

多智能体强化学习(MARL)是一种广泛使用的人工智能(AI)技术。然而,当前的研究和应用需要解决其可扩展性,非平稳性,以及可信度的问题。本文旨在回顾MARL的方法和应用,并指出未来十年的研究趋势和远景。首先,本文总结了MARL的基本方法和应用场景。其次,本文概述了相应的研究方法及其在实际应用MARL时需要解决的安全性,鲁棒性,泛化性,以及伦理约束的局限性。特别地,我们认为,未来十年,可信的MARL将成为热门的研究主题。此外,我们认为考虑人类互动对于MARL在各种社会中的实际应用至关重要。因此,本文还分析了将MARL应用于人机交互时的挑战。
1. 引言
由于其在解决序列决策任务中的巨大潜力,强化学习(RL)得到了广泛的探索[88, 107, 129, 131, 168, 169, 197, 216, 218]。Kaelbling等人在1996年指出[76],RL将在游戏和机器人技术中得到广泛应用。Mnih等人[130]提出深度强化学习(DRL),将具有推理能力的强化学习和具有代表性能力的深度学习(RL)结合起来,训练出的智能体在各种雅达利游戏中的表现超过了人类玩家。Silver等人在2007年使用RL解决围棋游戏[180],并在2016年提出使用深度神经网络和蒙特卡洛树搜索的AlphaGo[179]。在机器人技术方面,DRL也取得了如四足运动[92, 233]等突出的发展。最新的ChatGPT在全世界范围内都是众所周知的,并且使用了与RL相关的技术。自DRL提出以来的20年间,游戏和机器人技术的研究兴趣一直在不断提高。RL的前瞻性应用总结在[76]中。
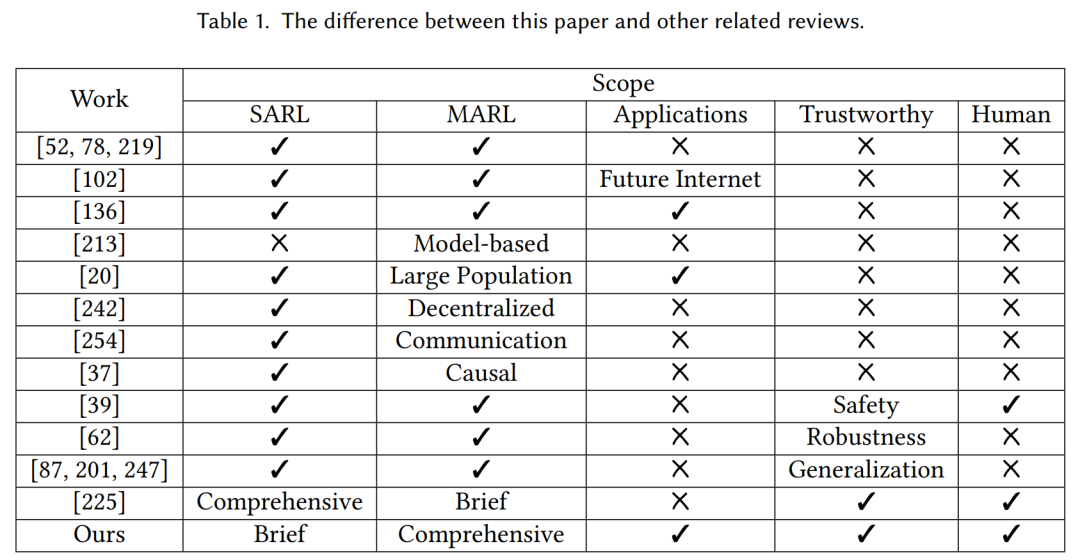
在整合人类因素时,我们需要考虑的不仅仅是智能体的协作,还要考虑智能物理信息系统与人类文明的互动。在将MARL应用于人机交互时,我们提出了四个挑战:由于人类干预而产生的非马尔可夫性质,人类行为的多样性,复杂的异质性,以及多人多机的可扩展性。本文与其他相关综述的区别列在表1中。本文的大纲显示在图1中。接下来的这个调查组织如下。在第2部分,我们给出了MARL的相关定义,并总结了典型的研究方法。第3部分展示了MARL的具体应用场景。第4部分总结了可信MARL的定义、相关研究和局限性。在第5部分,我们指出了人类兼容的MARL面临的挑战。第6部分对整篇文章进行了总结。
