
机器之心报道 机器之心编辑部
刚刚,ICLR 宣布了今年度的杰出论文奖。

今年共有三篇论文获奖(Outstanding Paper),其中一篇由中国科学技术大学与新加坡国立大学合作完成。另外还有三篇获得了荣誉提名(Honorable Mentions),包括大家熟悉的 Meta「分割一切」论文的 2.0 版本。 以下是详细信息。
杰出论文
论文 1:Safety Alignment Should be Made More Than Just a Few Tokens Deep

作者:Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, Peter Henderson * 单位:普林斯顿大学、Google DeepMind * 链接:https://openreview.net/forum?id=6Mxhg9PtDE
当前大语言模型(LLM)的安全对齐(safety alignment)存在脆弱性。简单的攻击,甚至是看似无害的微调(fine-tuning),都可能突破对齐约束(即「越狱」模型)。研究者注意到,许多这类脆弱性问题源于一个共同的底层缺陷:现有对齐机制往往采取捷径,即仅在模型生成的最初几个输出 token 上进行调整。研究者将此类现象统一称为「浅层安全对齐」(shallow safety alignment)。 在本文中,研究者通过若干案例分析,解释浅层安全对齐为何会存在,并揭示其如何普遍性地贡献于近年来发现的多种 LLM 脆弱性,包括对对抗性后缀攻击(adversarial suffix attacks)、预填充攻击(prefilling attacks)、解码参数攻击(decoding parameter attacks)和微调攻击(fine-tuning attacks)的易感性。 本研究的核心贡献在于,研究者提出的「浅层安全对齐」的统一概念,为缓解上述安全问题指明了有前景的研究方向。研究者展示,通过将安全对齐机制延伸至超出最初数个 token 的范围,能在一定程度上增强模型对常见攻击方式的鲁棒性。 此外,研究者还设计了一种带正则项的微调目标函数(regularized fine-tuning objective),通过对初始 token 的更新施加约束,使得模型的安全对齐对微调攻击更具持久性。 总体而言,研究者主张:未来的大语言模型安全对齐策略,应当超越仅对几个初始 token 实施控制的做法,而实现更深层次的对齐。
论文 2:Learning Dynamics of LLM Finetuning

作者:Yi Ren, Danica J. Sutherland * 单位:不列颠哥伦比亚大学 * 链接:https://openreview.net/forum?id=tPNHOoZFl9 * 代码:https://github.com/Joshua-Ren/Learning_dynamics_LLM
学习动态(learning dynamics)描述特定训练样本的学习过程如何影响模型对其他样本的预测结果,是理解深度学习系统行为的有力工具。为了深入理解这一过程,研究者研究了大语言模型在不同微调类型下的学习动态,方法是分析潜在响应之间影响如何逐步积累的一种分步式分解(step-wise decomposition)。 研究者的框架提供了一种统一的视角,能够解释当前指令微调(instruction tuning)和偏好微调(preference tuning)算法训练过程中的多个有趣现象。研究者特别提出了一种假设性解释,以说明为何某些类型的幻觉(hallucination)现象会在微调后变得更加显著。例如,模型可能会将用于回答问题 B 的短语或事实用于回答问题 A,或在生成内容时反复出现类似的简单短语。 研究者还扩展了这一分析框架,引入一个称为「压缩效应」(squeezing effect)的独特现象,以解释在离线策略直接偏好优化(off-policy Direct Preference Optimization, DPO)过程中观察到的一个问题:如果 DPO 训练持续时间过长,甚至连原本被偏好的输出也更难被生成。
此外,该框架进一步揭示了在线策略 DPO(on-policy DPO)及其变体为何能更有效地优化模型行为的根本原因。本研究不仅为理解大语言模型的微调过程提供了新的视角,还启发了一种简单而有效的对齐效果提升方法。
论文 3:AlphaEdit: Null-Space Constrained Model Editing for Language Models

