KDD20 | 对比学习和负采样技术专题


2.1 动机
本文着眼于图上的预训练任务,即事先在几个规模较大的数据集上进行学习(pre-training),之后在下游的数据集以及相应的任务上进行微调(fine-tuning)。当前的图表示学习工作面临如下两个问题:
绝大部分的工作都聚焦于某一张或几张图,只能捕某一网络特定的结构,不具备可迁移性。
研究预训练的文章也通常聚焦于某一领域(例如,化学分子),或是设计很多启发式的任务,不具备通用性。
为了解决上述问题,文章提出利用对比学习,通过节点的局部结构来将它们加以区分;此外,本文并不限制对比的节点是否来自于同一张图,这样使得编码器能够参考各种图上的结构,学得更广泛意义上的结构表示。
2.2 模型
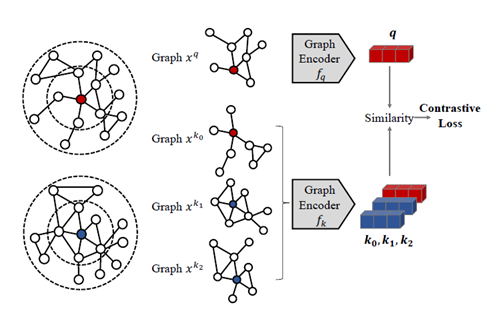
2.2.1 如何设计图中的对比实例
本文的预训练模型仅仅关注于结构上的表示,而无需额外输入属性。因此,本文将每个节点的r-ego网络作为该节点的实例。r-ego网络,指的是某个节点的r阶以内的所有节点构成的子图,可代表该节点的局部结构。本文将每个r-ego网络都当做独立的类,并鼓励编码器能够从不相似的实例中区分出相似的实例。
2.2.2 如何定义相似或不相似的实例
本文将每个r-ego网络进行两次不同的随机增广,并将同一个r-ego网络的增广视为相似实例,否则就视为不相似实例。其采取的随机增广方式为:对于某一个r-ego网络来说,在该子图内进行两次随机游走,并将游走得到的子图中的节点重新标号,防止根据两个实例的中心节点的序号是否一致来判别是否相似。
2.2.3 如何选择图编码器
对比学习的通常范式是:对于给定的query实例 ,在众多的key实例中找出匹配 的当做正例,其余为负例。本文用两个独立的GIN模型分别编码query实例和key实例,得到相应的表示。由于本文聚焦于网络结构,因此利用网络结构对节点特征初始化,分为三部分:广义的位置表示、节点度的one-hot编码、是否为中心节点的二进制指示。通过GIN编码得到的向量最终利用L2正则化,得到最终节点表示。