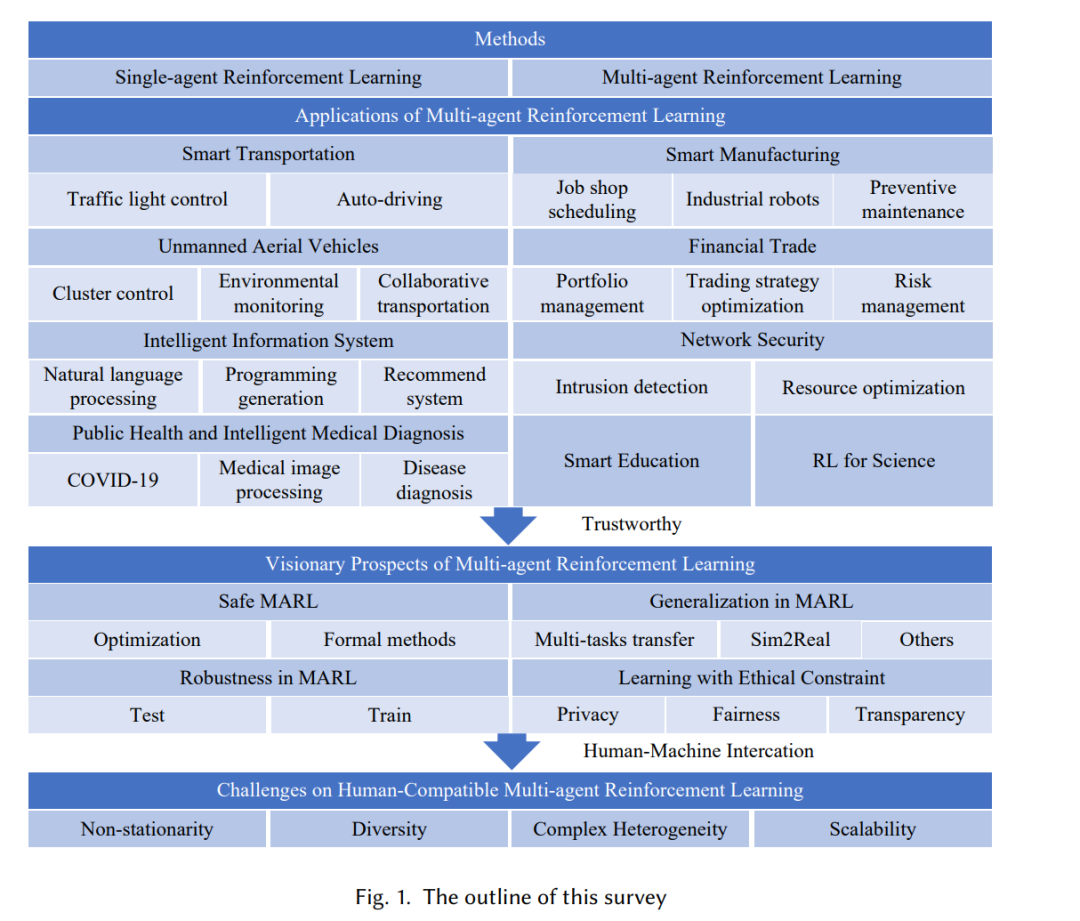
2. 方法
强化学习(RL)智能体旨在通过与环境的尝试和错误交互,最大化总的折扣预期奖励。马尔可夫决策过程(MDP)有助于为序列决策定义模型。在多智能体系统(MAS)中,每个智能体都通过与环境的尝试和错误接触解决序列决策问题。然而,它比单智能体场景更复杂,因为环境返回的下一个状态和奖励都基于所有智能体的联合行动,这使得对于任何智能体来说环境都是非马尔可夫的。随机博弈(SG)可以用来模拟多智能体序列决策问题。
**3 多智能体强化学习的应用 **
通过MARL,智能体能够学习并与彼此沟通,从而实现更有效的任务完成和更好的决策结果。这种方法广泛应用于工程和科学,例如,智能交通,无人驾驶飞机,智能信息系统,公共卫生和智能医疗诊断,智能制造,金融贸易,网络安全,智能教育,以及科学研究中的强化学习。
**3.1 智能交通 **
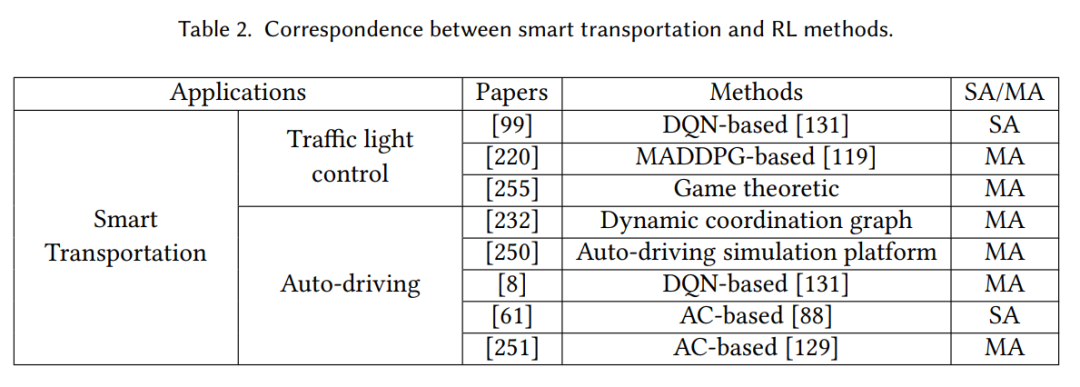
智能交通利用物联网(IoT)和人工智能等先进技术来提高安全性,提高交通效率,并减少其对环境的负面影响。在基于MARL的智能交通中,我们描述了两个已知的场景:交通灯控制和自动驾驶,并展示了人类在这些智能系统中的作用。这个应用与强化学习方法之间的对应关系显示在表2中。
**3.2 无人驾驶飞行器 **
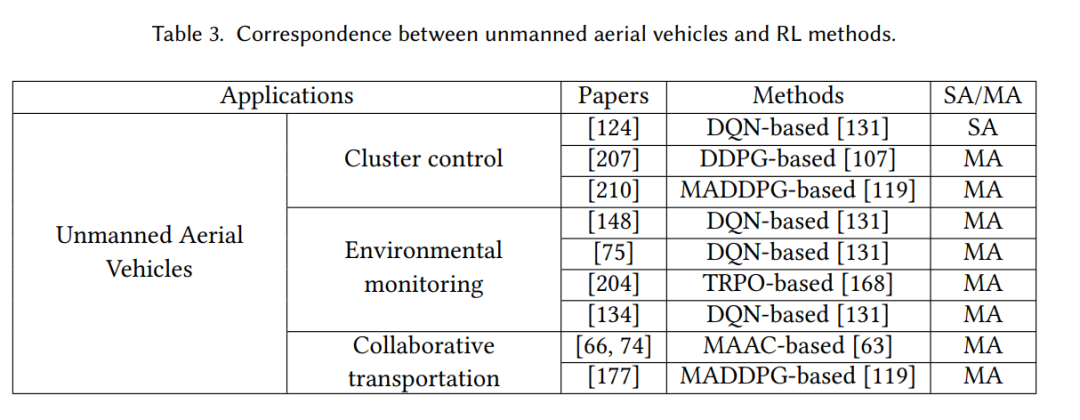
在基于MARL的无人驾驶飞行器(UAVs)应用中,我们描述了三个已知的场景:集群控制[124, 158, 207, 210, 222-224],环境监控[75, 134, 148, 204],以及协同运输[66, 74, 177]。这个应用与强化学习方法之间的对应关系显示在表3中。
