一文概述 2018 年深度学习 NLP 十大创新思路

AI 科技评论按:Sebastian Ruder 是一位 NLP 方向的博士生、研究科学家,目前供职于一家做 NLP 相关服务的爱尔兰公司 AYLIEN,同时,他也是一位活跃的博客作者,发表了多篇机器学习、NLP 和深度学习相关的文章。最近,他基于十几篇经典论文盘点了 2018 年 NLP 领域十个令人激动并具有影响力的想法,并将文章发布在 Facebook 上。AI 科技评论编译如下:

今年,我发现了 十个令人激动并具有影响力的想法,并将其汇总成了这篇文章。在未来,我们可能还会对它们有更多了解。
对于每个想法,我都挑选 1-2 篇对该想法执行良好的论文。我试图保持这份清单的简洁性,因此如果没有覆盖到所有相关工作,还请大家见谅。这份清单包含主要与迁移学习相关的想法及其概述,不过也必然会带有一定的主观性。其中的大部分(一些例外)并不是一种趋势(但我预测其中的一些想法在 2019 年会变得更具趋势性)。最后,我希望在评论区中看到你的精彩评论或者其他领域的精彩文章。
1)无监督的机器翻译翻译(Unsupervised MT)
ICLR 2018 收录的两篇关于无监督机器翻译翻译的论文(https://arxiv.org/abs/1710.11041)中,无监督机器翻译的整个过程的表现好得让人感到惊讶,但结果却不如监督系统。在 EMNLP 2018,两篇同样来自这两个团队的论文(https://arxiv.org/abs/1809.01272)显著改进了之前的方法,让无监督的机器翻译取得了进展。代表性论文:
《基于短语和神经的无监督机器翻译》(EMNLP 2018)
Phrase-Based & Neural Unsupervised Machine Translation
论文地址:https://arxiv.org/abs/1804.0775
这篇论文很好地为无监督机器翻译提取了三个关键要求:良好的初始化、语言建模以及你想任务建模(通过反向翻译)。我们在下文中会看到,这三项要求同样对其他的无监督场景有益。反向任务建模要求循环的一致性,其已在不同方法(尤其是 CycleGAN,https://arxiv.org/abs/1703.10593)中得到应用。这篇论文甚至在两个低资源语言对——英语-乌尔都语以及英语-罗马尼亚语上进行了广泛的实验和评估。未来我们有希望看到更多针对资源匮乏类语言的工作。
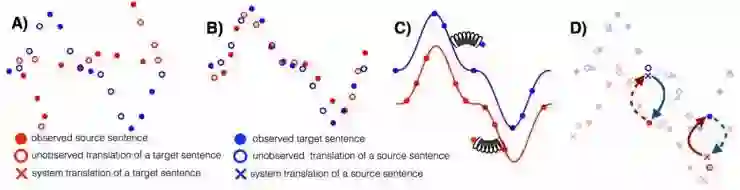
无监督机器翻译三项原则的插图说明:A)两个单语数据集;B)初始化;C)语言建模;D)反向翻译 (Lample et al., 2018)。
2)预训练的语言模型(Pretrained language models)
使用预训练的语言模型可能是今年最重要的 NLP 趋势,因此我在这里就不过多描述。针对预训练的语言模型,这里有很多让人印象深刻的方法:ELMo(https://arxiv.org/abs/1802.05365), ULMFiT(https://arxiv.org/abs/1801.06146)、 OpenAI Transformer 以及 BERT(https://arxiv.org/abs/1810.04805)。代表性论文:
《深度的语境化词语表示》(NAACL-HLT 2018)
《Deep contextualized word representations》
论文地址:https://arxiv.org/abs/1802.05365
这篇论文介绍了 ELMo,颇受好评。除了实证结果让人印象深刻,这篇论文的详细的分析部分也非常显眼,该部分梳理了各类因素的影响,并且分析了在表示中所捕获的信息。词义消歧(WSD)分析自身(下图左)也执行得很好。这两者都表明,机器学习本身就提供了接近最新技术的词义消歧和词性标注性能。
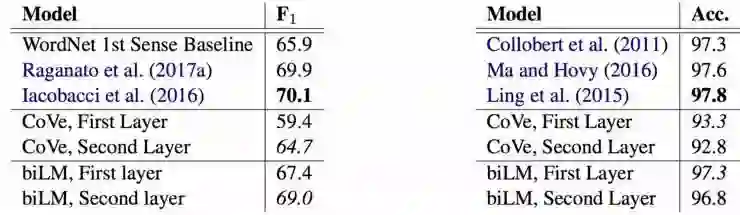
与基线相比的第一层和第二层双向语言模型的词义消歧(左)和词性标注(右)结果(Peters et al., 2018)。
3)常识推理数据集(Common sense inference datasets)
将常识融入模型是向前发展的最重要方向之一。然而,创建好的数据集并不容易,甚至最常用的那些好的数据集还存在很大的偏差。今年出现了一些执行良好的数据集,它们试图教模型一些常识,比如同样都源自华盛顿大学的 Event2Mind(https://arxiv.org/abs/1805.06939)和 SWAG(https://arxiv.org/abs/1808.05326)。其中,SWAG 学到常识的速度出乎意料地快。代表性论文:
《视觉常识推理》(arXiv 2018)
Visual Commonsense Reasoning
论文地址:http://visualcommonsense.com/
这是第一个包含了每个答案所对应的基本原理(解释)的视觉 QA 数据集。此外,问题要求复杂的推理。创建者通过确保每个答案正确的先验概率为 25%(每个答案在整个数据集中出现 4 次,其中,错误答案出现 3 次,正确答案出现 1 次)来不遗余力地解决可能存在的偏差;这就要求使用计算相关性和相似性的模型来解决约束优化问题。我希望,在创建数据集时预防可能的偏倚可以成为未来研究人员们的常识。最终,看看数据精彩地呈现出来就可以了。

VCR:给定一张图片、一个区域列表和一个问题,模型必须回答这个问题,并给出一个可解释其答案为何正确的理由。 (Zellers et al., 2018).
