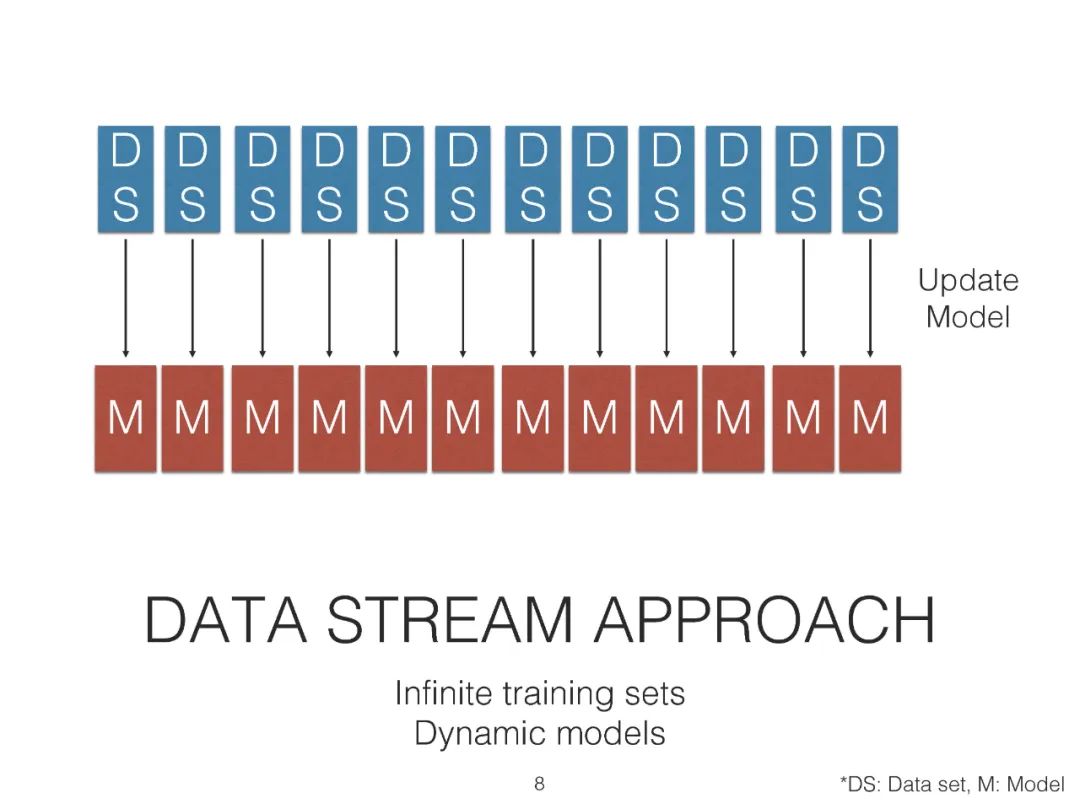
在线聚类算法在数据科学中发挥着至关重要的作用,尤其是在时间、内存使用和复杂性方面的优势,同时与传统聚类方法相比保持了较高的性能。本教程服务于,首先,作为在线机器学习的调查,特别是数据流聚类方法。在本教程中,最先进的算法和相关的核心研究线程将通过识别不同的类别基于距离,密度网格和隐藏的统计模型。聚类有效性指标作为聚类过程中的一个重要组成部分,通常被忽略或被分类指标所取代,导致对最终结果的误解,也将被深入研究。
然后,本文将介绍River,一个由Creme和scikit-multiflow合并而成的go-to Python库。它也是第一个包含在线集群模块的开源项目,该模块可以促进可重复性,并允许直接进一步改进。在此基础上,我们提出了基于现实问题和数据集的聚类配置、应用程序和基准设置的方法。
https://hoanganhngo610.github.io/river-clustering.kdd.2022/
教程的大纲,如下:
数据流(在线)机器学习导论(约45分钟) 什么是在线机器学习,我们为什么需要在线机器学习? 与批量/传统机器学习相比,在线机器学习的差异、优点和缺点。 River简介,一个由Creme和scikit-multiflow合并而成的用于机器学习的实用Python库。 River在分类、概念漂移、估计值实现等方面的实际应用,以及使用全视图显示实时结果。
在线聚类算法和评估指标。
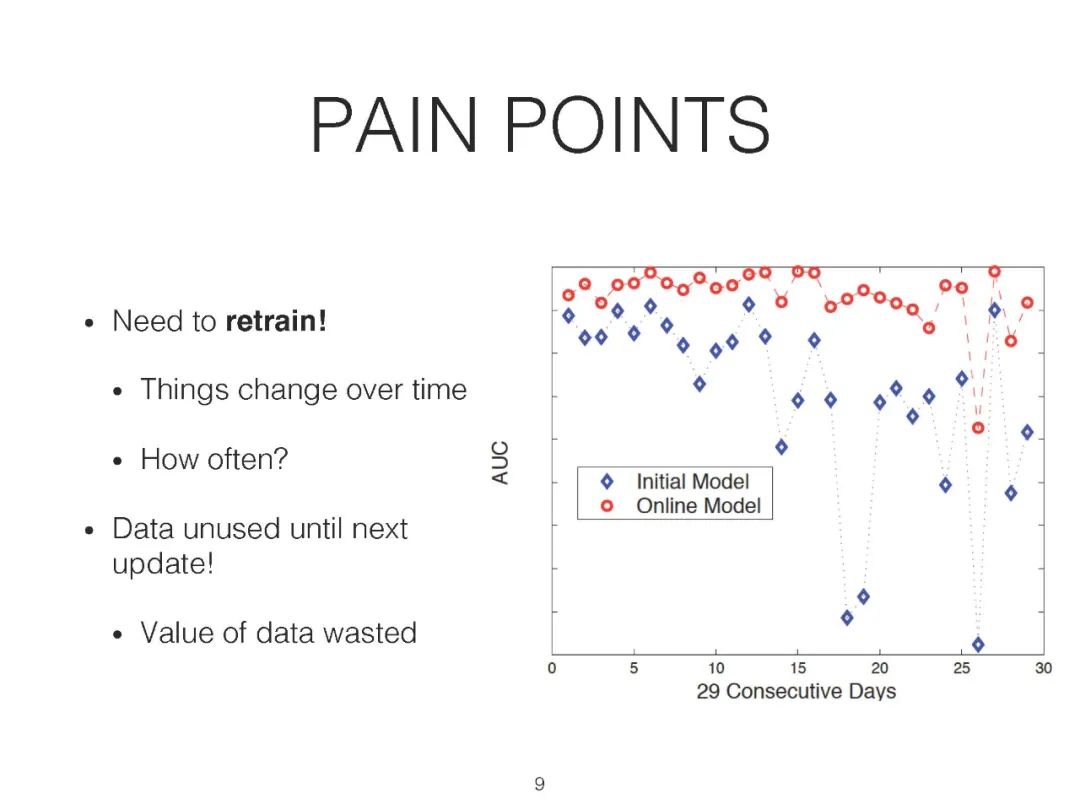
综述了现有聚类算法、一般概念及其发展。 聚类和分类评价指标的主要差异,可能导致对最终结果的错误解释。 在线聚类算法和评估指标在实际问题中的实际应用。
用例和基准测试。
在线与传统/批处理聚类算法的比较。 进行基准测试的动机、设置和系统要求。 关于使用River包以及相关的git库和终端进行基准测试的教程。