2.2.4 GCC学习
在对比学习中,key实例的数量是至关重要的。一般而言,key实例越多效果越好,但是也会更影响效率。对此,本文采用两种模式:第一种是端到端(E2E)模式,即每次训练都更新query编码器和key编码器;第二种是MoCo模式,即每次只更新query编码器,而key编码器采用动量更新,这样能够利用更多的key来帮助训练。
2.2.5 GCC微调过程
下游任务主要分为图级别的和节点级别的任务:图级别的任务直接用GIN的输出作为图的表示,节点级别的任务利用GIN对r-ego网络的编码作为中心节点的表示。依据是否在微调过程中训练GIN,本文又分了Freezing和full fine-tuning模式。作为一种关注节点局部的算法,GCC能扩展到大规模数据集以及分布式计算上。
2.3 实验
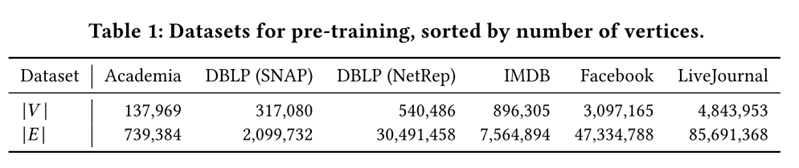
GCC首先在以下六个数据集上进行了预训练,前三个是学术网络,后三个是社交网络。
接着本文节点分类、图分类和相似性搜索,三个任务上做了实验,其结果如下:
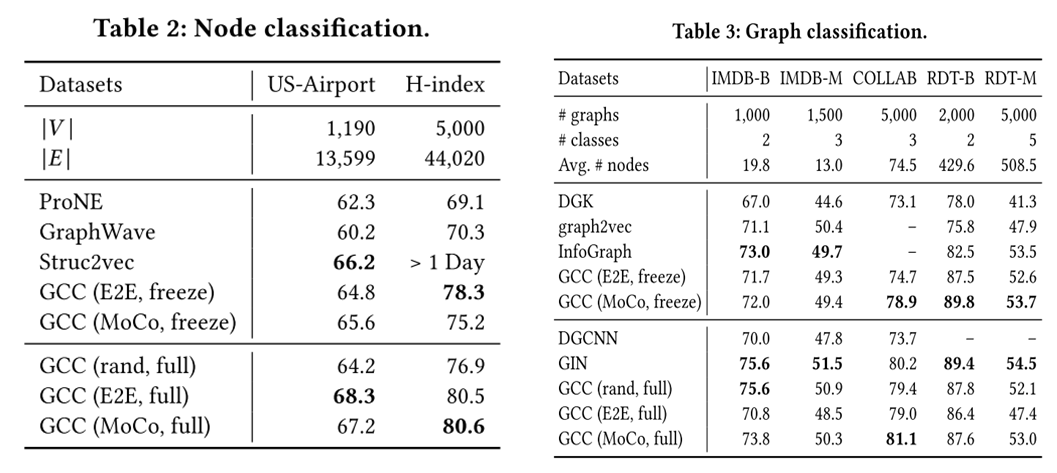
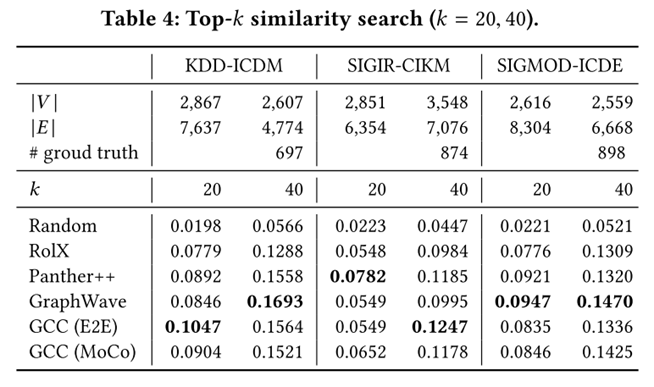
可以看出,经过预训练的编码器可直接应用于新的数据集和未知的下游任务,并且能够和直接在相应数据集上训练的模型取得同样好的效果。
这证明了,在图与图之间有可迁移的结构模式,而本文GCC模型能够很好地将其捕捉。
文章的最后也做了其他的消融实验,包括E2E和MoCo两种模式下key实例数量对效果的影响,以及预训练数据集的多少对效果的影响。
结果证明,MoCo模式能够在更少的时间内利用更多的key实例,而预训练模型的数量和效果也近乎呈正比线性关系。
