

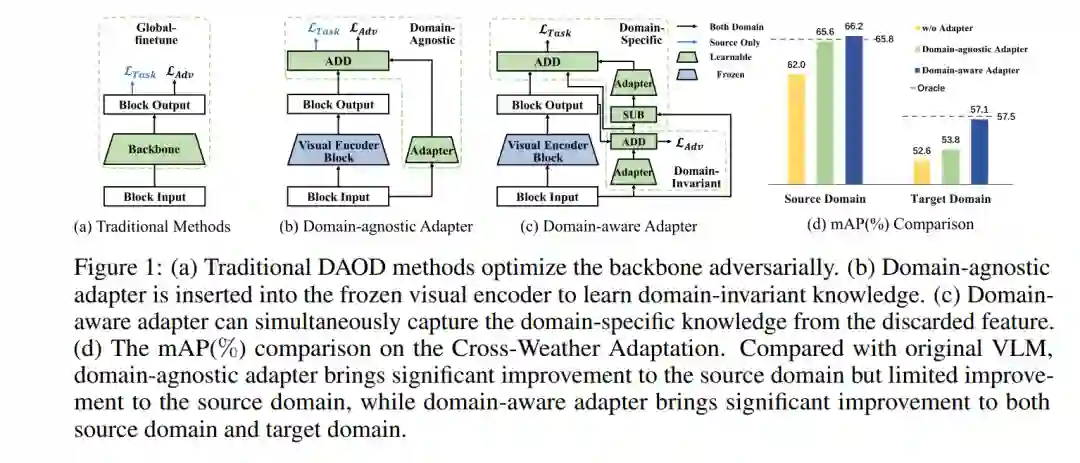
领域自适应目标检测(Domain Adaptive Object Detection, DAOD)旨在将训练于已标注源领域的检测器泛化到未标注的目标领域。由于视觉-语言模型(Visual-Language Models, VLMs)可以为未见图像提供重要的通用知识,冻结视觉编码器并插入一个领域无关的适配器可以学习领域不变的知识以实现DAOD。然而,领域无关的适配器不可避免地偏向于源领域,它舍弃了一些对未标注领域具有辨别性的有用知识,即目标领域的特定领域知识。为了解决这一问题,我们提出了一种新颖的、专门针对DAOD任务设计的领域感知适配器(Domain-Aware Adapter, DA-Ada)。关键在于利用领域特定知识来桥接基本的通用知识和领域不变知识。DA-Ada包括用于学习领域不变知识的领域不变适配器(Domain-Invariant Adapter, DIA),以及用于从视觉编码器舍弃的信息中注入特定领域知识的领域特定适配器(Domain-Specific Adapter, DSA)。在多个DAOD任务上的综合实验表明,DA-Ada可以有效地推断出一个领域感知的视觉编码器,从而提升领域自适应目标检测的效果。我们的代码可在 https://github.com/Therock90421/DA-Ada 获取。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
225+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
225+阅读 · 2023年4月7日