4)元学习(Meta-learning)
元学习已在小样本学习、强化学习和机器人技术中得到广泛应用——最突出的例子是与模型无关的元学习(MAML,https://arxiv.org/abs/1703.03400),但其很少在 NLP 中得到成功应用。元学习对于训练示例数量有限的问题非常有用。代表性论文:
《低资源神经机器翻译的元学习》(EMNLP 2018)
Meta-Learning for Low-Resource Neural Machine Translation
论文地址:http://aclweb.org/anthology/D18-1398
作者使用 MAML 方法学习翻译的良好初始化,将每一个语言对都视为单独的元任务。适应低资源语言对,可能是对 NLP 中的元学习最有用的设置。特别地,将多语种迁移学习(例如多语种 BERT,https://github.com/google-research/bert/blob/master/multilingual.md)、无监督学习和元学习结合起来是一个有前景的研究方向。
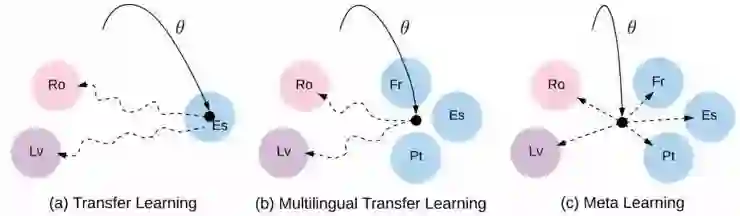
迁移学习、多语言迁移学习与元学习之间的区别。 实线:初始化学习。 虚线:调整路径 (Gu et al., 2018).
5)稳健的无监督方法(Robust unsupervised methods)
今年,我们(http://aclweb.org/anthology/P18-1072)和其他研究者(http://aclweb.org/anthology/D18-1056)都已经观察到,当语言不同时,无监督的跨语言词向量方法就会失效。这是迁移学习中的常见现象,其中源和目标设置(例如,域适应中的域 https://www.cs.jhu.edu/~mdredze/publications/sentiment_acl07.pdf、连续学习https://arxiv.org/abs/1706.08840 和多任务学习 http://www.aclweb.org/anthology/E17-1005 中的任务)之间的差异会导致模型的退化或失败。因此,让模型对于这些变化更加稳健非常重要。代表性论文:
《用于完全无监督的跨语言词向量的稳健自学习方法》(ACL 2018)
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
论文地址:http://www.aclweb.org/anthology/P18-1073
该论文利用他们对问题的理解来设计更好的初始化,而不是在初始化上应用元学习。特别地,他们将两种语言中与相似词具有相似的词分布的词进行配对。这是利用领域专业知识和分析见解来使模型变得更稳健的非常好的案例。
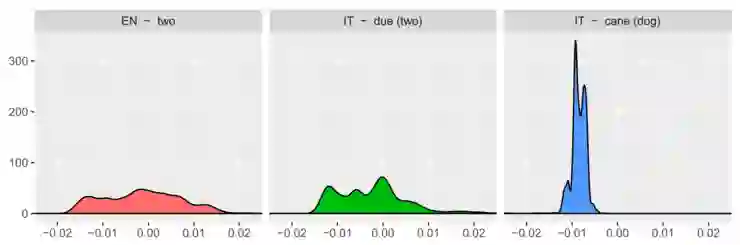
三个词的相似度分布。 等效翻译(「two」和「due」)的分布比非相关词(「two」和「cane」——意思是「dog」)的分布更为相似。(Artexte et al., 2018)
6)理解表示(Understanding representations)
研究者们未来更好地理解表示,已经做了很多努力。特别是「诊断分类器」(diagnostic classifiers,https://arxiv.org/abs/1608.04207)(旨在评估学习到的表示能否预测某些属性的任务) 已经变得非常常用(http://arxiv.org/abs/1805.01070)了。代表性论文:
《语境化词向量解析:架构和表示》(EMNLP 2018)
Dissecting Contextual Word Embeddings: Architecture and Representation
论文地址:http://aclweb.org/anthology/D18-1179
该论文对预训练语言模型表示实现了更好的理解。作者在精心设计的无监督和有监督的任务上对词和跨度表示进行了广泛的学习研究。结果表明:预训练的表示可以在较低的层中学习到低级形态和句法任务相关的任务,并且可以在较高的层中学习到更长范围的语义相关的任务。
