科学发现是一个复杂的认知过程,推动了人类知识和技术进步已有数百年之久。尽管人工智能(AI)在自动化科学推理、模拟和实验方面取得了显著进展,但我们仍然缺乏能够执行自主长期科学研究和发现的综合性AI系统。本文探讨了当前AI在科学发现中的应用现状,重点介绍了近年来在大型语言模型和其他AI技术应用于科学任务中的进展。随后,我们概述了发展更全面的科学发现AI系统所面临的关键挑战和有前景的研究方向,包括对以科学为核心的AI代理的需求、改进的基准和评估指标、多模态科学表示方法,以及结合推理、定理证明和数据驱动建模的统一框架。解决这些挑战可能会催生变革性的AI工具,从而加速各学科领域在科学发现方面的进展。
引言
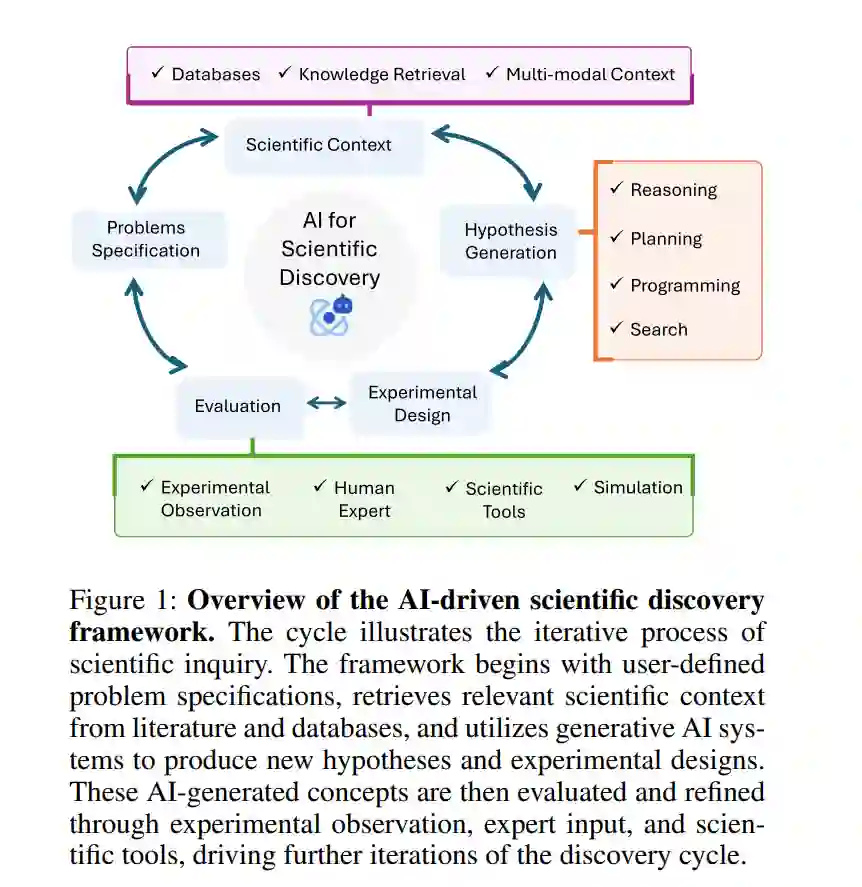
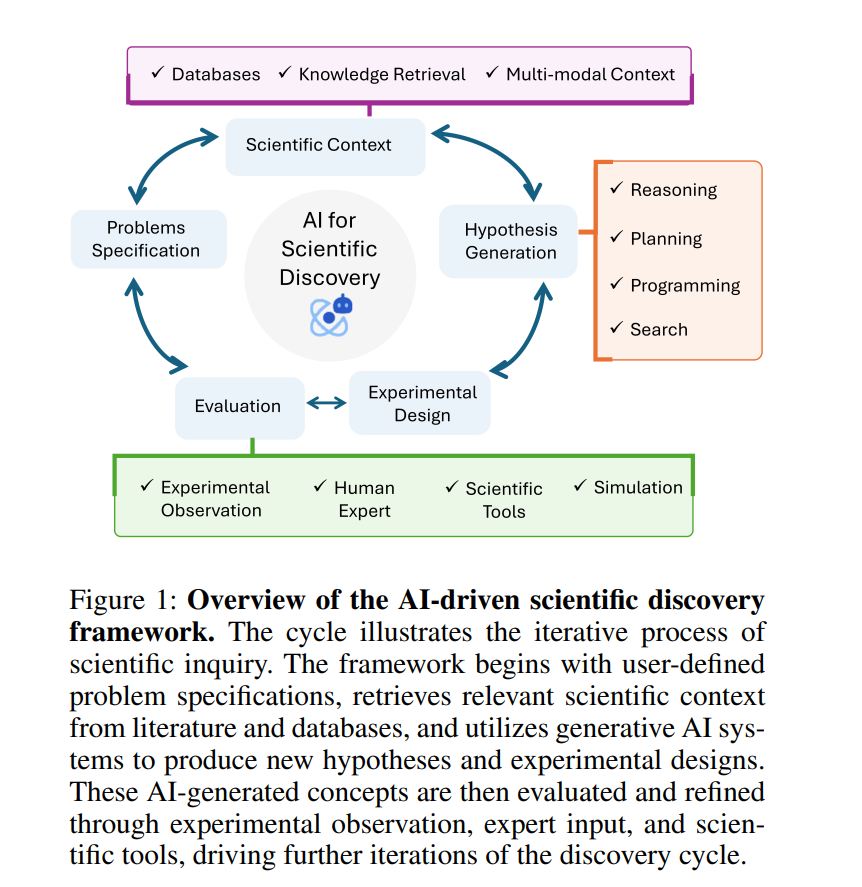
科学发现——即通过提出和验证新概念、规律和理论来解释自然现象——是人类最具知识挑战性和影响力的追求之一。几十年来,人工智能(AI)研究人员一直致力于自动化科学推理和发现的各个方面。早期的工作侧重于符号AI方法,以符号化的形式复制科学假设和规律的形成(Segler, Preuss, and Waller 2018;MacColl 1897)。近年来,深度学习和大型语言模型(LLMs)在文献分析、头脑风暴(Ji et al. 2024;Lu et al. 2024;Si, Yang, and Hashimoto 2024)、实验设计(Boiko et al. 2023;Arlt et al. 2024)、假设生成(Wang et al. 2024;Ji et al. 2024)和方程发现(Shojaee et al. 2024b;Ma et al. 2024)等任务中展现出了巨大的潜力。 尽管取得了这些进展,我们仍然缺乏能够整合涉及持续科学研究和发现的多种认知过程的AI系统。大多数工作集中在单一的科学推理方面,且往往是孤立进行的。开发能够支持科学探究完整周期的更全面的AI发现系统——从上下文检索、假设生成到实验设计和评估(如图1所示)——可能会显著加速科学领域的进展。 本文探讨了生成性AI在科学发现中的当前状态和未来潜力。我们重点介绍了最近的进展,尤其是在科学理解和发现框架方面的进展,并识别了关键的空白。随后,我们概述了朝着更统一的AI发现系统迈进的关键研究挑战和方向,包括:(i)创建改进的科学发现基准和评估框架;(ii)开发利用科学知识和推理能力的科学专用AI代理;(iii)推进超越文本的多模态科学表示;(iv)统一自动推理、定理证明和数据驱动建模。通过解决这些挑战,AI与科学领域的研究者们可以共同推动系统的研发,使其成为人类科学家的协作伙伴,加速科学发现的步伐。
近期AI在科学任务中的进展
过去十年,人工智能(AI)在各类科学任务中的应用取得了显著进展。本节重点介绍一些最重要的近期进展,展示了AI在支持和加速科学发现方面日益增长的能力,涵盖多个学科领域。 文献分析与头脑风暴
