摘要——大语言模型(Large Language Models)与自主AI智能体(Autonomous AI Agents)发展迅速,催生了多样化的评估基准、框架和协作协议。然而,该领域仍较为碎片化,缺乏统一的分类体系与全面的综述。因此,本文对2019年至2025年间构建的评估这些模型与智能体的多个领域的基准进行了并列比较。此外,我们提出了一个包含约60项基准的分类体系,涵盖通用与学术知识推理、数学问题求解、代码生成与软件工程、事实依据与信息检索、领域特定评估、多模态与具身任务、任务编排以及交互式评估等方面。 我们还综述了2023年至2025年间提出的AI智能体框架,这些框架通过将大语言模型与模块化工具包集成,实现了自主决策与多步推理能力。进一步地,我们展示了自主AI智能体在材料科学、生物医学研究、学术创意生成、软件工程、合成数据生成、化学推理、数学问题求解、地理信息系统、多媒体、医疗健康与金融等多个真实应用场景中的实际应用。接着,我们综述了关键的智能体间协作协议,包括Agent Communication Protocol(ACP)、Model Context Protocol(MCP)以及Agent-to-Agent Protocol(A2A)。最后,我们针对未来研究提出建议,重点关注高级推理策略、多智能体大语言模型系统中的失败模式、自动化科学发现、基于强化学习的动态工具集成、集成搜索能力以及智能体协议中的安全漏洞。
关键词:大语言模型,自主AI智能体,Agentic AI,推理,评估基准
一、引言
大语言模型(Large Language Models, LLMs),如 OpenAI 的 GPT-4 [1]、Qwen2.5-Omni [2]、DeepSeek-R1 [3] 和 Meta 的 LLaMA [4],通过实现类人文本生成和高级自然语言处理,极大地推动了人工智能的发展,促进了对话智能体、自动内容创作和实时翻译等应用的创新 [5]。近年来的进展进一步扩展了其在多模态任务中的应用,包括文本生成图像和视频,从而拓宽了生成式人工智能的应用边界 [6]。然而,这些模型对静态预训练数据的依赖可能导致输出内容过时或产生虚构信息 [7][8]。为应对这一问题,检索增强生成(Retrieval-Augmented Generation, RAG)通过引入来自知识库、API 或网页的实时数据,提升了生成结果的时效性与准确性 [9][10]。 在此基础上,结合反思、规划与多智能体协作的智能体系统不断演进,催生了“Agentic RAG”系统,这类系统可动态编排信息检索与迭代优化,从而高效处理复杂任务流程 [11][12]。 近年来的大语言模型进步为高度自主的人工智能系统铺平了道路,这些系统可独立完成复杂的科研任务。通常被称为“Agentic AI”的系统能够提出假设、执行文献综述、设计实验、分析数据,从而加速科学发现并降低研究成本 [13][14][15][16]。一系列框架如 LitSearch、ResearchArena 和 Agent Laboratory 被开发出来,以实现科研任务的自动化,包括引用管理与学术综述生成 [17][18][19]。尽管如此,执行领域特定的文献综述及确保自动化流程的可复现性与可靠性仍面临诸多挑战 [20][21]。 