NeurIPS2021 | 领域自适应的循环自训练方法与理论

领域自适应(Domain Adaptation, DA)解决从有监督数据集到无监督数据集的知识迁移问题。在深度学习时代,不变表征学习(Invariant Representation Learning)是领域自适应(Domain Adaptation)中的主流方法。不变表征学习减少了源领域(Source Domain)和目标领域(Target Domain)之间的表征分布距离,从而学习到不变表征(Invariant Representation)。不变表征学习构成了领域自适应方法的核心,获得了很大成功,但不可能定理(Impossibility Theorem)揭示出在标签偏移(Label Shift)和领域支撑集偏移(Shift in the Support of Domains)两种困难情况下,不变表征学习具有泛化误差下界,因而具有明显的局限性,是领域自适应的开放性难题。
https://www.zhuanzhi.ai/paper/a264f8364523f5f70bde4936c677a5d4
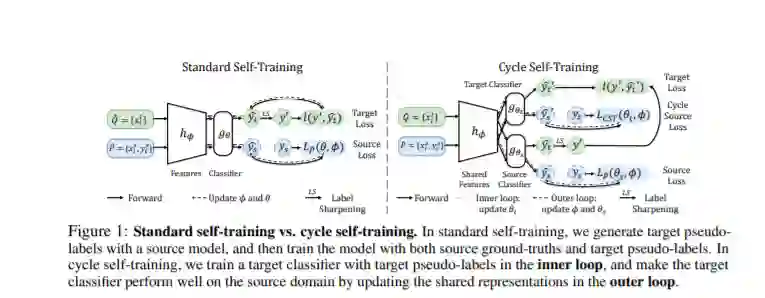
最近,自训练(Self-training)方法开始被应用到领域自适应问题中。自训练作为半监督学习(Semi-supervised Learning)中的主要方法,先在有监督数据上训练模型,再生成无监督数据的伪标签(Pseudo-labels),最后用真标签和伪标签来共同训练模型。然而在领域自适应问题中,自训练的伪标签会因为源领域和目标领域的分布偏移而变得更加不准确,直接使用全部伪标签将造成误差累积。之前的工作采用可信度阈值(Confidence Threshold)来筛选可靠的伪标签或者给可靠的伪标签更大的权重,然而这类方法不但需要对不同的任务大量调节阈值,而且仍然无法保证分布偏移条件下伪标签的可靠性。
在本文中,我们首先研究了标准自训练在分布偏移条件下的技术挑战及根因。我们发现在无分布偏移条件下,伪标签分布和真标签分布几乎相同,然而在有分布偏移条件下,两者差异很大。即使采用置信度、信息熵等不确定性阈值来筛选,筛选机制的可靠性仍将因为分布偏移而显著下降,最终使得标准自训练在领域自适应问题中失效。为此,本文首次对这一问题开展了深入研究,形成了简单通用有效的循环自训练算法(Cycle Self-Training, CST),并建立了全新的基于扩张假设(Expansion Assumption)的领域自适应泛化理论。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CST” 就可以获取《NeurIPS2021 | Cycle Self-Training:领域自适应的循环自训练方法与理论》专知下载链接