随着科学出版物的指数增长,研究人员面临着越来越大的挑战,难以跟上自己领域的最新发展。经过大规模科学语料库预训练的大型语言模型(LLMs),已经成为应对这一挑战的强大工具,提升了文献分析与互动的效率。研究人员已经开发出了适用于多个科学领域的专用LLM模型。例如,PubMedBERT(Gu et al., 2021)和BioBERT(Lee et al., 2020)专注于生物医学文献,而SciBERT(Beltagy, Lo, and Cohan 2019)涵盖了更广泛的科学学科。更近期的模型,如BioGPT(Luo et al., 2022)和SciGLM(Zhang et al., 2024),进一步推动了科学语言建模的边界,结合了先进的架构和训练技术。这些模型通过从PubMed和arXiv等源数据中学习,擅长文献信息检索、摘要和问答任务。它们使得研究人员能够高效地浏览科学知识,快速找到相关论文,提炼关键信息,并综合回答复杂问题。 除了分析,最近的研究还展示了LLMs在生成新科学洞察方面的潜力。例如,SciMON(Ji et al., 2024)使用LLMs通过分析现有文献中的模式来生成新的科学思想。这些进展表明,AI不仅能帮助文献回顾,还能为识别有前景和创新的研究方向做出贡献,可能加速科学发现的步伐。
定理证明
自动定理证明近年来由于其在科学推理中的基础性作用,已成为AI在科学研究中的一个重要领域。近年来,这一领域取得了显著进展,尤其是通过将LLMs与形式化推理系统相结合。GPT-f框架(Polu and Sutskever 2020)开创了这一方法,通过训练基于Transformer的语言模型来学习证明策略,从而在复杂的数学证明过程中借助学习到的先验知识进行导航。基于此,研究人员将证明技术与LLMs结合,开发了如数据增强(Han et al., 2021)、检索增强(Yang et al., 2024)以及新的证明搜索方法(Lample et al., 2022;Wang et al., 2023b)等改进措施。其中一个关键的增强方法是自动形式化方法,代表性的例子是Draft-Sketch-Prove方法(Jiang et al., 2023)。该方法首先利用LLMs草拟非正式证明,将其翻译成正式草图,并使用额外的证明助手工具(Bohme and Nipkow 2010)完成证明,模拟人类从直观理解到严谨证明的过程。随着这些系统在形式化和证明复杂命题方面变得更加高效,它们有可能被应用于推导科学理论,潜在地加速科学过程,并在理论理解滞后于经验方法的领域中带来改进。
实验设计
实验设计是科学过程中至关重要的一部分,通常需要丰富的领域知识和创意思维。通过生成模型自动化这一过程,有望加速各领域的科学发现。研究人员近期利用LLM代理开发了可以设计、规划、优化甚至执行科学实验的系统,且仅需最小的人工干预。这些工具在实验设置成本较高的领域尤为宝贵,使得研究人员在物理实施之前能够探索更广泛的可能性。