
课程描述
本课程深入探讨大语言模型(LLMs),重点关注其设计、训练和使用。课程从注意力机制和Transformer架构开始,随后介绍预训练的实用方面和高效部署,最后讲解提示(prompting)和神经符号学习等高级技术。课程旨在为学生提供批判性分析LLM研究的技能,并将这些概念应用于现实世界中的场景。建议具备扎实的机器学习、编程和深度学习基础。 https://llm-class.github.io/
涉及主题
LLMs 的发展历史 * Transformer 架构 * 模型训练技术 * 提示工程(Prompt Engineering) * 伦理考量和安全措施 * 高级集成技术(例如,RAG、智能体、神经符号学习)
每周安排
第1周: 课程介绍 第2-3周: Transformer架构 第4-5周: 预训练(数据准备、并行化、扩展法则、指令微调、对齐、评估) 第6周: 适应(参数高效的微调技术和设计空间) 第7周: 提示技术 第8周: 快速高效的推理(量化、vLLM框架、Flash Attention、稀疏化/蒸馏) 第9周: RAG 和向量数据库 第10周: 智能体框架 第11周: 神经符号架构 第12周: 课程总结 第13-14周: 项目——构思、设计、实施、评估 第15-16周: 项目——报告与展示
课程目标
在课程结束时,学生将能够: * 分析现代及即将出现的Transformer架构中的设计决策。 * 确定为新任务预训练或微调LLM所需的硬件、软件和数据要求。 * 根据LLM的能力和可靠性,理解其适用场景及其局限性。 * 利用对LLM理论和软件的深入理解,设计提示和围绕LLM的应用。

