

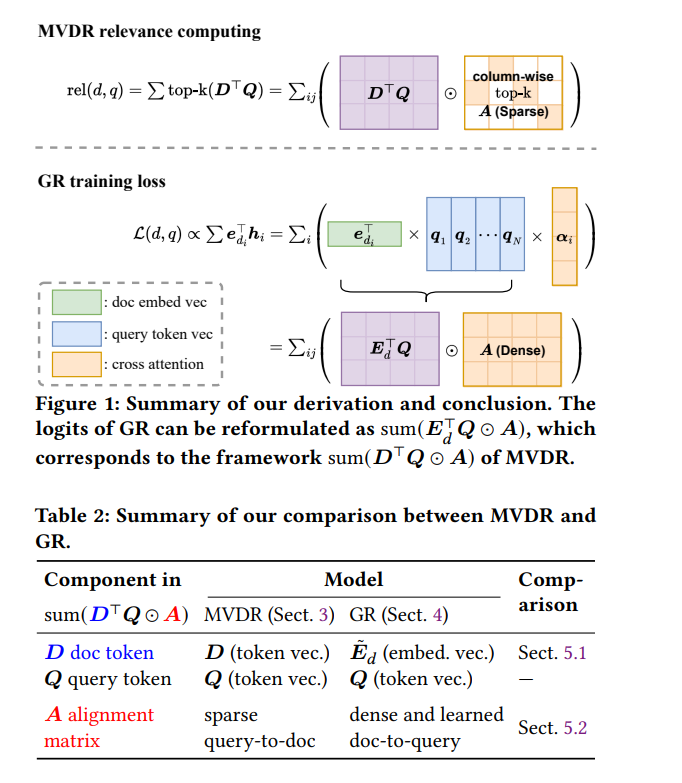
生成检索通过使用序列到序列的架构,以端到端的方式生成相关文档的标识符来响应给定查询。生成检索与其他检索方法,尤其是基于密集检索模型中的匹配方法之间的关系,尚未完全理解。先前的工作表明,使用原子标识符的生成检索等同于单向量密集检索。因此,当使用层次化语义标识符时,生成检索展示出类似于在密集检索的树索引中进行层次化搜索的行为。然而,之前的研究仅关注检索阶段,没有考虑生成检索解码器中的深层交互。 在本文中,我们通过展示生成检索和多向量密集检索共享相同的框架来衡量文档对查询的相关性来填补这一空白。具体来说,我们检查了生成检索的注意力层和预测头,揭示了生成检索可以被理解为多向量密集检索的一个特例。这两种方法都将相关性计算为查询和文档向量及其对齐矩阵的乘积之和。然后,我们探讨了生成检索如何应用这一框架,采用不同的策略来计算文档令牌向量和对齐矩阵。我们进行了实验来验证我们的结论,并显示这两种范式在其对齐矩阵中展示了术语匹配的共性。 我们的发现适用于许多生成检索标识符设计,并提供了关于生成检索如何表达查询-文档相关性的可能解释。由于多向量密集检索是当前最先进的密集检索方法,理解生成检索与多向量密集检索之间的联系对于揭示生成检索的底层机制以及开发和理解新检索模型的潜力至关重要。
成为VIP会员查看完整内容
相关内容
相关主题
相关VIP内容
相关资讯
相关论文