例如,在物理学领域,基于LLM的系统已在设计复杂的量子实验(Arlt et al., 2024)和优化高能物理模拟的参数(Cai et al., 2024;Baldi, Sadowski, and Whiteson 2014)方面取得了显著成效。在化学领域,LLM代理系统也在自动化实验中取得了进展,可以设计和优化化学反应(M. Bran et al., 2024)。此外,在生物学和医学领域,LLM驱动的实验设计已经在优化基因编辑协议(Huang et al., 2024)和设计更有效的临床试验(Singhal et al., 2023)方面展现了前景。这些AI驱动的实验设计方法使研究人员能够解决更复杂的问题,探索一些由于时间或资源限制而通常无法进行的假设。 数据驱动发现
数据驱动的发现已成为现代科学研究的基石,利用日益增长的实验、观测和合成数据来揭示新的模式、关系和规律。这一范式的转变在复杂系统和高维数据普遍存在的领域尤为具有变革性。 在药物发现领域,数据驱动方法显著加速了潜在治疗化合物的识别。例如,最近的研究采用了生成性(Mak, Wong, and Pichika 2023;Callaway 2024)和多模态表示学习(Gao et al., 2024)模型,通过在表示空间中搜索和筛选数百万分子,发现了一种新的抗生素,对广泛的细菌有效(Gao et al., 2024)。这些进展展示了AI在探索庞大的化学空间中的潜力,这些空间手工搜索是不可能实现的,尤其是在分子这个庞大且无限的组合空间中。 方程发现,通常被称为符号回归,是一种数据驱动任务,用于从数据中揭示数学表达式。早期的神经网络方法如AI Feynman(Udrescu and Tegmark 2020)展示了仅通过数据重新发现基本物理规律的能力,而后来的研究则结合了物理约束和结构,使模型更加可解释(Cranmer et al., 2020b)。语言建模和表示学习的出现带来了新的可能性。适应符号回归的基于Transformer的语言模型将方程发现视为一个数字到符号的生成任务(Biggio et al., 2021;Kamienny et al., 2022)。这些方法在解码过程中结合了搜索技术(Landajuela et al., 2022;Shojaee et al., 2024a),尽管在有效编码和标记数字数据(Golkar et al., 2023)方面仍面临挑战。最近的研究如SNIP模型(Meidani et al., 2024)也探讨了符号表达式与数字数据之间的多模态表示学习,将方程发现搜索移动到一个低维且平滑的表示空间,从而提高了搜索效率。最近,LLM-SR(Shojaee et al., 2024b)也展示了将LLM用作科学家代理在方程发现的进化搜索中的潜力。这些进展突显了方程发现领域的发展,并具有在将数字数据与AI模型结合、利用先进LLMs的数学推理能力方面进一步改进的巨大潜力。 在材料发现领域,数据驱动方法已导致预测并合成具有所需特性的全新材料(Pyzer-Knapp et al., 2022;Merchant et al., 2023;Miret and Krishnan 2024)。