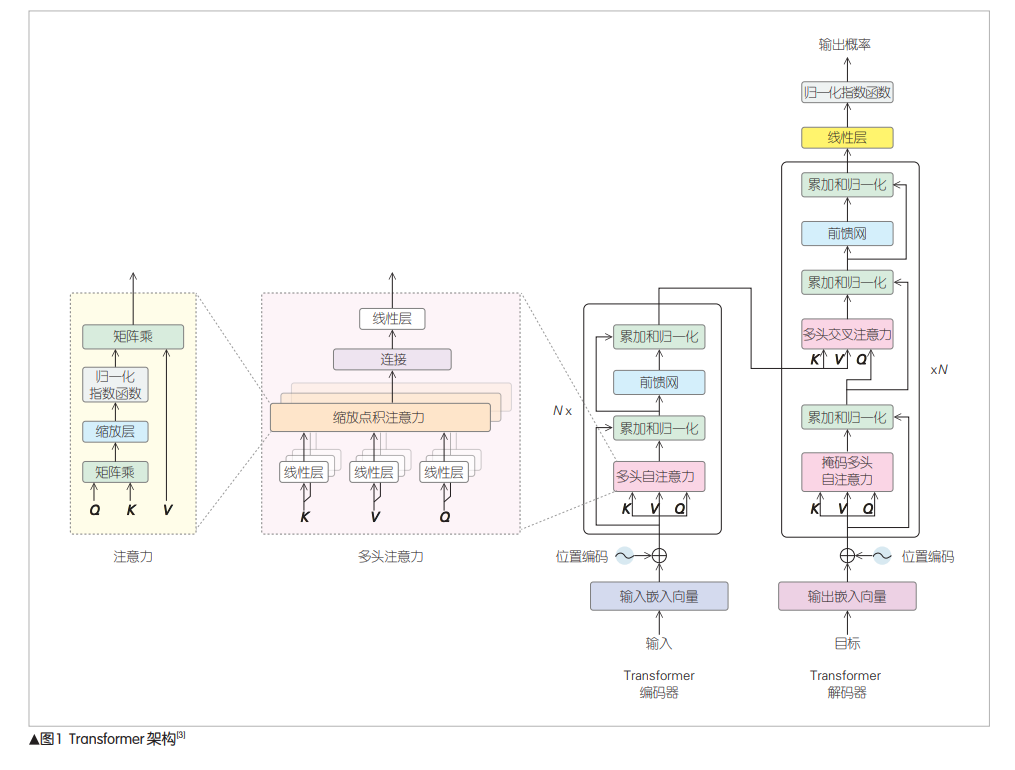
基于Transformer架构的大语言模型展现出强大的能力,是人类迈向通用人工智能(AGI)的一个重大进步。大语言模型架构和算法的演 进分为提高推理效率、提高模型能力两条技术路线。介绍了两条技术路线主流的技术方案和思路。提高推理效率的方法有分布式推理、计算优 化、访存优化、量化等;提高模型能力主要是引入新的架构,如混合专家(MoE)模型、状态空间模型(SSM)等。 OpenAI 于 2022 年、2023 年 分 别 发 布 ChatGPT[1] 和 GPT4[2] ,其强大的会话能力、多模态能力震惊业界,是人 类迈向通用人工智能 (AGI) 的一个重大进步。ChatGPT和 GPT-4能力强大的原因有两个:一是Transformer[3] 架构的自 注意力机制,可获取任意距离间单词的相关信息;二是大 模型、大数据、大算力,规模超过了一定阈值,则会产生 涌现能力[4] 。 目前各大公司都发布了自己的大语言模型 (LLM)。本 文中,我们主要介绍大语言模型在两条技术路线上的架构和 算法的演进。 1.1 语言模型的发展历程 语言模型的发展经历了统计语言模型、神经语言模型、 预训练语言模型和大语言模型4个阶段[5] 。其结构从基于统 计概率发展到基于神经网络,模型复杂度不断增加,能力也 出现了质的提升。 1) 统计语言模型 最初的语言模型是基于统计概率的,即根据语料统计出 在某个上下文出现某个词的概率,根据概率选择最合适的词。 2) 神经语言模型 文献[6]首次将神经网络引入语言模型。常见的模型结 构有循环神经网络 (RNN)[7] 、长短期记忆网络 (LSTM)[8] 等。RNN用隐藏层保存逐个输入的词的信息,但由于梯度 消失和梯度爆炸,只能保留短期信息。LSTM使用门控机制, 可以选择性地保留长期信息。 3) 预训练语言模型 ELMo[9] 用预训练的双向LSTM网络根据上下文动态生成 词向量,解决了一词多义问题。双向LSTM网络可以在下游 任务上微调,得到更好的效果。基于Transformer的双向编码 器表征法 (BERT)[10] 也采用了预训练+下游任务微调的 范式。 4) 大语言模型 预训练语言模型的性能随着规模的增大而提高,成幂律 关系[11-12] 。OpenAI设计了大型语言模型GPT-3[13] 。该模型表 现出强大的能力,性能和规模超越了幂律关系,出现了涌现1.2 大语言模型算法演进路线 大语言模型的发展主要有两条技术路线:一是提高推理 效率,降低推理成本;二是提高模型能力,迈向AGI。 大语言模型能力强大,有广阔的应用前景,各厂商都在 积极部署,提供服务。但是,由于模型规模巨大,算法对硬 件不够友好,需要消耗大量的算力、存储、能源。因此,如 何降低推理成本、推理延时,是一个亟待解决的问题。大语 言模型主要的技术路线有分布式推理、减小模型计算量、减 小模型访存量、提升硬件亲和性等。 大语言模型是迈向AGI的重大进步,而Transformer是其 中的核心架构,发挥了重大作用。但Transformer也有一定的 不足,如计算量大,通过提升规模来提升性能更加困难;上 下文窗口长度有限,难以支持超长序列。研究人员通过引入 新的结构,解决这些问题,取得了较好的效果。