近年来,机器人技术和人工智能(AI)系统的发展可谓非常显著。随着这些系统不断发展,它们被用于越来越复杂和无结构的环境中,如自动驾驶、空中机器人和自然语言处理等领域。
因此,通过手动编程其行为或通过奖励函数来定义它们的行为(如在强化学习(RL)中所做的那样)变得异常困难。这是因为这些环境需要高度的灵活性和适应性,很难指定一个能够考虑到所有可能情况的最佳规则或奖励信号集。
在这种环境中,通过模仿专家的行为来学习通常更具吸引力。这就是模仿学习(IL)发挥作用的地方 - 一种通过模仿专家的行为来学习所需行为的过程,这些行为是通过示范提供的。
本文旨在介绍IL并概述其基本假设和方法。它还详细描述了该领域的最新进展和新兴研究领域。此外,本文讨论了研究人员如何解决与IL相关的常见挑战,并提供了未来研究的可能方向。总的来说,本文的目标是为机器人和人工智能领域不断发展的IL领域提供全面的指南。

IL技术有潜力将教授任务的问题减少到提供演示的问题,从而消除了明确编程或开发任务特定奖励函数的需要[3]。IL的概念基于这样一个前提,即即使人类专家无法将所需的行为编程到机器或机器人中,他们仍然能够演示所需的行为。因此,IL可以在任何需要类似于人类专家的自主行为的系统中得到应用[1]。
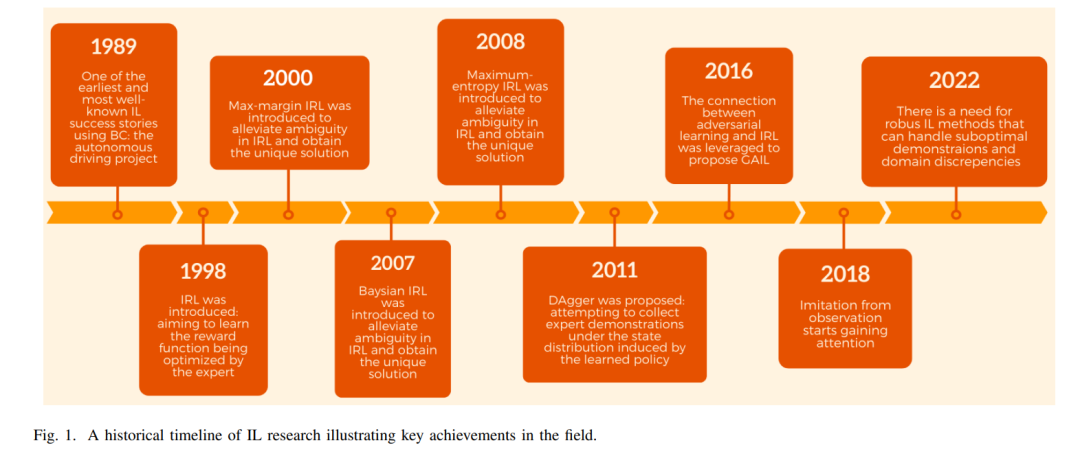
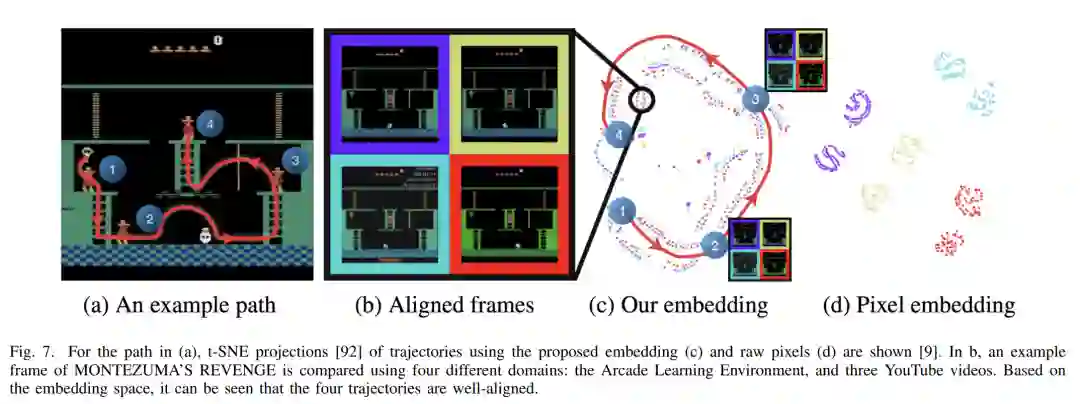