大型生成模型在生成新结构方面取得了显著成功。例如,Merchant et al.(2023)提出了用于材料探索的图网络(GNoME),导致了新稳定材料的发现。这一方法在已知稳定晶体的数量上实现了数量级的提升,展示了AI在扩展我们材料知识库方面的潜力。近期,LLMs也被用于从材料科学的文献中提取信息,生成新型材料组成,并指导实验设计(Miret and Krishnan 2024)。例如,AtomAgents(Ghafarollahi and Buehler 2024a)展示了如何将LLMs集成到材料发现流程中,在合金设计方面显著提高了过程效率。通过结合模式识别和表示学习能力与先进AI模型的推理和泛化能力,我们正在朝着能够不仅分析现有数据,还能提出新的假设以进行跨学科数据驱动发现的系统迈进。
关键挑战与研究机会
**科学发现的基准测试
首先,与典型的机器学习基准测试相比,评估人工智能系统在开放式科学发现中的表现面临着独特的挑战。这个问题对于大型语言模型(LLMs)和其他基础模型尤为突出,这些模型能够在其参数中存储并可能“记住”大量的科学知识(Brown 2020;Bommasani 等人 2021)。目前在科学发现领域的许多基准测试,主要集中在重新发现已知的科学定律或解决教科书式问题。例如,AI Feynman 数据集包含了120个物理方程,需要从数据中重新发现(Udrescu 和 Tegmark 2020;Udrescu 等人 2020),而像 SciBench(Wang 等人 2023c)、ScienceQA(Lu 等人 2022)和 MATH(Hendrycks 等人 2021)等数据集主要评估科学问答和数学问题解决能力。 然而,这些基准测试可能无法捕捉到科学发现过程的复杂性。更为关键的是,它们可能容易被大型语言模型复述或“记住”训练数据中的信息,从而可能高估其真正的发现能力(Carlini 等人 2021;Shojaee 等人 2024b)。正如 Wu 等人(2023)指出的,LLMs往往通过与记忆中的知识进行模式匹配来解决科学问题,而非通过真正的推理或发现。这一担忧还通过研究得到了进一步强调,研究表明 LLMs 可以重现其训练数据中的大量内容(Carlini 等人 2022)。因此,急需更丰富的基准测试和评估框架,以更好地理解基准线与最近方法之间的差距,并识别改进的方向。主要的研究方向包括: * 开发专注于新颖科学发现而非恢复的基准数据集:一个有前景的方法是创建可配置的模拟科学领域,在这些领域中,基础定律和原理可以系统地变化。这将允许在新的场景中测试发现能力,减少模型仅仅复述训练数据中已观察到的记忆信息的风险。例如,M. Bran 等人(2024)使用模拟化学环境评估了人工智能驱动的化学反应新发现。同样,Shojaee 等人(2024b)为不同的科学领域(如材料科学、物理学和生物学)设计了模拟设置,以评估人工智能驱动的科学方程发现。这一研究方向的一个关键挑战是平衡 LLMs 先前的科学知识使用,同时避免简单的复述或记忆。这个平衡对于推动人工智能在科学发现中的作用至关重要。 * 创建多方面的科学发现评估指标:为了全面评估科学发现的能力,我们需要一个多维度的评估框架。关键指标包括: (i) 新颖性:量化已发现的假设或定律与现有知识的差异。可以通过与已知科学文献的对比来衡量(Ji 等人 2024); (ii) 普适性:评估已发现的定律或模型如何预测来自分布外的、未观察到的数据。为此,应该开发测试已发现定律在与训练数据分布明显不同的场景下的基准测试,突显科学理论如何应对新环境的普适性; (iii) 与科学原理的一致性:评估已发现的假设是否与物理学的基本定律或其他成熟的科学知识一致。这可以涉及开发用于科学一致性的形式化验证方法(Cornelio 等人 2023;Cranmer 等人 2020a),以及评估已发现的定律与现有科学理论的兼容性(Liu 等人 2024b)。 * 在基准设计和评估中涉及领域专家:领域专家的参与对于开发有意义的基准和评估人工智能驱动的科学发现至关重要。专家可以在发现过程中提供帮助,例如评估人工智能生成的假设的合理性、新颖性和潜在影响;评估人工智能发现的定律或模型是否与人类可理解的科学原理一致;以及在人工智能驱动的发现过程中提供反馈,促进人类与人工智能的协作发现。通过在基准开发、发现和评估过程中整合领域专家的参与,我们可以确保人工智能驱动的科学发现既在技术上合理,又符合科学界的需求和标准。
**面向科学的智能体
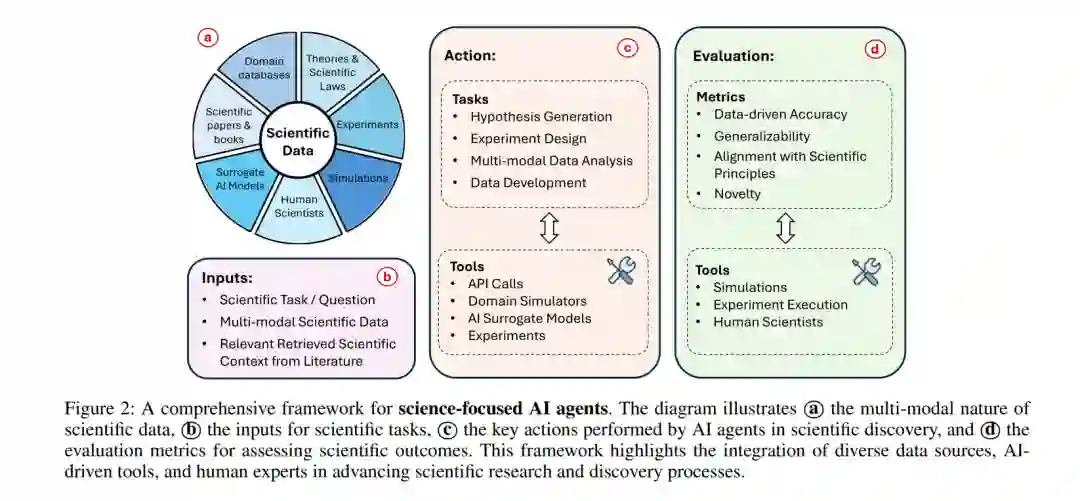
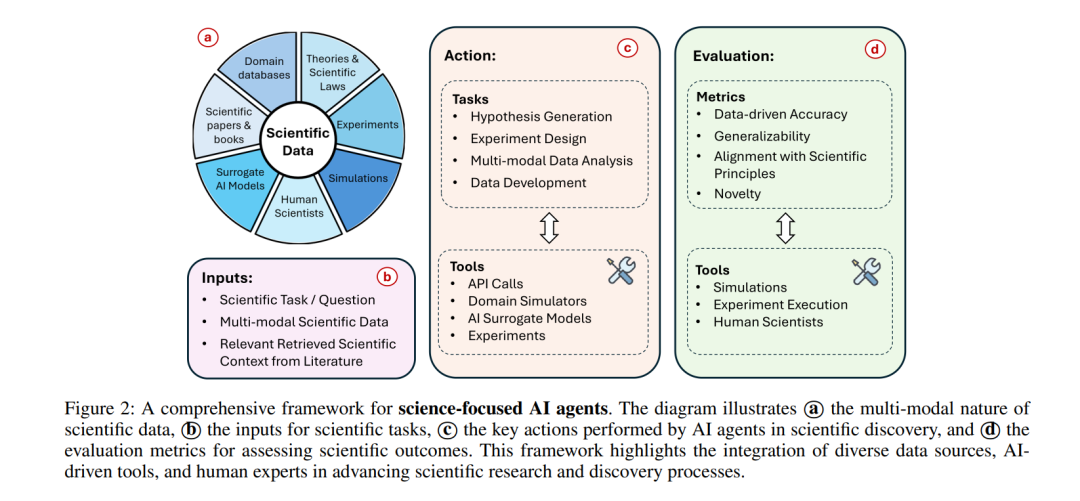
目前的科学人工智能研究通常将模型视为被动工具,而不是主动的追求发现的智能体。开发能够利用广泛科学知识、进行推理并自主验证其推理和假设的面向科学的人工智能智能体(见图2)的需求日益增长。最近,LLMs在知识检索和推理方面展现出了令人印象深刻的能力(Huang 和 Chang 2023),使其成为开发这种智能体的有前景的候选者。这些智能体可以整合嵌入在 LLMs 中的大量科学知识,生成有根据的假设,设计实验,验证其设计,并解释结果。此外,它们与外部工具和实验数据源的接口能力使得现实世界中的实验和验证成为可能。最近的工作已经展示了基于 LLMs 的智能体在科学领域的潜力。例如,M. Bran 等人(2024)介绍了 ChemCrow,这是一个增强型的化学研究系统。ChemCrow 将 GPT-4 与领域特定工具集成,用于预测反应、回溯合成规划和安全评估等任务。这种集成使系统能够对化学过程进行推理,并使用专业的化学工具验证假设。类似地,Ghafarollahi 和 Buehler(2024a)开发了 AtomAgents,这是一个用于合金设计和发现的多智能体系统。SciAgents(Ghafarollahi 和 Buehler 2024b)也使用多个人工智能智能体,每个智能体专注于材料科学的不同方面,共同设计新的生物材料。该系统融入了物理学约束,并能够与模拟工具接口验证预测。然而,开发有效的面向科学的智能体也面临若干挑战: * 领域特定工具集成:有效的科学智能体需要与专业的科学工具和领域特定知识集成。这个挑战源于科学仪器和方法的高度专业化,这些内容通常在 LLMs 的训练数据中表现不足(Bubeck 等人 2023)表明,尽管像 GPT-4 这样的 LLMs 在一般学术任务中表现出色,但它们在物理学和化学等领域的专门科学推理中仍然存在困难。
