
参数高效微调方法有哪些?请看这篇文章

随着基于Transformer的预训练语言模型(PLM)参数数量的不断增长,特别是具有数十亿参数的大型语言模型(LLM)的出现,许多自然语言处理(NLP)任务已经显示出显著的成功。然而,这些模型巨大的规模和计算需求为将它们适应到特定的下游任务带来了重大挑战,特别是在计算资源有限的环境中**。参数高效微调(PEFT)通过减少微调参数数量和内存使用,同时实现与完全微调相当的性能**,提供了一个有效的解决方案。对PLM,特别是LLM的微调需求,导致了PEFT方法的迅速发展,如图1所示。在这篇论文中,我们提供了对PLM的PEFT方法的全面和系统的综述。我们总结了这些PEFT方法,讨论了它们的应用,并概述了未来的方向。此外,我们使用几种具有代表性的PEFT方法进行实验,以更好地理解它们在参数高效性和内存高效性方面的有效性。通过提供对最新进展和实际应用的洞察,这项综述为寻求在PLM背景下导航PEFT所带来的挑战和机遇的研究人员和从业者提供了宝贵的资源。
https://www.zhuanzhi.ai/paper/4ec8a73bb12a0d3c1fab7bf7e6fda2c7
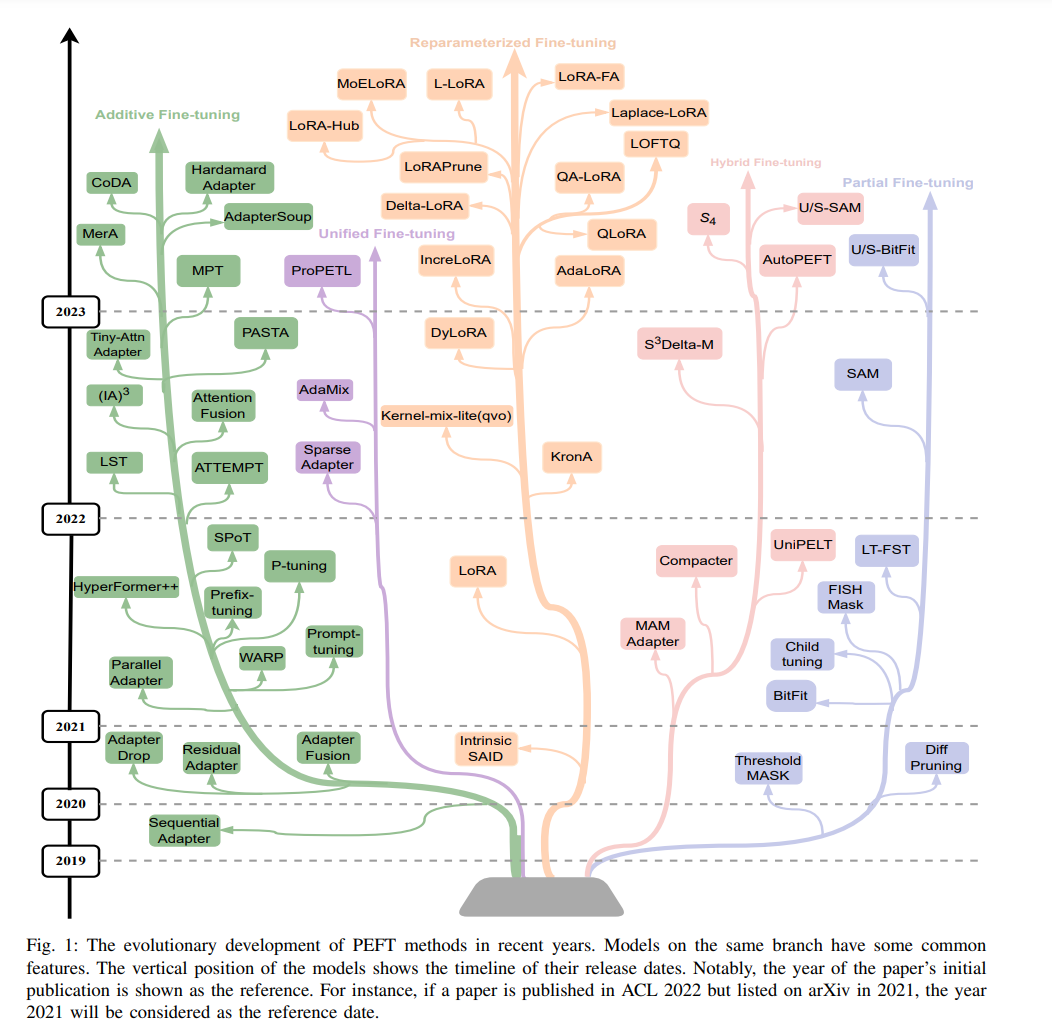
基于Transformer的PLM [1]、[2]、[3]、[4] 在广泛的NLP任务中展示了卓越的性能。为了充分利用PLM的潜力,采用微调来适应PLM到特定任务数据以提升下游任务的性能。然而,传统的微调涉及更新所有预训练的PLM参数,这既耗时又计算成本高。随着PLM的大小持续增长,从像BERT [1] 这样的拥有1.1亿参数的模型到T5 [4] 的7.7亿参数,计算资源需求变成了一个重大挑战。LLM [5]、[6]、[7] 的出现,例如Falcon [8] 拥有惊人的1800亿参数,进一步加剧了计算需求。为了执行Falcon-180B的特定任务全面微调,可能需要至少5120GB的计算资源1。庞大的计算资源需求使得除了超级大玩家之外的任何人都无法利用LLM进行特定任务的微调。为了解决这一挑战,一种被称为PEFT [9] 的突出方法作为补偿全参数微调巨大计算成本的可行解决方案出现了。