**3.3 智能信息系统 **
MARL在智能信息系统中具有巨大的应用潜力,包括自然语言处理(NLP)[13, 83, 98, 104, 120, 183, 195, 226],编程生成[26, 104, 178],以及推荐系统[40, 51, 72, 231, 245]。基于SARL的技术已在NLP和编程生成中得到研究,我们将总结这些研究并指出MARL在这些应用中的显著优点。这个应用与强化学习方法之间的对应关系显示在表4中。

**3.4 公共卫生和智能医疗诊断 **
MARL在公共卫生和智能医疗诊断中得到了广泛的探索和应用。例如,MARL可以应用于COVID-19的预测和管理、医疗图像处理和疾病诊断,以提高疾病预防、诊断和治疗的效率和准确性。这个应用与强化学习方法之间的对应关系显示在表5中。

**3.5 智能制造 **
智能制造是将先进技术(如物联网、人工智能等)整合到制造过程中,以优化生产过程。对于智能制造,MARL是一种有前景的方法。在智能制造的背景下,MARL可以作为生产调度、车间工业机器人控制、质量控制和设备维护的工具,实现智能高效的生产过程[97]。这个应用与强化学习方法之间的对应关系显示在表6中。
**3.6 金融交易 **
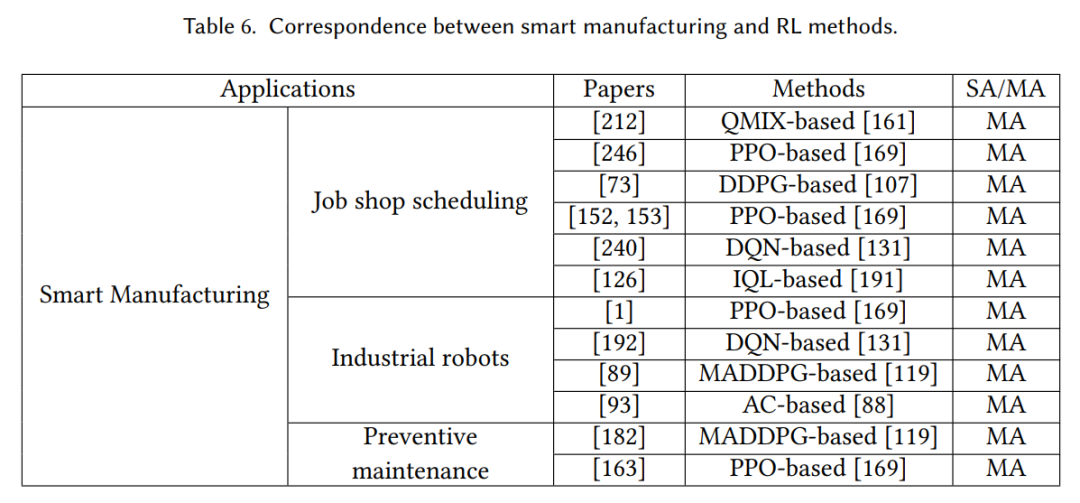
金融交易是一项挑战性的活动,需要快速判断并适应不断变化的市场条件。过去的单智能体方法和深度学习技术已经无法满足市场的期望。MARL通过结合各种智能体之间的合作与竞争,为应对金融交易中的困难提供了新的思路。我们从投资组合管理[60, 95, 123, 150, 175]、交易策略优化[79, 143, 156, 157]和风险管理[6, 34, 49]的角度总结了MARL在金融交易中的应用。这个应用与强化学习方法之间的对应关系显示在表7中。
**3.7 网络安全 **
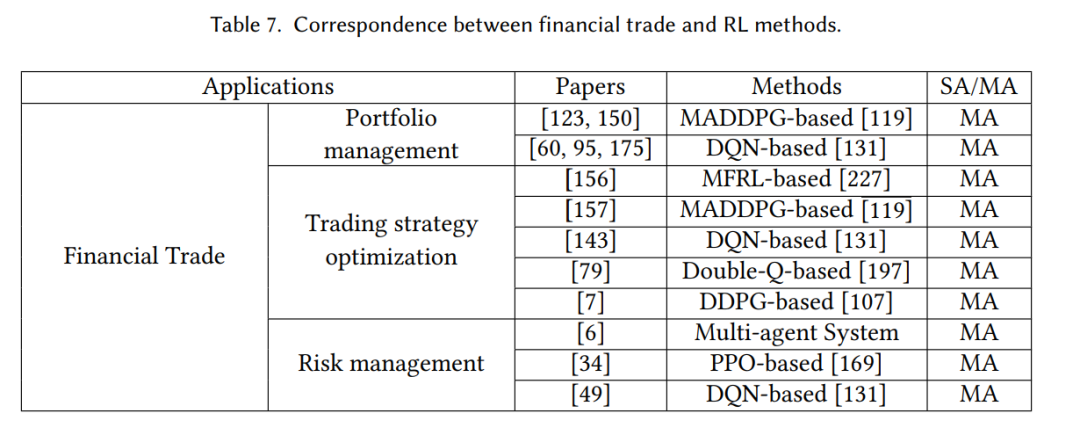
网络安全是当今社会面临的重要问题,攻击者利用各种技术和手段侵入计算机系统和网络,威胁到个人、组织和国家的安全。MARL是一种有前景的方法,可以应用在网络安全领域,主要应用在入侵检测[54, 118, 118, 132, 172, 173]和网络资源优化[103, 135, 145, 186, 190]。这个应用与强化学习方法之间的对应关系显示在表8中。