在科研自动化发展的同时,基于大语言模型的智能体也开始变革医疗领域 [22]。通过集成临床指南、医学知识库与医疗系统,这些智能体被广泛应用于诊断辅助、患者沟通与医学教育。然而,这些应用仍面临重大挑战,如可靠性、可复现性、伦理治理与安全性等问题 [23][24][25]。解决这些问题对于确保基于LLM的智能体能够有效且负责任地纳入临床实践至关重要,也凸显了建立可靠评估框架以衡量其在不同医疗任务中性能的必要性 [26][27][28]。
基于LLM的智能体正成为人工智能发展的新前沿,能够结合推理与执行,处理复杂的数字环境 [29][30]。因此,研究者提出了多种方法以增强此类智能体,例如通过 React [31] 与蒙特卡洛树搜索(Monte Carlo Tree Search)[32]等方法结合推理与行动,或采用 Learn-by-Interact [33] 等技术生成高质量数据,以规避状态可逆性等假设。其他策略还包括使用人类标注或GPT-4蒸馏数据进行训练,如 AgentGen [34] 与 AgentTuning [35],以生成任务轨迹数据。同时,强化学习方法结合离线算法和基于奖励模型的迭代优化,在真实环境中提升系统的效率与性能 [36][37]。 基于LLM的多智能体系统通过多个专用智能体的集体智能,超越了单智能体系统的能力,能够在模拟复杂现实环境中执行协作规划、讨论与决策。这一方法充分发挥了LLM在沟通与专业知识方面的优势,使不同智能体能够像人类团队一样有效协作,解决复杂问题 [38][39]。近期研究已展示其在多个领域的广泛应用,包括软件开发 [40][41]、多机器人系统 [42][43]、社会模拟 [44]、政策模拟 [45] 和游戏模拟 [46]。 本文的主要贡献如下:
我们提供了2019年至2025年间构建的、涵盖多个领域的大语言模型与自主AI智能体评估基准的比较表; * 我们提出了一个包含约60项基准的分类体系,涵盖通用与学术知识推理、数学问题求解、代码生成与软件工程、事实依据与信息检索、领域特定评估、多模态与具身任务、任务编排、交互式与智能体评估等方向; * 我们整理了2023年至2025年间提出的主流AI智能体框架,这些框架通过模块化工具包集成LLM,实现了自主决策与多步推理; * 我们展示了自主AI智能体在材料科学、生物医学研究、学术创意生成、软件工程、合成数据生成、化学推理、数学问题求解、地理信息系统、多媒体、医疗健康与金融等多个领域的应用; * 我们综述了智能体之间的协作协议,包括Agent Communication Protocol(ACP)、Model Context Protocol(MCP)以及Agent-to-Agent Protocol(A2A); * 我们提出了未来在自主AI智能体研究中的重点方向,包括高级推理策略、多智能体LLM系统中的失败模式、自动科学发现、基于强化学习的动态工具集成、集成搜索能力与智能体协议中的安全漏洞。
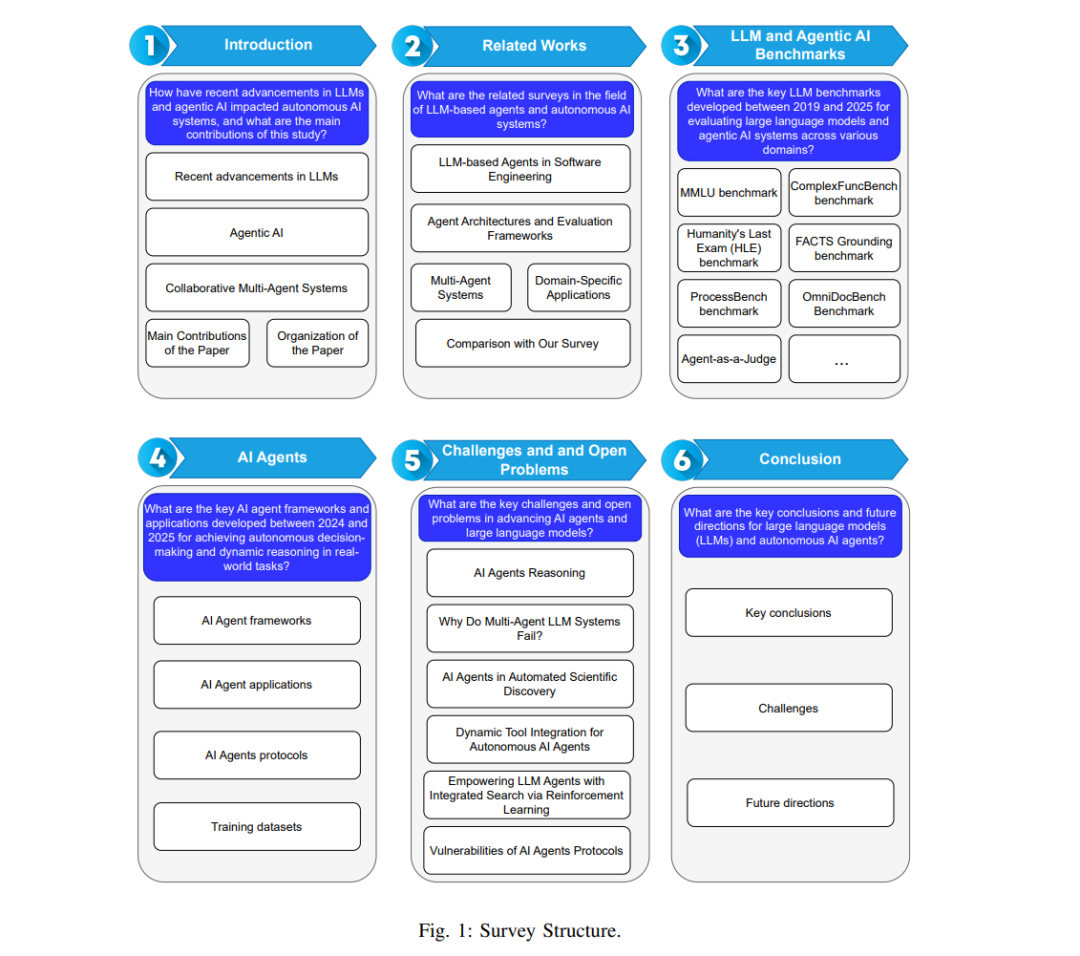
图1展示了本综述的结构安排。第二节介绍相关工作;第三节以表格形式比较当前LLM与Agentic AI的前沿评估基准;第四节系统回顾AI智能体框架、应用、协议与训练数据集;第五节聚焦关键研究方向;第六节为全文总结。