作者:Junfeng Fan, Houcheng Jiang(姜厚丞), Kun Wang, Yunshan Ma, Jie Shi, Xiang Wang, Xiangnan He, Tat-Seng Chua * 单位:新加坡国立大学、中国科学技术大学 * 链接:https://openreview.net/forum?id=HvSytvg3Jh * 代码:https://github.com/jianghoucheng/AlphaEdit
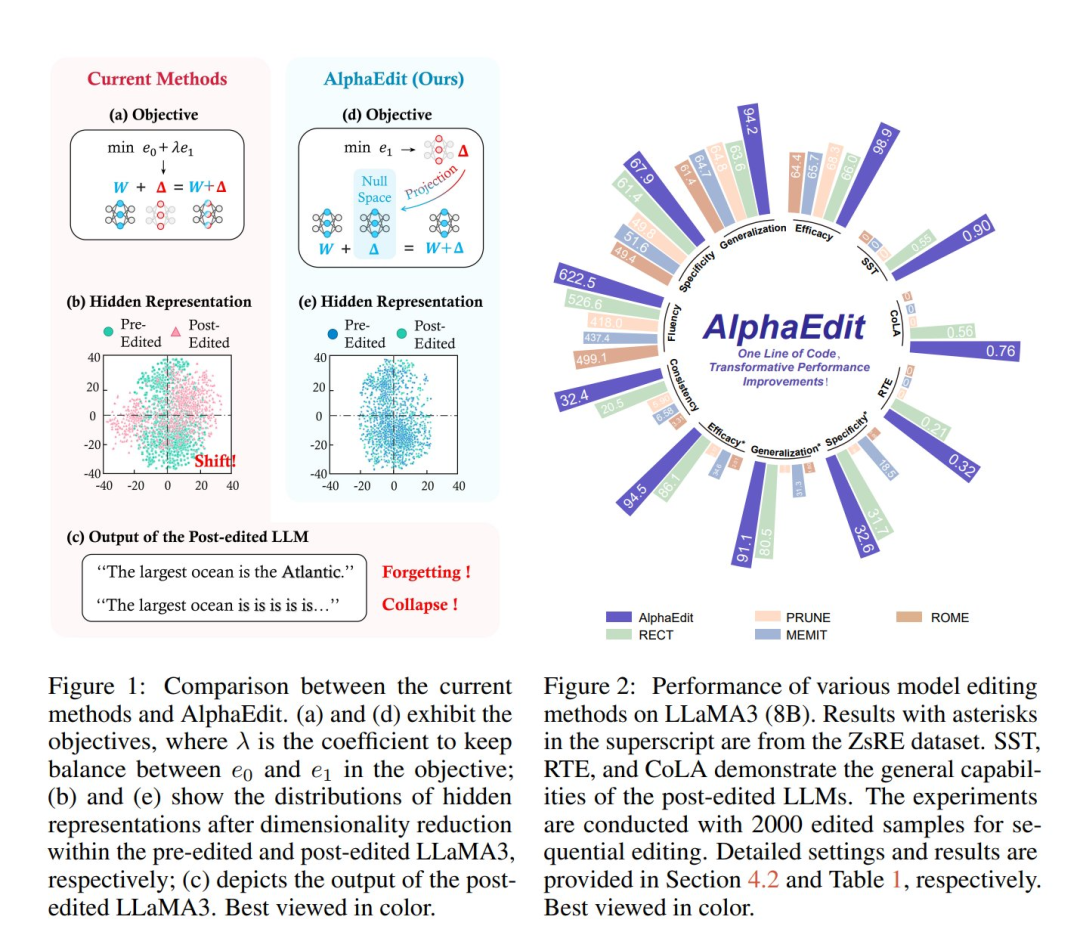
大型语言模型(LLM)常常会出现幻觉现象,生成错误或过时的知识。因此,模型编辑方法应运而生,能够实现针对性的知识更新。为了达成这一目标,一种流行的方式是定位 - 编辑方法,先定位出有影响的参数,再通过引入扰动来编辑这些参数。然而,目前的研究表明,这种扰动不可避免地会扰乱大型语言模型中原先保留的知识,尤其是在连续编辑的情境下。 为了解决这个问题,研究者推出了 AlphaEdit,这是一种创新的解决方案,它会在将扰动应用到参数之前,先将扰动投影到保留知识的零空间上。从理论上,作者证明了这种投影方式可以确保在查询保留知识时,经过编辑后的大型语言模型的输出保持不变,从而缓解了知识被扰乱的问题。在包括 LLaMA3、GPT2-XL 和 GPT-J 在内的各种大型语言模型上进行的大量实验表明,AlphaEdit 平均能使大多数定位 - 编辑方法的性能提升 36.7%,而且仅需添加一行用于投影的额外代码。
杰出论文荣誉提名
论文 1:Data Shapley in One Training Run