**3.8 智能教育 **
智能教育利用物联网和人工智能将学习过程数字化,并根据特定学生的学习风格和特点提供个性化的学习体验和支持。传感器可以用来捕捉学生的学习行为和数据。通信使学生与教师之间以及学生之间的协作学习实现实时互动。人工智能可以用来分析学习行为,提供个性化学习和评价教学。虚拟现实技术使得场景重建、实验模拟和远程教学变得更加容易。在基于MARL的智能教育中,我们总结了现有的技术[31, 48, 112, 194]。教育4.0旨在将人工智能技术融入学生自主学习的每个阶段,以提高学习过程中的兴趣和效果[19, 46, 170]。Tang和Hare[194]创建了一个自适应辅导游戏,让学生在没有教师指导的情况下个性化学习。为了优化学生学习,该系统使用Petri网图结构监控学生在游戏中的进展,使用强化学习智能体适应性地改变系统行为以响应学生表现。然后,他们应用Petri网和层次化强化学习算法,基于上述游戏个性化学生的帮助[48]。该算法可以帮助教师根据学生的需求,为他们在游戏中提供定制的指导和反馈,使他们通过将游戏中的任务分解为几个阶段,逐渐掌握复杂的知识和技能。该算法可以帮助教育工作者为游戏中的学生提供定制的支持和反馈,通过将游戏中的任务分为多个层次,逐渐掌握复杂的知识和技能。[112]和[31]都使用传感器收集的数据监测学生的学习进度,并使用强化学习技术为学生提供个性化的学习建议。
3.9 科学领域的强化学习
近年来,人工智能在科学领域的应用已经成为热门话题,人工智能被高度评价为实现科学进步的关键工具[127]。强化学习已经在化学、物理和材料研究等领域展示出显著的科学潜力,尤其在探索未知的物理现象等挑战中,强化学习被证明是解决这些挑战的关键工具。这个应用和强化学习方法之间的对应关系显示在表9中。Seo等人[171]利用强化学习来控制KSTAR托卡马克的前馈𝛽。Degrave等人[22]介绍了一种创新的强化学习方法,使托卡马克聚变装置的磁控系统能够自主学习,从而实现对各种等离子体配置的精确控制,大大减少了设计工作量,是强化学习在聚变领域的开创性应用。Bae等人[5]引入了一种科学多智能体强化学习(SciMARL),用于在湍流模拟中发现壁面模型,大大降低了计算成本,同时复制了关键流量,并提供了对湍流模拟的前所未有的能力。强化学习的科学研究提供了更多的可能性,我们相信未来强化学习在科学应用中的范围将会更广。
