
文本匹配是一项研究两段文本之间的相关关系的任务,在如搜索引擎、文档挖掘、智能对话等场景有着广泛应用和重要意义。
在文本匹配任务中,目标文本和候选文本之间的联系以及文本内部的上下文关联都是实现准确匹配的关键。然而,大多数已有的深度神经网络模型只关注了前者,忽略了每个文本内部的上下文语义信息,从而面临着长文本、复杂文本难匹配等问题。
解决方案 为了解决上述问题,中科院自动化所智能感知与计算研究中心团队提出一种基于文本图神经网络架构的匹配方法,用图(graph)结构表示文本,能够同时建模两个文本之间的交互以及每个文本内部的上下文关联,可以有效缓解现有方法中长文本难匹配的问题,如图1所示。
对于构建的文本图,该方法采用“聚合(aggregation)”、“更新(update)”以及“读出(readout)”三个步骤进行建模学习,如图2所示。其中,“聚合”步骤将上下文信息进行汇总,“更新”步骤将汇总的信息进行筛选和合并,最后“读出”步骤将整图信息输出为相似度得分。
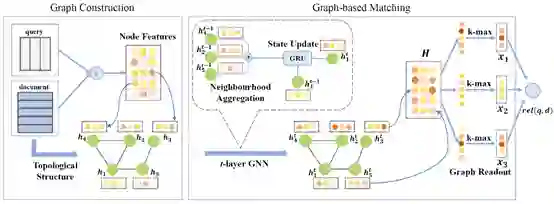
基于图神经网络的文本匹配框架示例
该方法在常见的文本匹配数据集上进行了实验,取得了与当前主流预训练模型(BERT)相当的结果,并且在长文本数据集上对基线的提升更显著,验证了模型的有效性。
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯
相关论文