

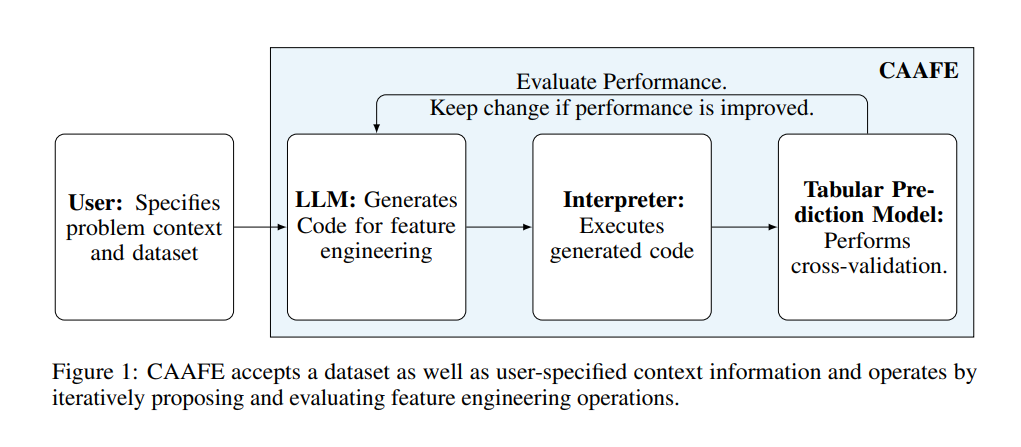
随着自动机器学习(AutoML)领域的发展,将领域知识整合到这些系统中变得越来越重要。我们提出了一种通过利用大型语言模型(LLMs)的能力来实现这一点的方法。具体来说,我们推出了一种基于上下文的自动特征工程(CAAFE),这是一种用于表格数据集的特征工程方法,它利用LLM迭代地为表格数据集生成基于数据集描述的额外的语义有意义的特征。该方法生成用于创建新特征的Python代码以及生成特征的实用性的解释。尽管在方法上简单,CAAFE在14个数据集中的11个上都提高了性能 - 将所有数据集的平均ROC AUC性能从0.798提高到0.822 - 这与我们的数据集上使用随机森林代替逻辑回归所取得的改善相似。此外,CAAFE通过为每个生成的特征提供文本解释而具有可解释性。CAAFE为数据科学任务中更广泛的半自动化铺平了道路,并强调了可以将AutoML系统的范围扩展到语义AutoML的上下文感知解决方案的重要性。我们发布了我们的代码、一个简单的演示和一个Python包。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日