4 展望
尽管多智能体强化学习(MARL)在许多领域都已表现出优越的性能,但一些问题,如安全性、鲁棒性和泛化能力,限制了MARL在实际环境中的应用。我们认为,要想最大化地利用未来实践应用中MARL的优越性,首先需要解决这些问题,并需要考虑到人类社会的道德约束。本节回顾了在四个方面的研究现状:安全性、鲁棒性、泛化能力和道德约束,并讨论了未来研究需要解决的差距。
4.1 多智能体强化学习的安全性
随着多智能体强化学习(MARL)的日益普及,确保这些系统的安全性的需求日益突出。在MARL中,一个智能体的行动可能会对任务或其他参与的智能体造成伤害。因此,开发安全的MARL方法的需求迫在眉睫。为了在MARL中实现安全,一种常见的方法是在训练过程中添加约束。通过引入安全性约束,可以鼓励智能体避免可能导致任务失败或对其他智能体造成伤害的不安全行动。已经有很多关于强化学习安全性的综述,如[35],[39]和[225]所总结的。然而,目前还没有关于MARL安全性的系统性综述,而且关于这个话题的研究相对较少。在本节中,我们给出了在[38]中使用的安全MARL的定义。
4.2 多智能体强化学习的鲁棒性
在分类任务中,深度学习的鲁棒性已有一系列的研究 [36, 58, 69, 71, 142]。强化学习是一个序列决策问题,其中在一个时间步的错误分类并不等同于期望最小的奖励。在多智能体强化学习(MARL)中,任何智能体的决策失败都可能导致团队任务失败,这使得MARL的鲁棒性研究具有挑战性。此外,MARL在现实世界的应用中面临各种挑战,例如环境的不确定性,其他智能体的政策不确定性,以及传感器噪声。所有这些因素都可能导致训练的模型表现不佳或者失败。因此,提高MARL的鲁棒性至关重要,这将有助于确保模型在各种情况下都能稳定可靠地运行。以下是关于鲁棒MARL的相关定义。我们使用了[253]和[241]的定义。