对我来说,这个结果真正表明了,预训练语言模型确实捕获到了与在 ImageNet 上预训练的计算机视觉模型(https://thegradient.pub/nlp-imagenet/)相类似的属性。

BiLSTM 和 Transformer预训练表示在词性标注、选区分析和无监督共指解析((从左到右)上每层的性能。 (Peters et al., 2018)
7)巧妙的辅助任务(Clever auxiliary tasks)
在许多场景下,我们看到研究者越来越多地将精心挑选的辅助任务与多任务学习一起使用。一个好的辅助任务来说,它必须是易于获取数据的。最重要的例子之一是 BERT(https://arxiv.org/abs/1810.04805),它使用下一个句子的预测(该预测方法在 Skip-thoughts,https://papers.nips.cc/paper/5950-skip-thought-vectors.pdf 以及最近的 Quick-thoughts,https://arxiv.org/pdf/1803.02893.pdf 中应用过)来产生很大的效果。代表性论文:
《语义结构的句法框架》(EMNLP 2018)
Syntactic Scaffolds for Semantic Structures
论文地址:http://aclweb.org/anthology/D18-1412
该论文提出了辅助任务,它通过预测每个跨度对应的句法成分类型,来对跨度表示进行预训练。辅助任务虽然在概念上非常简单,但它为语义角色标注和共指解析等跨级别预测任务带来了大幅的改进。这篇论文表明,在目标任务(这里是指跨度任务)所要求的级别上所学到的特定的表示是效益巨大的。
pair2vec:用于跨句推理的组合词对嵌入(arXiv 2018)
pair2vec: Compositional Word-Pair Embeddings for Cross-Sentence Inference
论文地址:https://arxiv.org/abs/1810.08854
类似地,本论文通过最大化词对与其语境间的点互信息(pointwise mutual information),来对词对表示进行预训练。这就激励了模型学习更有意义的词对表示,而不使用语言建模等更通用的目标。在 SQuAD 和 MultiNLI 等要求跨句推理的任务中,预训练表示是有效的。
我们可以期望未来,看到更多的预训练任务,能够捕获特别适用于某些下游任务的属性,并且能够与语言建模等更多通用任务相辅相成。
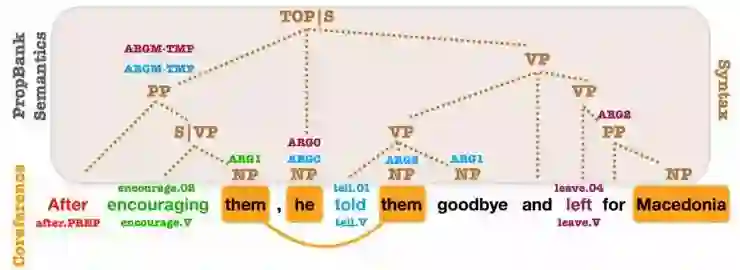
OntoNotes的句法、PropBank和共指注释。PropBank SRL参数和共指提及被标注在了句法成分的顶部。几乎每一个参数都与一个句法成分有关。 (Swayamdipta et al., 2018)
8)半监督学习和迁移学习相结合(Combining semi-supervised learning with transfer learning)
伴随着迁移学习的最新进展,我们不应该忘记使用特定的目标任务数据的更明确的方法。事实上,预训练表示与许多半监督学习方法是相辅相成的。我们已经探索了一种半监督学习的特殊方法——自我标注的方法(http://aclweb.org/anthology/P18-1096)。代表性论文:
《基于交叉视点训练的半监督序列建模》(EMNLP 2018)
Semi-Supervised Sequence Modeling with Cross-View Training
论文地址:http://aclweb.org/anthology/D18-1217
这篇论文表明,一个能确保对输入的不同视点的预测与主模型的预测一致的概念上非常简单的想法,可以在大量的任务上得到性能的提高。这个想法与词 dropout 类似,但允许利用未标记的数据让模型变得更稳健。与 mean teacher(https://arxiv.org/abs/1703.01780)等其他自集成模型相比,它是专门针对特定的 NLP 任务设计的。
