

个人数字数据是一项关键资产,全球各地的政府已经实施了法律和规章来保护数据隐私。数据使用者被赋予了其数据的“被遗忘权”。在机器学习(ML)过程中,被遗忘权要求模型提供者在用户请求时删除用户数据及其对ML模型的后续影响。机器遗忘应运而生,以解决这一问题,它从业界和学术界获得了越来越多的关注。虽然这一领域发展迅速,但缺乏全面的综述来捕捉最新的进展。认识到这一缺口,我们进行了广泛的探索,绘制了机器遗忘的全景,包括在集中式和分布式设置下遗忘算法的(细粒度)分类、关于近似遗忘的讨论、验证和评估指标、不同应用下遗忘的挑战和解决方案,以及针对机器遗忘的攻击。本综述通过概述未来研究的潜在方向来结束,希望能为感兴趣的学者们提供指导。
https://www.zhuanzhi.ai/paper/0f1c229cadcb491e16dc9a452b6d7d91
在数据和计算能力的爆炸性增长驱动下,深度学习(DL)在各种应用中展现了惊人的性能,如自动驾驶[77, 130]、从氨基酸序列预测蛋白质的3D结构[51]、破译遗传密码并揭示隐藏的DNA疾病的秘密[22],以及最近的人工智能生成内容(AIGC)浪潮,代表作有通过ChatGPT进行的文本生成[29, 97]、通过扩散模型进行的图像和视频生成[125]、以及通过Codex进行的代码生成[19]。这些模型是在用户贡献的数据[70]上训练的。无意中,这引发了隐私担忧,因为模型永久记住了用户的私人信息,这可能通过已知的例如成员推断、属性推断和偏好分析攻击以及尚未披露的隐私攻击泄露。
通过认识到保护用户数据隐私的重要性,国家政府已经发布了一系列规定,包括欧盟的一般数据保护条例(GDPR)[2]、加拿大的消费者隐私保护法(CPPA)和美国的加利福尼亚消费者隐私法(CCPA)[1]。这些规定规定了相关数据消费者或组织收集、存储、分析和利用公民个人数据的强制手段。通过“被遗忘权”的执行,数据消费者必须迅速遵守用户请求删除其数据并消除任何相关影响。这赋予了数据贡献者即使在数据发布后也能控制自己数据的能力,促进了分享和贡献高质量数据的意愿。这反过来又通过提高服务利润和降低法律风险,为(模型)服务提供者带来了好处[11]。
值得注意的是,遗忘数据不仅符合法律要求以保护隐私,而且在其他场景中也是有益的。它可以遗忘由于有害数据(例如,对抗数据、投毒数据[134]、噪声标签[80])或过时数据造成的不利影响,从而提高模型的安全性、响应性和可靠性。此外,通过遗忘对手针对的受害者数据,它可以减轻多种隐私攻击,如成员推断攻击和模型反转攻击,防止模型中敏感训练数据的私人信息泄露。
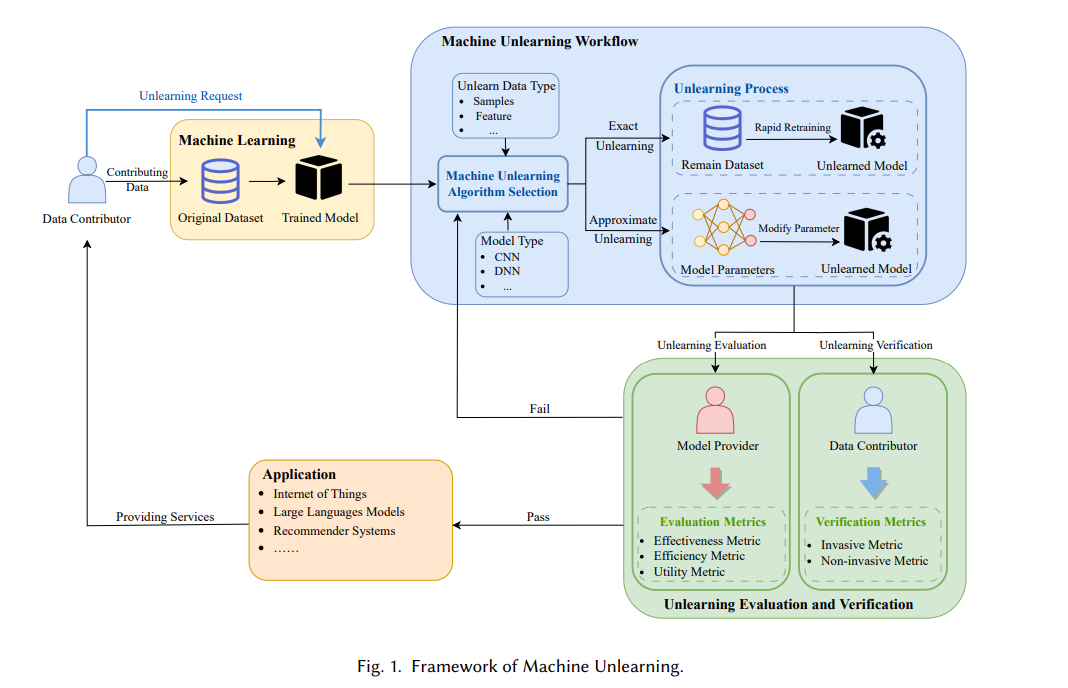