PEFT涉及采用各种深度学习技术 [9]、[10]、[11] 来减少可训练参数的数量,同时仍然保持与完全微调相当的性能。此外,PEFT仅更新少量附加参数或更新预训练参数的子集,保留了PLM捕获的知识,同时将其适应于目标任务,并减少灾难性遗忘的风险。而且,由于微调数据集的大小通常比预训练数据集小得多,对所有预训练参数进行全面微调可能会导致过拟合,这是通过PEFT通过选择性或不更新预训练参数来避免的。
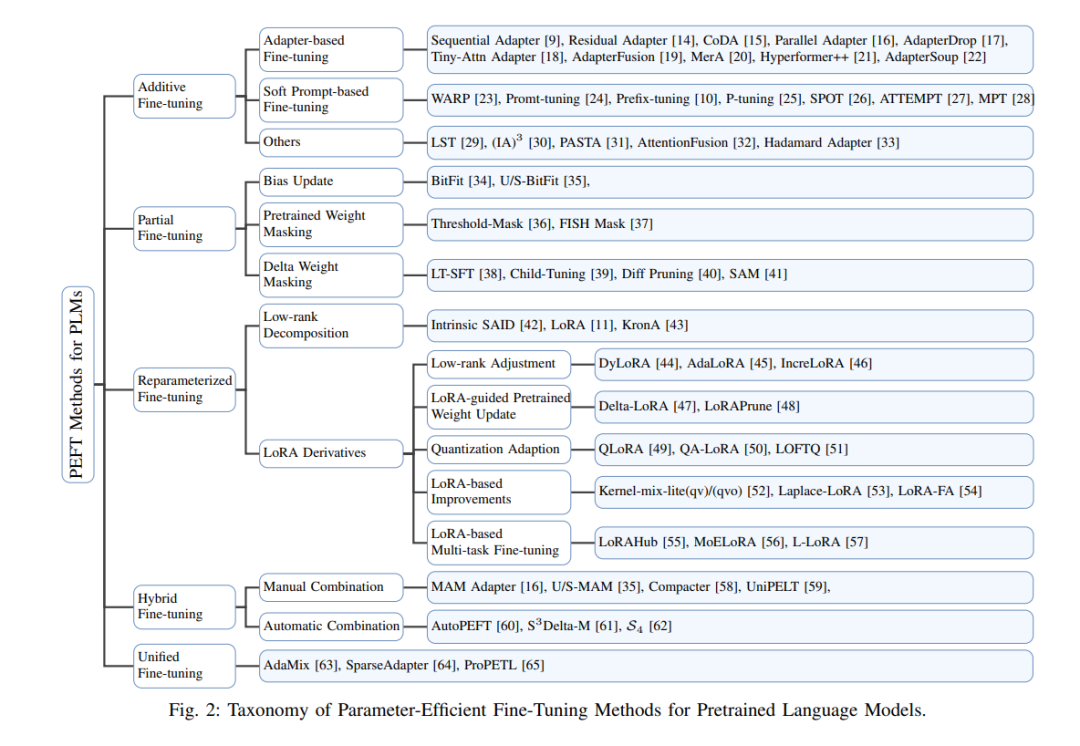
最近,对PEFT方法的兴趣显著增长,如图1所示的研究数量不断增加。这也导致了对PLM的PEFT方法的几项调查。然而,现有的调查存在一定的局限性。丁等人[12] 对PEFT方法进行了全面研究,但这项调查没有涵盖该领域的最新工作,只有四种PEFT方法被定量实验。Lialin等人[13] 详细探讨了PEFT方法的思想和操作实现,但没有进行相关实验。在这项工作中,我们全面解决了这些差距。我们细致地分类了PEFT方法,提供了每种方法的思想和具体实现的详细解释。我们比较了各种类型PEFT方法之间的相似之处和不同之处,有助于更好地理解PEFT的不断演变的景观。此外,我们还使用11种具有代表性的PEFT方法进行了广泛的微调实验。在本文中,我们旨在为PLM在NLP中的PEFT方法提供全面和系统的研究。我们深入探索这些PEFT方法,并在第III节中提出了一个全面的分类方案。通过将PEFT方法分类为附加微调、部分微调、重新参数化微调、混合微调和统一微调,我们为理解这些PEFT方法建立了一个结构化框架,如图2所示。在第IV节中,我们进行定量调查和分析,以评估这些PEFT方法的性能、参数效率和内存使用情况。我们的定量研究主要集中在自然语言理解(NLU)、机器翻译(MT)和自然语言生成(NLG)任务上。此外,我们还广泛探讨了PEFT在多任务学习、跨语言转移以及后门攻击和防御中的应用,强调了其有效性。此外,我们的研究还揭示了未来在这一快速发展领域的潜在研究方向。总而言之,本次调查的主要贡献可以概述如下: • 我们对基于Transformer的PLM的PEFT方法进行了全面分析和综述。 •** 我们确定了PEFT方法中采用的关键技术和方法,并将它们分类为附加、部分、重新参数化、混合和统一微调方法**。 • 我们进行了广泛的实验,以评估几种具有代表性的PEFT方法的有效性,特别是它们对参数效率和内存使用的影响。 参数高效微调方法