IL的主要目的是通过提供演示使代理能够学习模仿专家来执行特定任务或行为[4]。演示用于训练学习代理执行任务,通过学习观察和行动之间的映射关系。通过利用IL,代理能够从在受限环境中重复简单预定行为过渡到在非结构化环境中采取最佳自主行动,而不会给专家带来太大负担[2]。因此,IL方法有潜力为广泛的行业带来重大好处,包括制造业[5]、医疗保健[6]、自动驾驶车辆[7]、[8]和游戏行业[9]。在这些应用中,IL允许专业领域的专家,他们可能没有编码技能或对系统的知识,有效地在机器或机器人中编程自主行为。尽管模仿学习的理念已经存在一段时间,但计算和感知方面的最新成就,以及对人工智能应用的不断增长的需求,增加了IL的重要性[10],[11]。因此,近年来该领域的出版物数量显著增加。在过去的二十年里,已经出版了多次关于IL的综述,每一次都聚焦于该领域发展的不同方面(图1)。Schaal [3] 提出了第一份关于IL的综述,重点关注IL作为创建类人机器人的途径。最近,Osa等人[1]从算法的角度提供了关于IL的观点,而Hussein等人[12]全面审查了IL过程各个阶段的设计选择。最近,Le Mero等人[7]为端到端自动驾驶系统提供了基于IL的技术的全面概述。尽管已经存在大量关于IL的调查,但新的调查仍然有必要捕捉这一快速发展领域的最新进展,提供一个关于最新技术发展的最新综述。随着这一领域越来越受到关注,并具有多种应用,一份综合性调查可以作为新手的重要参考,同时提供不同用例的概述。我们承认IL是一个不断发展的领域,不断有新的算法、技术和应用被开发出来。