在DL上下文中,仅从后端数据库中删除原始训练数据相对无意义。因为DL模型仍然(显式或非显式地)记住了通常包含请求数据样本的敏感细节的根深蒂固的模式和特征[4, 13]。因此,与DL模型直接相关的原始数据潜在表示似乎是一个挑战,难以直接从DL模型中消除。现有的传统隐私保护技术未能满足这些要求,导致了机器学习中称为机器遗忘(MU)的研究方向的出现。MU使数据贡献者能够主动撤回用于模型训练的数据,旨在从训练好的模型中擦除其影响,就好像它从未存在过一样,而不损害模型的实用性(如图1所示)。
鉴于赋予的“被遗忘权”,机器遗忘无疑变得更加相关。最直接的方法是定期从头开始在剩余数据集上重新训练一个新模型(不包括要遗忘的数据群)。不幸的是,这显然会带来昂贵的计算开销以及响应延迟,尤其是对于不断增加的数据集大小和模型复杂性。这种从头开始的训练更有可能对模型提供者和用户来说是不可接受的,因此对于实际应用来说并不实用。机器遗忘试图克服上述简单方法的严重缺点。现有的MU方法可以根据是否需要对剩余数据集进行(重新)训练操作分为两大类,即精确遗忘和近似遗忘。精确遗忘旨在加速(重新)训练过程,而近似遗忘通过直接更改模型参数,避免了重新训练的需要,两者都使得遗忘后的模型与采用简单方法获得的模型无法区分。
**机器遗忘正在经历迅速的发展,但存在着显著的全面总结和分析缺乏,以更好地描绘最新技术状态。**例如,缺乏解决跨各种应用的机器遗忘挑战的讨论,以及缺少对机器遗忘安全性分析的讨论。这些不足促使我们进行了彻底的调查。本综述涵盖了2015年至2024年机器遗忘领域的关键研究,包括集中式和分布式设置下遗忘算法的分类——后者经常被忽视,评估和验证指标,启用遗忘的应用,以及针对威胁MU的攻击。本综述的目的是提供一个知识库,以促进该新兴MU领域的进一步学术研究和创新。 本综述的关键贡献总结如下:
我们对现有的机器遗忘算法进行了全面的回顾,这些算法适用于包括大型语言模型在内的多种任务,系统地将它们按遗忘机制进行分类,并对每个(子)类别固有的优点和限制进行了批判性分析。
我们提供了在分布式学习设置中面临的机器遗忘挑战的详细分析,系统地对其方法进行了分类并比较了它们的优点和缺点。
我们为机器遗忘中现有的验证和评估指标制定了一个分类体系。这个分类旨在协助数据所有者和模型所有者,强调每个指标的主要关注点。
我们强调了机器遗忘在各种场景中的多样化应用,强调其在优化模型和防御安全与隐私攻击方面的独特优势。这种灵活性允许在现实世界情况下根据特定需求进行快速部署和适应。
我们对与机器遗忘相关的挑战进行了彻底的考察,概述了未来学者探索和参考的潜在研究方向。
本综述的组织结构如下。第2节介绍机器遗忘的初步知识。第3节讨论用于衡量机器遗忘质量的验证和评估指标。第4节对现有的机器遗忘算法进行分类,深入探讨每个细粒度类别并彻底分析其各自的优点和缺点。第5节研究分布式设置中出现的机器遗忘。第6节强调机器遗忘启用的潜在应用,例如,擦除有害信息。第7节总结针对机器遗忘的现有隐私和安全攻击。最后,第8节勾画了机器遗忘当前面临的挑战,并提出了有希望的未来研究方向。