(Chunking Long Texts):将输入文本分成一个个文本块,其中每个文本块长度小于等于PLM最大长度。之后,每个文本块分别被PLM处理。 * 文本选择(Selecting Salient Texts):将输入文本分成一个个文本块,识别并连接其中重要的文本块成为新的输入序列。新的输入需要满足小于PLM最大长度并送往PLM进行处理。

用于长文本的Transformer架构
考虑到自注意力模块的二次复杂度,在计算资源有限的情况下,基于transformer的PLM在长文本中不能很好地扩展。本文没有对长文本进行预处理(第3节),而是讨论了Transformer模型的有效架构M(公式1),降低了复杂性。之前的研究广泛讨论了提高Transformer计算效率的各种方法[Tay等人,2022;Lin等,2022]。在这里,我们主要讨论可以有效扩展其最大上下文长度的变体。介绍了为长文本设计的transformer预训练目标和策略。 * 高效Transformer(Efficient Transformer):针对Transformer的自注意力机制进行改进降低复杂度。
固定模式(Fixed Attention Patterns):根据位置选择每个token可以交互的token子集。 * 可学习模式(Learnable Attention Patterns):根据输入的内容信息选择每个token可以交互的token子集。 * 注意力近似(Attention Approximation):对注意力机制进行近似改进,分为低秩近似和核近似。 * 高效编码器解码器注意力(Efficient Encoder-decoder Attention):对解码器和编码器之间的注意力机制降低复杂度。 * 循环Transformer(Recurrent Transformer):不改变自注意力机制,而是对输入进行分块,使用模型对当前以及存储的先前块的信息进行处理。 * 长文本预训练(Pretraining for Long Texts):针对长文本,设计更合适的预训练目标函数,使用长文本作为训练数据,并可以从现有的PLM开始继续训练。
长文本特殊性质(Special Characteristics of Long Text)
背景:之前两个章节的方法理论上足以处理长文本问题。但是,相比于普通的文本,长文本含有许多独特性质。利用这些独特性质,可以更好地对长文本进行建模。 * 长期依赖(Long-term Dependency):当前,许多方法关注局部细节信息的建模。然而,在长文本中,遥远的词之间可能存在依赖关系。
增强局部注意力:为了弥补高效Transformer中局部注意力的不足,增加模块捕捉长期依赖信息。 * 建模块间交互:文本分块中不同分块之间信息缺少交互,增加单向或者双向的块间信息交互。 * 句间关系(Inter-sentence Relations):长文本中含有许多句子,因此拥有复杂的句间关系。然而,PLM大多更善于捕捉token级别的依赖,因此需要对于句子层面的关系进行额外建模。
层次化模型:将Transformer结构修改为层次化模式,利用编码器显式编码句子级表示,解码器利用两个级别的信息。 * 图模型:将下游任务转化为结点分类任务,文本转化为图。其中,句子表示作为结点,利用边捕获句间关系,并使用图神经网络进行结点分类。 * 篇章结构(Discourse Structure):长文本中通常含有复杂的篇章(含有多个句子的语义单元)结构信息,如科学论文中的章节。
显式设计模型:在模型中设计模块负责捕捉篇章结构信息。 * 隐式增强模型:不改变模型架构,在训练,输入预处理等阶段引入归纳偏置。
**
**
应用(Applications)
文章介绍了涉及建模长文本的典型下游任务: * 文本摘要(Text summarization) * 问答(Question answering) * 文本分类(Text classification) * 文本匹配(Text matching)
未来方向(Future Directions)
最后,文章讨论了一些可能的未来方向: * 探究适用于长文本模型架构 * 探究长文本预训练语言模型 * 探究如何消除长文本和现有语言模型之间的差距 * 探究在低资源情况下对长文本进行建模 * 探究使用大型预训练语言模型(LLMs)对长文本进行建模
总结
文章介绍了近年来使用Transformer解决长文本的一些研究工作,如果不足和遗漏,欢迎大家留言讨论。