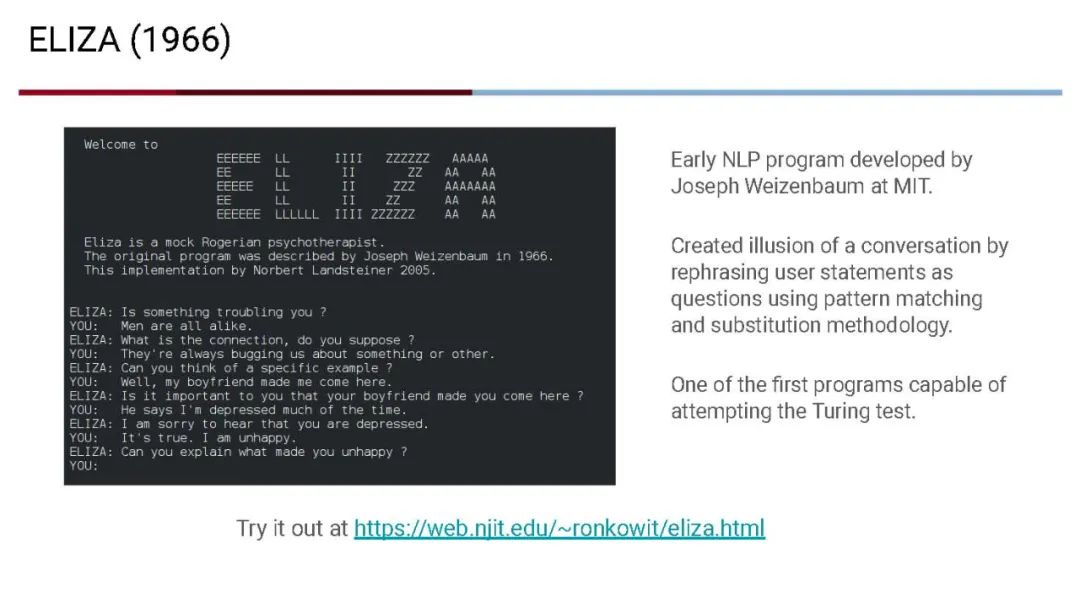
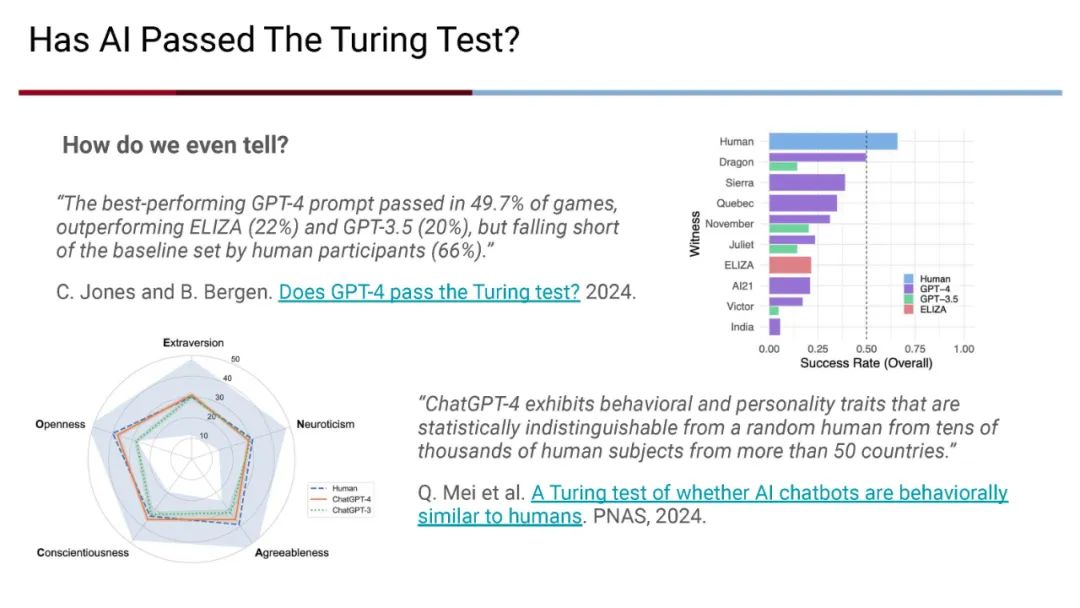


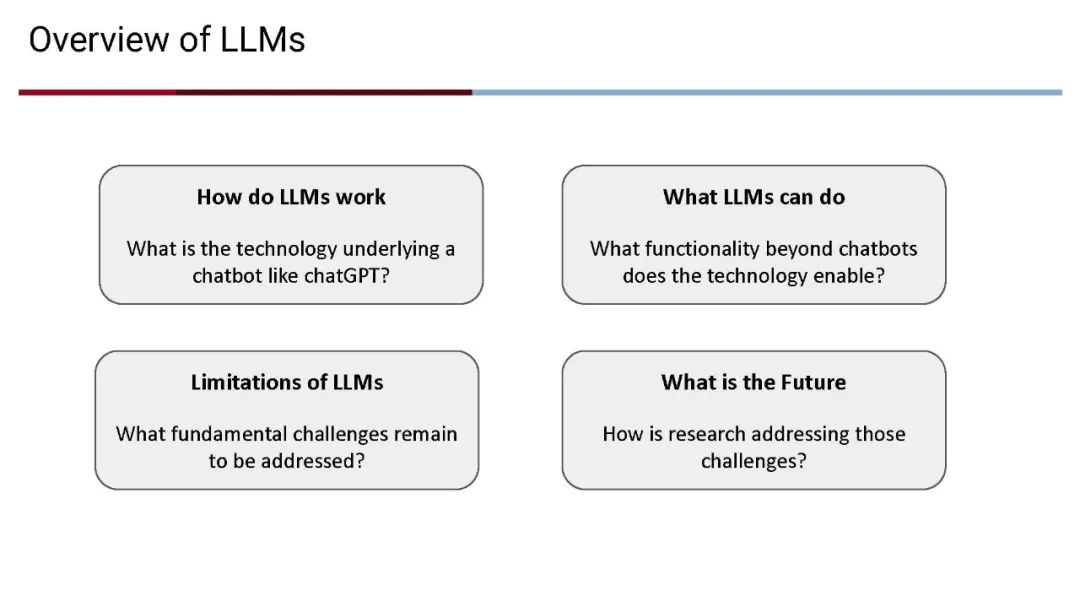

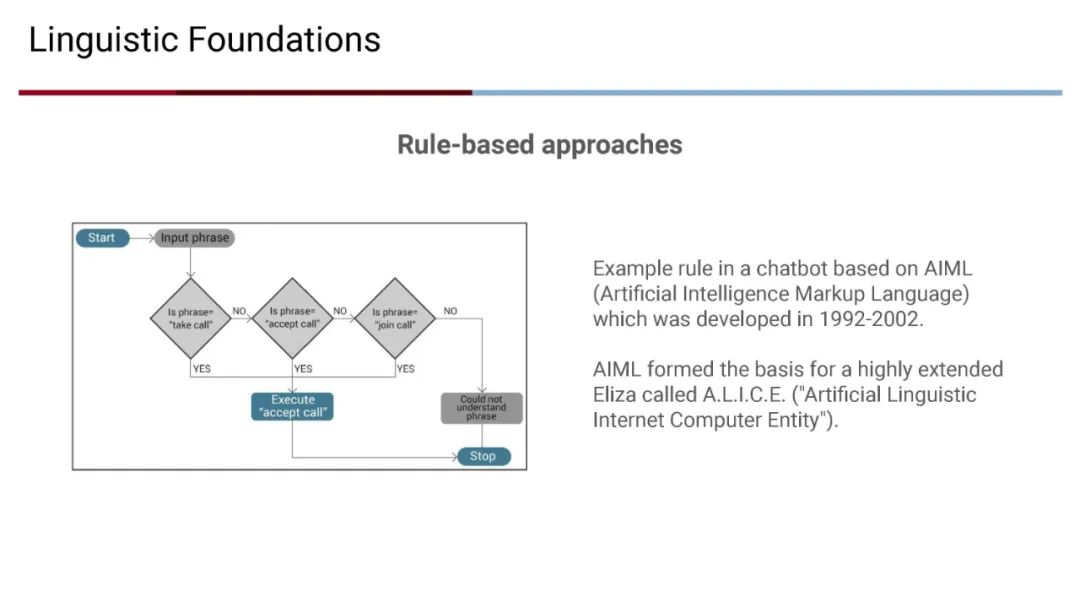
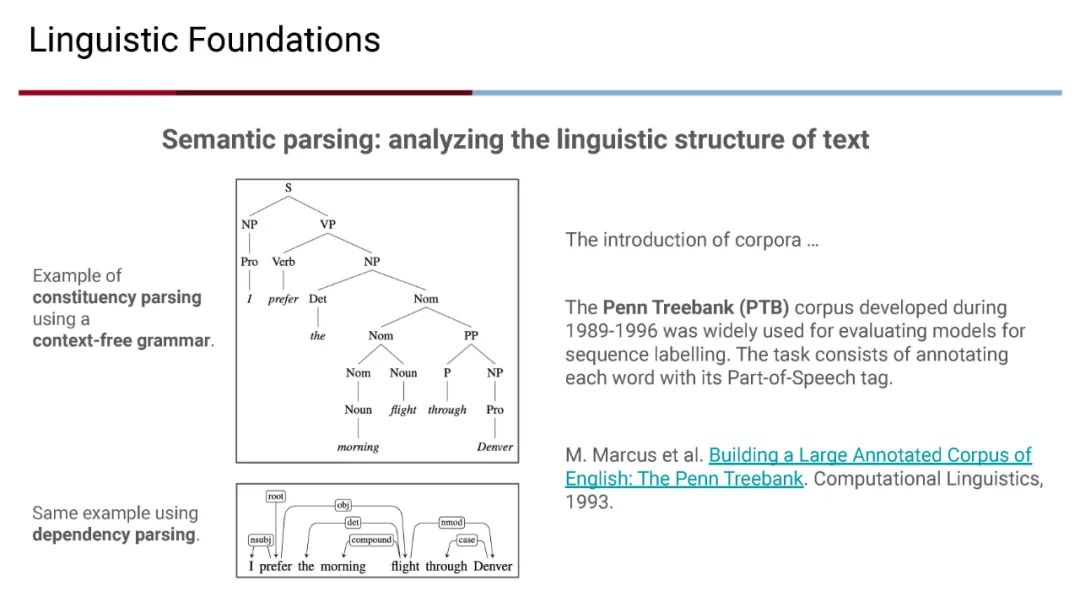
成为VIP会员查看完整内容
相关内容

Arxiv
77+阅读 · 2023年4月4日
Arxiv
136+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
77+阅读 · 2023年4月4日
Arxiv
136+阅读 · 2023年3月29日