随着对半监督学习的研究越越来越多,我们将有望看到有更多明确地尝试对未来目标预测进行建模的研究工作。
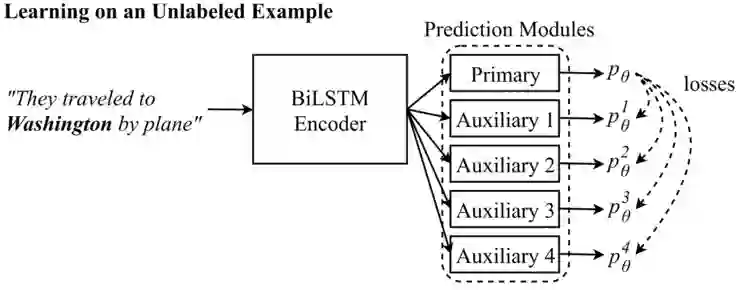
辅助预测模块看到的输入:辅助1 :They traveled to __________________. 辅助2:They traveled toWashington _______. 辅助3: _____________ Washingtonby plane.辅助4:_____________ by plane。 (Clark et al., 2018)
9)大型文档的问答和推理(QA and reasoning with large documents)
随着一系列新的问答(QA)数据集(http://quac.ai/)的出现,问答系统有了很大的发展。除了对话式问答和多步推理,问答最具挑战性的方面是对叙述和大体量信息进行合成。代表性论文:
《叙述答阅读理解挑战》(TACL 2018)
The NarrativeQA Reading Comprehension Challenge
论文地址:http://aclweb.org/anthology/Q18-1023
这篇论文基于对完整的电影剧本和书籍的提问和回答,提出了一个具有挑战性的新的问答数据集。虽然依靠当前的方法还无法完成这项任务,但是模型可以选择使用摘要(而不是整本书籍)作为选择答案(而不是生成答案)的语境。这些变体让任务的实现更加容易,也使得模型可以逐步扩展到整个语境设置。
我们需要更多这样的数据集,它们能体现具有挑战性的问题,并且有助于解决这些问题。
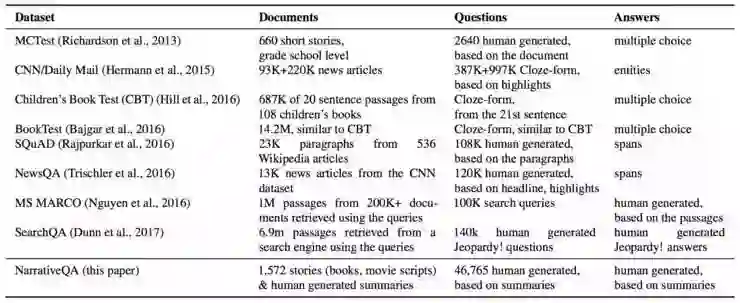
QA 数据集比较
10)归纳偏差(Inductive bias)
CNN 中的卷积、正则化、dropout 以及其他机制等归纳偏差,是神经网络模型的核心部分,它们充当调节器的角色,使模型更具样本效率。然而,提出一个应用更加广泛的归纳偏差方法,并将其融入模型,是具有挑战性的。代表性论文:
《基于人类注意力的序列分类》(CoNLL 2018)
Sequence classification with human attention
论文地址:http://aclweb.org/anthology/K18-1030
这篇论文提出利用视觉跟踪语料库中的人类注意力,来 RNN 中的注意力进行规则化处理。鉴于 Transformer 等当前许多模型都使用注意力这一方法,找到更有效得训练它的方法是一个重要的方向。同时,论文还证明了另外一个案例——人类语言学习可以帮助改进计算模型。
《语义角色标注的语言学信息的自我注意力》(EMNLP 2018)
Linguistically-Informed Self-Attention for Semantic Role Labeling
论文地址:http://aclweb.org/anthology/D18-1548
这篇论文有很多亮点:一个在句法和语义任务上进行联合训练的 Transformer 模型;在测试时注入高质量语法分析的能力;以及域外评估。论文还通过训练注意力头来关注每个标注的句法 parents,来使转换器的多头注意力统一对句法更加敏感。
未来我们有望看到更多针对输入特定场景,将 Transformer 注意力头用作辅助预测器的案例。

PropBank语义角色标注的十年。语言学信息的自我注意力( LISA )与其他域外数据方法的比较。 (Strubell et al., 2018)
Via:http://ruder.io/10-exciting-ideas-of-2018-in-nlp/,AI 科技评论编译。

点击 阅读原文 ,查看 对话吴恩达、Yann LeCun: AI 2018 年的里程碑以及 2019 年的预测