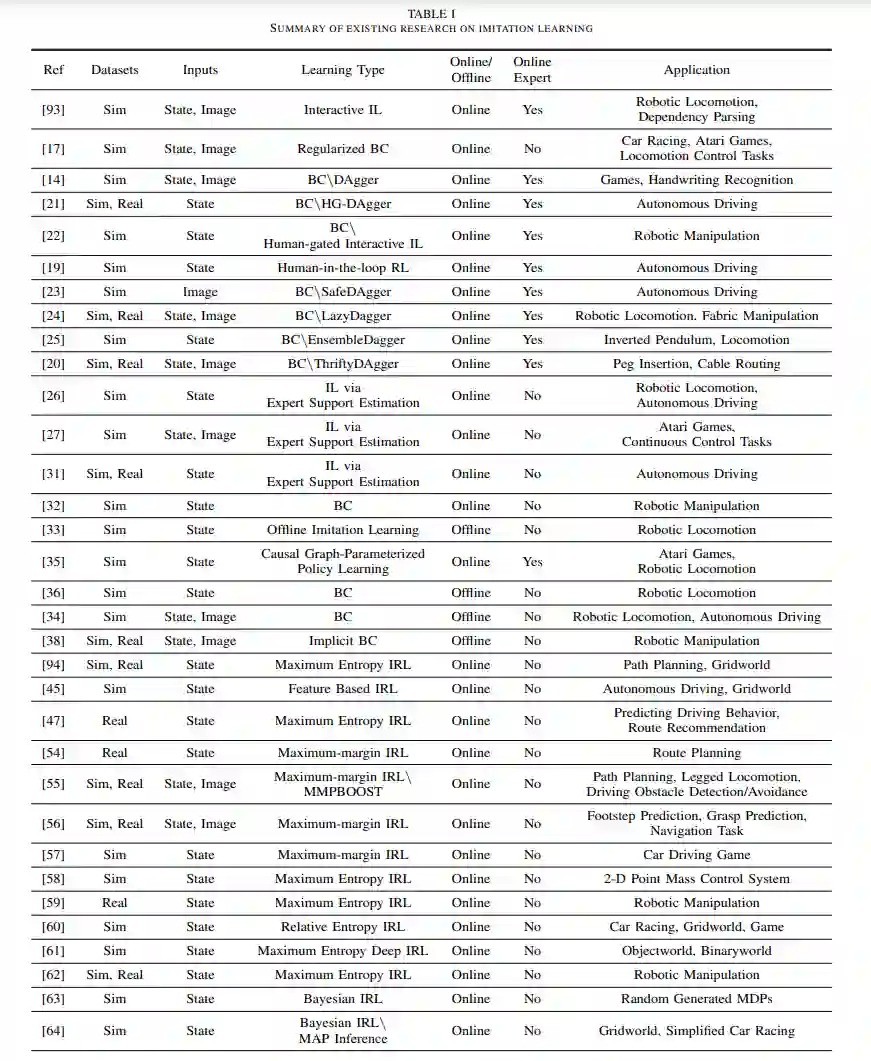
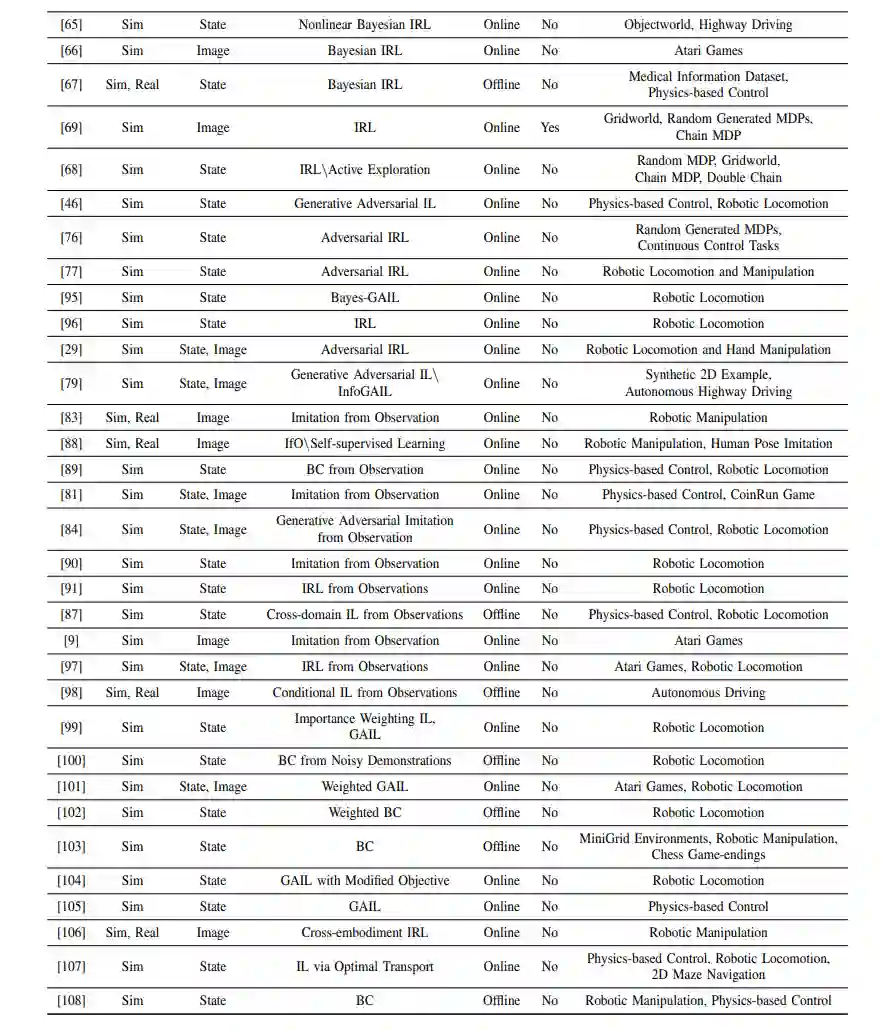
因此,我们的调查旨在整合大量关于IL的研究,以便研究人员和从业者更容易导航。此外,我们旨在识别当前研究中存在的差距和挑战,为未来的工作提供明确的方向。最后,我们的目标是使IL的概念和技术更容易被更广泛的受众,包括相关领域的研究人员,以增进对这一领域的理解。总的来说,我们坚信我们的调查将为推动IL领域的发展做出重大贡献,并指导这一令人兴奋的领域的未来研究。这份综述论文的目标是全面介绍IL领域。为了实现这一目标,我们将根据历史和逻辑原因来组织我们对IL方法的讨论。首先,我们将介绍IL的两大广泛方法类别:行为克隆(BC)和逆强化学习(IRL)。我们将讨论它们的表述、发展、优势和局限性。此外,我们将探讨对抗性模仿学习(AIL)如何通过引入对抗性上下文来扩展IRL的方法,突出了将对抗性训练融入IL的好处,并评估AIL领域的当前进展。此外,我们将介绍来自观察的模仿(IfO)作为一种新颖的技术,旨在从仅包含状态(无动作)演示中进行学习。我们将讨论IfO的重要性,以及它如何在不同方法中结合并扩展了先前的BC、IRL和AIL类别,以解决从仅包含状态观察中进行学习的挑战。最后,我们将讨论IL技术在现实场景中遇到的挑战,如次优演示和专家与学习者之间的领域差异。我们将总结不同的IL方法、它们的局限性,并探讨可以采取的未来研究方向,以解决这些问题。