作者:Jiachen T. Wang, Prateek Mittal, Dawn Song, Ruoxi Jia * 单位:普林斯顿大学、加州大学伯克利分校、弗吉尼亚理工学院 * 链接:https://openreview.net/forum?id=HD6bWcj87Y
数据 Shapley 值提供了一个用于归因数据在机器学习环境中贡献的系统框架。然而,传统的数据 Shapley 值概念需要在各种数据子集上重新训练模型,这对于大规模模型来说在计算上是不可行的。此外,这种基于重新训练的定义无法评估数据对特定模型训练过程的贡献,而这在实践中往往是人们关注的焦点。 本文引入了一个新概念——In-Run Data Shapley,它消除了模型重新训练的需求,专门用于评估数据对特定目标模型的贡献。In-Run Data Shapley 计算每次梯度更新迭代的 Shapley 值,并在整个训练过程中累积这些值。作者提出了几种技术,使 In-Run Data Shapley 能够高效扩展到基础模型的规模。在最优化的实现中,这一新方法与标准模型训练相比几乎不增加运行时间开销。 这一显著的效率提升使得对基础模型预训练阶段进行数据归因成为可能。作者在论文中展示了几个案例研究,这些研究为预训练数据的贡献提供了新见解,并讨论了它们对生成式人工智能中版权问题和预训练数据筛选的影响。 论文 2:SAM 2: Segment Anything in Images and Videos

作者:Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollar, Christoph Feichtenhofer * 单位:Meta AI、斯坦福大学 * 链接:https://openreview.net/forum?id=Ha6RTeWMd0
在这篇论文中,Meta 提出了 Segment Anything Model 2(SAM 2),这是一种旨在解决图像和视频中可提示视觉分割(promptable visual segmentation)任务的基础模型。他们构建了一个数据引擎,该引擎可通过用户交互不断优化模型与数据,采集了迄今为止规模最大的视频分割数据集。他们的模型采用简单的 Transformer 架构,并引入流式内存,以支持实时视频处理。 基于这些数据训练得到的 SAM 2 在多项任务上展现出强大的性能。在视频分割中,SAM 2 在减少至原有方法约三分之一的交互次数的同时,准确率表现更佳。在图像分割任务中,SAM 2 的精度更高,并且速度相比之前的 SAM 提升了六倍。 主模型、数据集、交互式演示以及代码都已经开源发布,更多详情可参阅机器之心报道《Meta 开源「分割一切」2.0 模型,视频也能分割了》。 论文 3:Faster Cascades via Speculative Decoding

作者:Harikrishna Narasimhan, Wittawat Jitkrittum, Ankit Singh Rawat, Seungyeon Kim, Neha Gupta, Aditya Krishna Menon , Sanjiv Kumar * 单位:Google Research, Google DeepMind, Mistral AI * 链接:https://openreview.net/forum?id=vo9t20wsmd
级联和推测解码是两种常见的提高语言模型推理效率的方法。两者皆通过交替使用两个模型来实现,但背后机制迥异:级联使用延迟规则,仅在遇到「困难」输入时调用较大的模型,而推测解码则通过推测执行,主要并行调用较大的模型进行评分。这些机制提供了不同的优势:在经验上,级联提供了有说服力的成本-质量权衡,甚至常常优于大模型;而推测级联则提供了令人印象深刻的加速,同时保证了质量中立性。 在本文中,研究者通过设计新的推测级联技术,将延迟规则通过推测执行来实现,从而结合了这两种方法的优势。他们刻画了推测级联的最佳延迟规则,并采用了最佳规则的插件近似方法。通过在 Gemma 和 T5 模型上进行一系列语言基准测试的实验,结果表明他们的方法较之传统的级联和推测解码基线模型,在成本 - 质量权衡方面更具优势。 杰出论文选取流程
ICLR 官方在博客上简单介绍了他们的杰出论文选取流程。 具体来说,ICLR 2025 杰出论文委员会(Outstanding Paper Committee)采用了一种两阶段遴选流程,目标是展现本次大会上提出的卓越研究成果。 一开始,该委员会获得了一份包含 36 篇论文的清单,这些论文要么由领域主席推荐,要么获得了评审专家的优异评分。委员会成员会先进行初步评审,选出最终入围论文。 之后,所有入围论文再由委员会全体成员审阅,并根据理论洞见、实践影响、写作能力和实验严谨性等因素进行排名。最终由项目主席确认最终决定。 参考链接:https://blog.iclr.cc/2025/04/22/announcing-the-outstanding-paper-awards-at-iclr-2025/