4.3 多智能体强化学习的泛化
在MARL领域,泛化涉及到智能体将其在特定环境或场景中学到的知识和技能,无需进行大幅度的修改或重新训练,就能转移到新的、多样的环境或场景中的能力。有几个调查研究了强化学习的泛化 [87, 201, 225, 247]。在SARL的泛化中,各种技术如领域随机化[133, 160, 165],因果推理[82, 167, 237],以及元学习[3, 27, 77]已被用来解决泛化问题。然而,与单智能体设置相比,对MARL的泛化研究相对较少。在这方面,我们从两个角度,即多任务学习和sim2real,提供了相关工作的概述,如图4所示。
4.4 遵循道德约束的学习
随着AI技术的不断发展,考虑AI系统的道德含义变得越来越重要[4]。MARL系统涉及多个智能体的互动,其行为可能对现实世界产生重大影响。因此,确保MARL系统的设计和训练考虑到道德因素至关重要。我们将有关MARL的道德约束的研究总结为隐私保护、公平性和透明度,如图5所示。
5. 人机协同多智能体强化学习面临的挑战
人机协同物理系统(HCPS)是基于物理系统(CPS)发展起来的,它融合了计算机科学、自动化技术、通信科学等领域[9, 115]。本文第3节总结的MARL应用是HCPS的典型应用。人类被视为HCPS的重要组成部分,因此,MARL算法的设计需要考虑人的因素。除了可扩展性和非平稳性的挑战之外,HCPS中的MARL面临着许多额外的挑战,这是由于人类、物理系统和计算机系统之间的相互作用导致的。
6. 结论
本文综述了MARL的基本方法,并对MARL在智能交通、无人机、智能信息系统、公共健康与智能医疗诊断、智能制造、金融贸易、网络安全、智慧教育、科学强化学习等各个领域的相关研究进行了综述。为了更好地服务于人类社会,有必要发展一个值得信赖的MARL。从安全性、鲁棒性、泛化性和伦理约束等角度定义了可信MARL,并总结了这些领域的当前研究和局限性。最后,讨论了在MARL中考虑HCPS时面临的其他挑战,这对其在人类社会的实际应用至关重要。希望本文能够对各种研究方法和应用场景进行全面综述,鼓励和推动MARL在人类社会中的应用,更好地服务于人类。