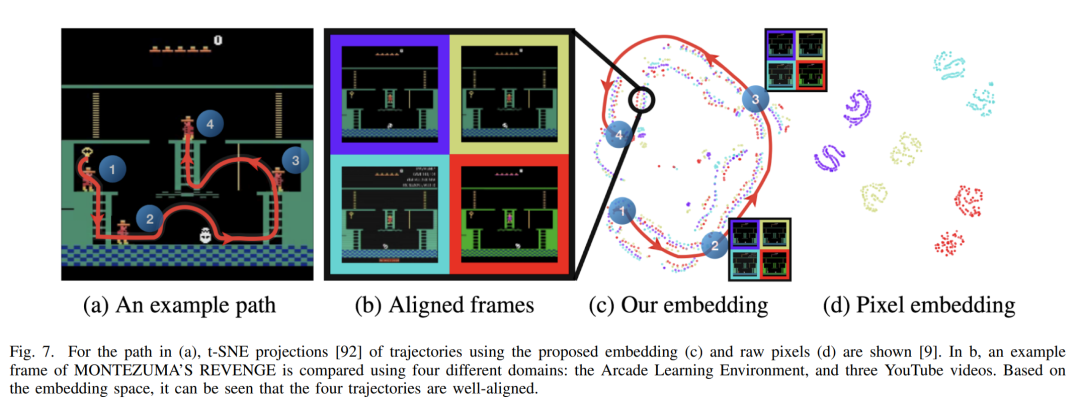
这份综述论文提供了关于模仿学习(IL)领域的全面概述,探讨了其算法、分类、发展和挑战。论文首先提出了IL算法的分类,确定了两种一般的学习方法,即行为克隆(BC)和逆向强化学习(IRL),并讨论了它们的相对优势和局限性。此外,论文强调了将对抗性训练整合到IL中的好处,并评估了AIL领域的当前进展。论文还介绍了一种称为IfO的新颖技术,旨在从仅包含状态的演示中学习。通过检查各种IL算法,我们对它们的优点和局限性有了宝贵的见解,并确定了一些未来研究的关键挑战和机会。在所有IL方法类别中,一个重要的挑战是需要收集多样化和大规模的演示,这对于训练一个可以在现实世界中应用的可泛化策略至关重要[111]。然而,这带来了一个挑战,因为现成的演示资源,如在线视频,存在额外的困难,例如演示者之间的专业水平不同。IL研究中的另一个挑战是开发能够使代理能够跨领域学习的方法,这些领域具有不同的动态、视角和体现。如果我们要有效地教导代理从专家那里学习并将IL研究的见解应用到现实场景中,那么克服这些挑战是必不可少的。因此,未来的研究应该集中于开发能够从不完美的演示中学习、提取有用信息并实现跨领域学习的算法。尽管存在这些挑战,IL领域为未来研究提供了令人兴奋的机会。随着人工智能领域的不断发展和成熟,我们相信IL将在使智能体能够从演示中学习、适应新任务和环境,并最终实现更高级别的智能方面发挥关键作用,为人工智能的实际应用铺平道路。