3 理解图表示学习中的负采样

3.1 动机
对于图表示学习来说,采样技术(sampling)通常扮演着重要的角色。采样包括对于正样本的采样和对负样本的采样。对于前者,已经有很多论文进行讨论,定义了不同类型的真样本;而对于如何选取负样本,目前的传统做法是按照节点度的3/4次幂进行采样,并没有进一步地研究。
基于此,本文通过从目标函数和风险两个角度考察了负采样,提出了负样本的最优分布,并进而提出了全新的负采样策略MCNS。
3.2 模型
3.2.1 统一框架
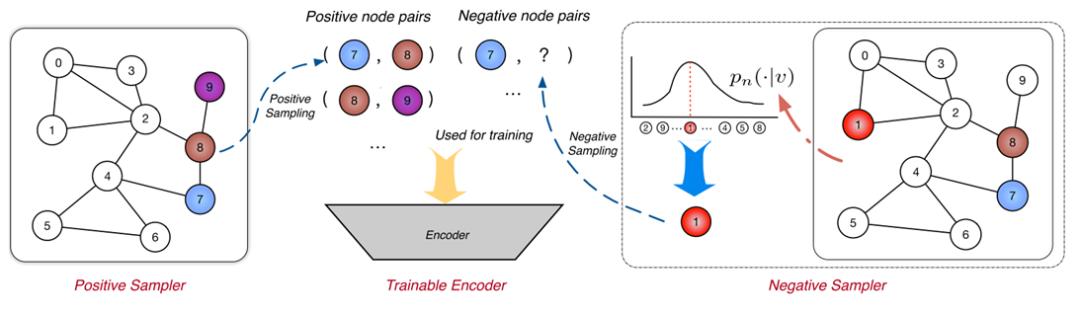
本文首先对一大类图表示学习方法进行了整合,统一成了SampledNCE框架,如上图所示。主要包括三个部分:正样本采集、负样本采集以及编码器。在每一轮的训练中,对于每个节点都采集一个正样本和k个负样本,通过学习使得编码器能够正确将它们区分,学到具有判别性的表示。其损失函数通常为交叉熵损失,内积代表相似程度,而本文提出的方法采用铰链损失。
3.2.2 理解负采样
对于目标函数的影响
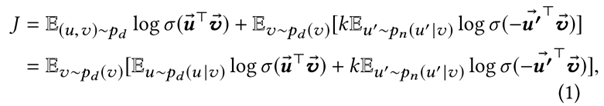
上式中, 代表目标节点, 代表正样本, 代表负样本,相应地 代表正样本分布, 代表负样本分布,k是需要采集的负样本数, 代表sigmoid激活。针对上述的目标函数,本文通过理论证明最优的节点表示应该如下所示:
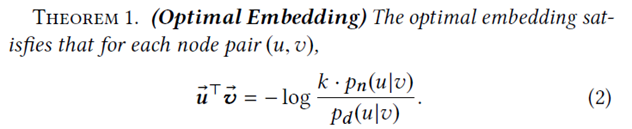
可以看出,正样本分布和负样本分布对于最后的优化同样重要。
对于风险的影响
由于上述的最优表示是在边数量无穷多的情况下得到的,而实际情况往往边的数量非常有限,这就导致实际优化得到的参数 和最优参数 之间是有差距的,其差距大小如下所示:

将上式进行整理简化,得到 和 间的均方误差,或称风险,如下:
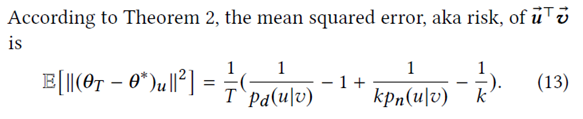
3.2.3 负采样准则
在上述的理论指导下,最佳的负采样分布是两个理论权衡下的结果。其中较为简单直接的是,负样本分布应该和正样本分布呈正相关但是亚线性的关系,即:
接着,本文从单调性和准确性两个角度考察了上述分布的表现。
单调性:从目标函数角度出发,假设已知 ,则会有下式成立:
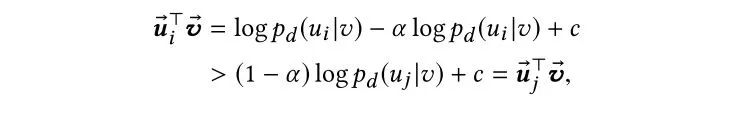
可以看出,概率大的一对样本,它们的内积也更大,符合一般的认知。
准确性:从风险的角度出发,通过第二个理论得知,均方误差的大小取决于 和 中较小的一项。如果某个节点是正例的概率很大,但是是负例的概率很小,那么误差依然会很大。如果选用上述的负样本分布则会得到:
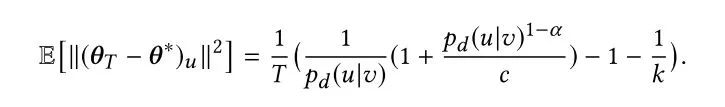
此时,均方误差只和正样本分布呈反比,不会出现上述不稳定的情况,而且使用概率越高的样本对其准确性越高。
3.2.4 MCNS采样策略
根据 ,还需要确定正样本分布 才能应用负采样准则。因此,本文提出self-contrast近似,并用内积代替 ,得到下式:
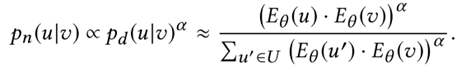
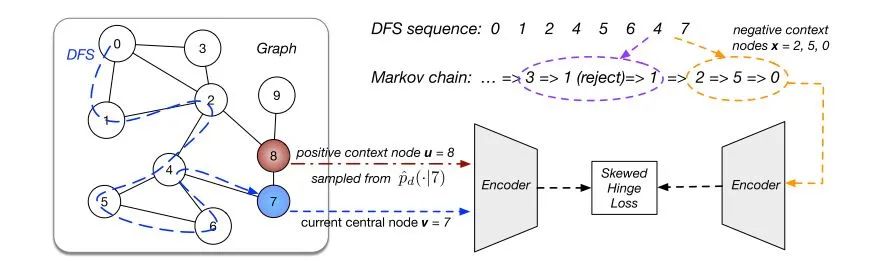
然而由于分母的存在导致对于每个节点来说复杂度都是O(n),效率低下。针对这个问题,Metropolis-Hastings算法通过从提议分布中采样样本,并按照设定的概率接受或拒绝,从而形成了一个样本序列。该序列中的每个样本只和上一时刻的样本有关,因此可构建成马尔科夫链。当样本序列接近无穷时,采样得到的样本就近乎是从真实分布中得到的样本。在此基础上,本文结合了图中固有的局部平滑的特点,进一步加速了该算法:用深度优先算法遍历图中节点,得到相邻节点有边的序列,由于邻居节点间的负样本分布近似相同,因此沿遍历到的序列进行训练时,马尔科夫链可以不断开。具体流程如下图所示(图中对于每个节点采集三个负样本):