潜在的研究方向包括开发用于整合领域特定知识库和工具接口的模块化架构,并在精心策划的科学数据集上对 LLMs 进行微调。这些方法可以使 LLMs 访问领域特定知识,并与专业科学工具进行有效互动,从而增强它们在这一环境中的能力。 * 自适应实验设计与假设演化:面向科学的智能体面临的一个重要挑战是,开发能够进行长期、迭代的科学调查的系统。这些智能体必须设计实验、解释结果,并在长期过程中不断完善假设,同时保持科学严谨性,避免偏见。这个挑战源于科学探索的复杂性和多阶段性,通常需要反复进行实验、分析和假设调整。为应对这一挑战的潜在研究方向包括开发元学习框架,使智能体能够在多个调查中改进实验设计和假设精化策略;以及开发层次化规划算法,以管理短期实验步骤和长期科学发现目标。 * 协作科学推理:使人工智能智能体能够进行协作性科学推理对于推动科学进展至关重要。智能体必须在其科学知识基础上进行推理、交流假设、参与讨论,并批判性地评判同行的工作。目前的科学智能体在深度批判分析和识别人工智能驱动的假设和实验设计中的科学缺陷方面存在困难(Birhane 等人 2023)。研究机会包括开发模拟科学社区的多智能体系统,融合领域专家的多智能体精化过程,并创建增强科学对话能力的基准测试,以提升面向科学的智能体的能力。
多模态科学表示
科学数据的领域广泛且多样,包含的内容远不止文本信息。尽管语言模型的最新进展显著提升了我们处理和推理科学文献的能力,但我们必须认识到,大多数科学数据并不是自然语言的形式。从显微镜图像到基因组序列,从时间序列传感器数据到结构化数据库和数学定律,科学知识本质上是多模态的(Topol 2023;Wang 等人 2023a)。这种多样性为人工智能驱动的科学发现提供了挑战,也带来了机会。
结论
开发统一的人工智能系统以推动科学发现是一个雄心勃勃的目标,但其潜在影响极为深远。若成功实现,这一目标有可能在各个科学领域大幅加速进展。本文概述了当前的进展,以及朝着这一愿景迈进的若干关键研究挑战和机会,包括开发面向科学的人工智能智能体、创建改进的基准测试、推进多模态表示和统一多样的科学推理方式。解决这些挑战将需要人工智能研究人员、各领域的科学家以及科学哲学家的协作。尽管完全自主的人工智能科学家可能仍然遥不可及,但短期内的进展可以产生强大的人工智能助手,增强人类的科学能力。这些工具可以帮助科学家导航不断增长的科学文献、集思广益、生成新颖的假设、设计实验,并在复杂的实验数据中发现意想不到的模式。 通过追求这一研究议程,机器学习和人工智能社区有机会开发出不仅仅自动化产品相关任务的系统,而是积极推动人类科学知识前沿的系统。这条道路充满挑战,但其潜在的回报——无论是科学上的还是技术上的——都是巨大的。