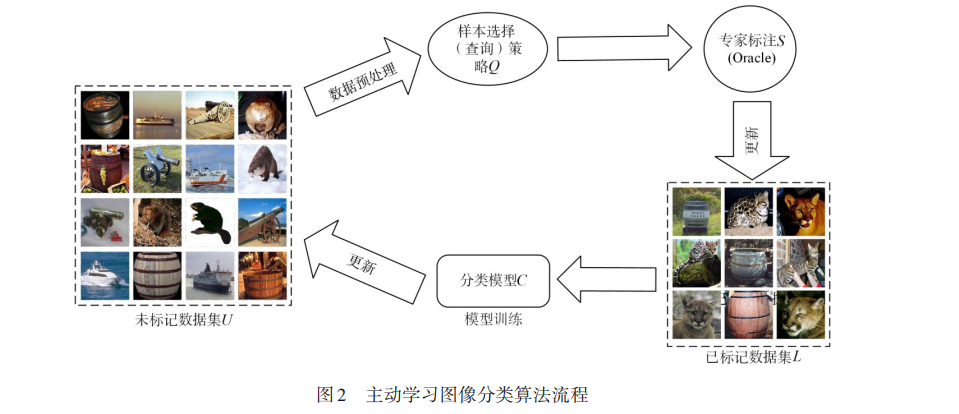
图像分类作为计算机视觉领域中的重要研究方向之一,应用领域非常广泛.基于深度学习的图像分类技术取得的成功,依赖大量的已标注数据,然而数据的标注成本往往是昂贵的.主动学习作为一种机器学习方法,旨在以尽可能少的高质量标注数据达到期望的模型性能,缓解监督学习任务中存在的标注成本高、标注信息难以大量获取的问题.主动学习图像分类算法根据样本选择策略,从未标记样本数据集合中选择出信息量丰富,对分类模型训练贡献更高的样本进行标注,以更新已标注训练数据池,如此循环直至满足给定的停止条件或模型标注预算耗尽.本文对近年来提出的主动学习图像分类算法进行了详细综述,并根据所用样本数据处理及模型优化方案,将现有算法分为三类:基于数据增强的算法,包括利用图像增广来扩充训练数据,或者根据图像特征插值后的差异性来选择高质量的训练数据;基于数据分布信息的算法,根据数据分布的特点来优化样本选择策略;优化模型预测的算法,包括优化获取和利用深度模型预测信息的方法、基于生成对抗网络和强化学习来优化预测模型的结构,以及基于Transformer结构提升模型预测性能,以确保模型预测结果的可靠性.此外,本文还对各类主动学习图像分类算法下的重要学术工作进行了实验对比,并对各算法在不同规模数据集上的性能和适应性进行了分析.另外,本文探讨了主动学习图像分类技术所面临的挑战,并指出了未来研究的方向. 图像分类是计算机视觉领域中的一大基本任务 . 图像分类任务的核心在于图像特征提取和分类器的设 计. 随着深度学习(Deep Learning,DL)[1] 技术的不断发 展,基于卷积神经网络(Convolutional Neural Networks, CNN)[2] 的图像特征提取技术取得了巨大的成就. 卷积 神经网络可以通过组合简单特征形成更复杂和抽象的 特征,从而提高图像分类任务的准确性和鲁棒性. 作为 一种数据表示学习的方法,深度学习可以通过迭代更 新深度网络层级参数来训练和优化模型,从而使结果 更加接近真实值 . 常用于图像分类的深度网络包括 LeNet[3],GoogLeNet[4],AlexNet[5],VGGNet[6],ResNet[7] 等. 然而,在图像分类领域,为了得到高精度的分类器, 深度学习模型很大程度上依赖大量已标注数据来优化 模型参数. 特别是在需要高水平专业知识的领域,如医 学图像[8] 、遥感图像[9] 等,获取大量的高质量已标注数 据集需要消耗大量的人力. 主动学习(Active Learning,AL)[10] 作为一种能够降 低样本标注成本的学习方法,正逐渐受到越来越多的 关注. 主动学习作为监督式机器学习中的一种范式,旨 在标注尽可能少的样本,同时最大化模型的性能增益. 具体来讲,主动学习根据样本选择策略从未标记的数 据集中选择信息丰富的样本,交由 Oracle 进行标注,以 降低模型所需数据量、计算资源和存储资源的需求,同 时保持分类器性能. Oracle是一个能够提供准确标签的 信息源,可以是人类专家或自动化系统. 样本选择策略 决定了算法选择哪些样本以获得最大的模型性能提 升 . 目前,主动学习已被应用于分类与检索[11] 、图像分 割[12] 、目标检测[13] 等多种图像处理任务.
在早期研究中,文献[10]将目前主动学习方法定 义为三种基本框架:基于成员查询的主动学习、基于流 的选择性采样和基于池的主动学习 . 基于成员查询的 主动学习方法是指学习器可以请求查询输入空间中任 何未标记样本的标签,包括学习器生成的样本. 基于流 的选择性采样是指每次从未标记数据源中提取一个样本数据,学习器必须决定是查询标签还是丢弃该数据. 基于池的主动学习框架则维护一个未标注数据集合, 由样本选择策略从未标记集合中选择要标注的样本. 目前,基于池的主动学习框架更适用于图像分类 任务中. 该框架能同时处理批量数据,从未标记数据集 中选出对模型训练最有帮助的数据进行标注,提高标 注数据效率,降低成本 . 此外,该框架适用于数据集规 模较大、标注数据较少的情况,符合多数图像分类技术 场景. 相比之下,基于成员查询的主动学习算法需要逐 个查询成员并进行标注,不适用于大规模的数据集. 基 于流的选择性采样在处理流数据时,对每个数据点进 行快速分类来实现快速标注,从而处理大量的数据流. 但在图像分类中,每个数据点都是一个独立的图像,对 每个图像进行分类和标注可能会带来更多的标注成 本,因此该方法在图像分类中使用较少. 该方法主要适 用于需要时效性的小型移动设备的应用场景,因为这 些小型设备通常具有有限的存储和计算能力 . 图 1 展 示了基于池的主动学习的基本框架.