3.3 实验
本文在推荐、链路预测和节点分类任务上进行了实验,编码器选择deepwalk、gcn以及graphsage。具体实验结果如下:
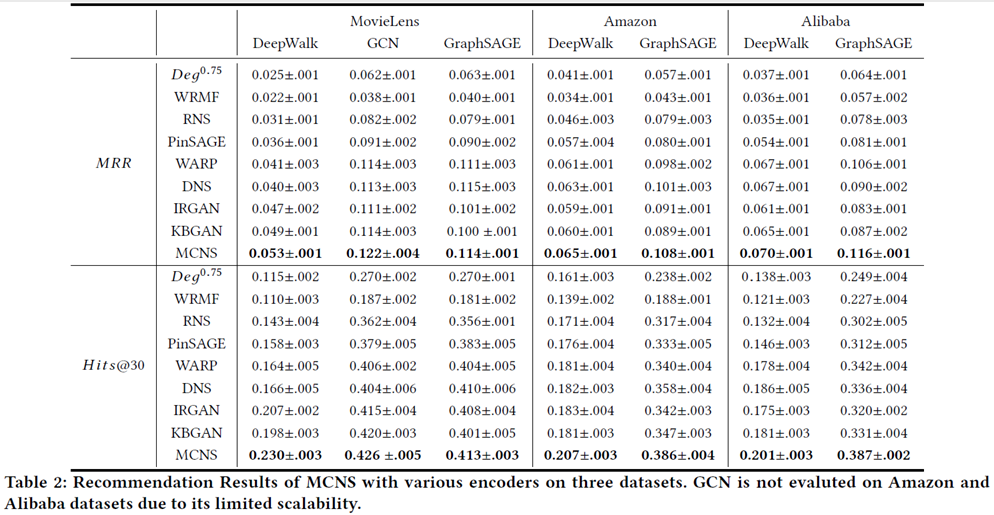
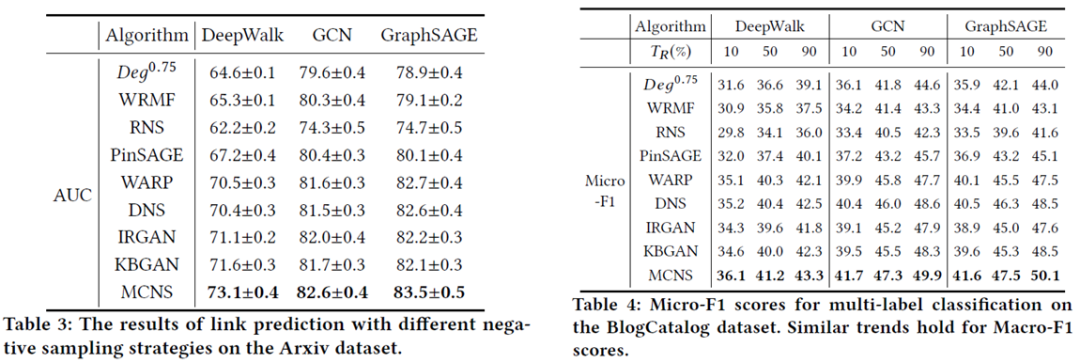
可以看到,和其他主流的负采样策略相比,本文的方法对结果都有着比较明显的提升。
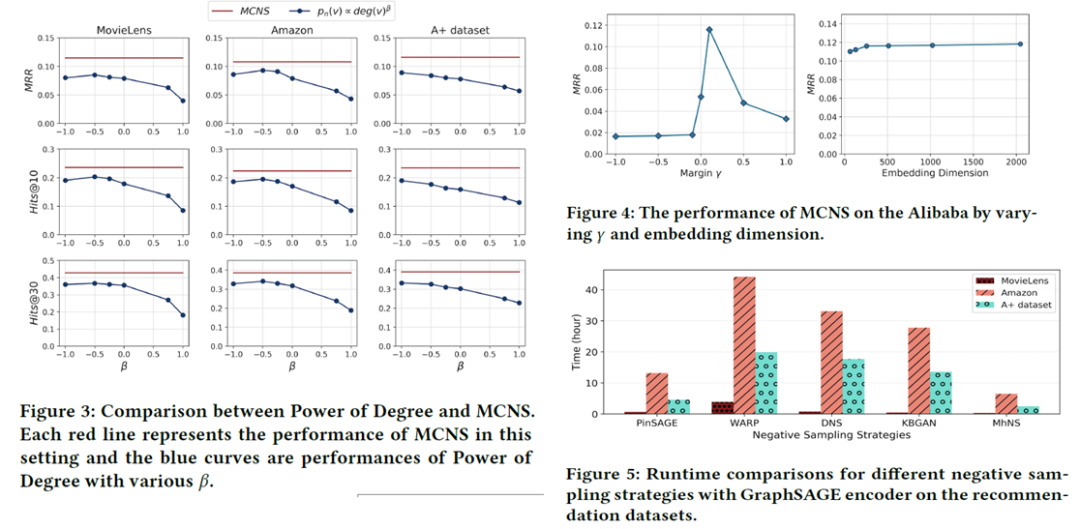
上述三个实验分别对比了本文方法和基于度的采样策略的方法、不同采样策略的所用时间以及铰链损失的参数 和表示维度对结果的影响。
4 总结
本次着重介绍了KDD2020中的对比学习在图预训练中的应用以及可用于对比学习的负采样策略。前者是利用对比学习进行子图级别的判别,着重捕捉图与图之间存在的结构模式,展示了预训练模型在图表示学习中的巨大潜力;后者针对图表示学习,通过相近地理论分析,得出了最优负样本分布应该与正样本分布呈正相关但亚线性的关系,可为对比学习的负样本选择起到一定的指导作用。
参考文献
[1] Yang Z, Ding M, Zhou C, et al. Understanding Negative Sampling in Graph Representation Learning[J]. arXiv preprint arXiv:2005.09863, 2020.
[2] Qiu J, Chen Q, Dong Y, et al. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1150-1160.

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