**附加微调方法 **
附加微调方法涉及引入新的额外可训练参数,用于特定任务的微调。我们将附加微调分为三类:基于适配器的微调[9]、[14]、[15]、[16]、[17]、[18]、[19]、[20]、[21]、[22]、[76],其中适配器模块被整合到transformer中,允许在不修改预训练参数的情况下进行微调;基于软提示的微调[10]、[23]、[24]、[25]、[26]、[27]、[28],在这种方法中,软提示或前缀向量在微调过程中被添加到输入嵌入或隐藏状态;以及其他[29]、[30]、[31]、[32]、[33],在这一类中,各种引入补充参数以进行模型微调的方法都被包括在内。
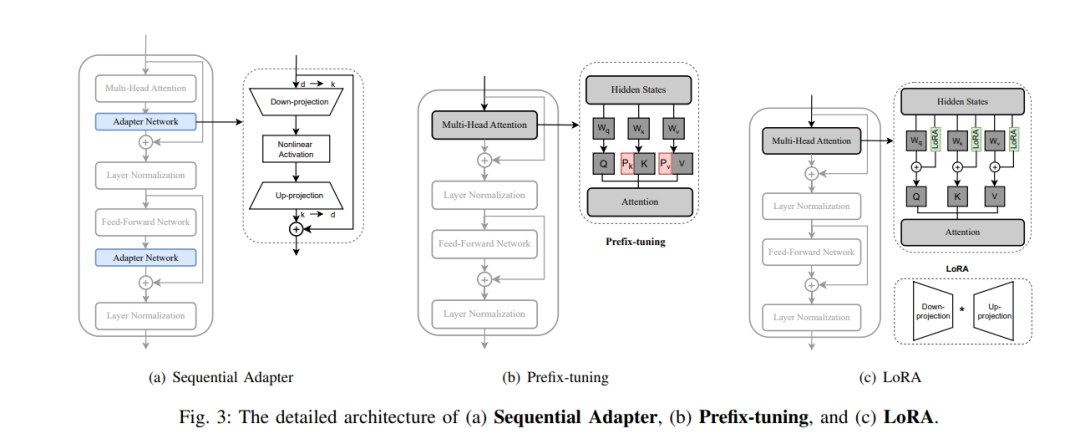
**B. 部分微调 **
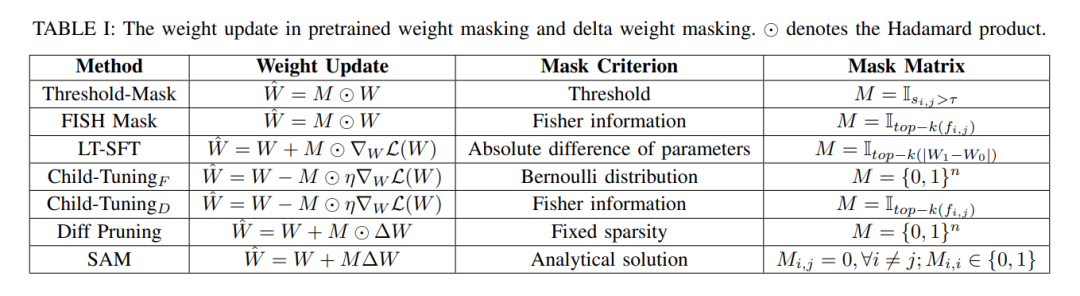
部分微调方法旨在通过选择对下游任务至关重要的预训练参数子集,同时丢弃不重要的参数,来减少微调参数的数量。我们将部分微调方法分为三组:偏差更新[34]、[35],在此方法中,仅更新transformer中的注意力层、前馈层和层归一化的偏差项;预训练权重遮蔽[36]、[37],在这种方法中,使用各种剪枝标准遮蔽预训练权重;以及增量权重遮蔽[38]、[39]、[40]、[41],在该方法中,通过剪枝技术和优化近似遮蔽增量权重。对预训练权重和增量权重遮蔽的详细分析在表I中提供。
**C. 重新参数化微调 **
重新参数化微调方法利用低秩转换来减少可训练参数的数量,同时允许处理高维矩阵(例如,预训练权重)。我们将重新参数化微调方法分为两组:低秩分解[11]、[42]、[43],在这种方法中,使用各种低秩分解技术来重新参数化更新的矩阵;以及LoRA衍生物[44]、[45]、[46]、[47]、[48]、[49]、[50]、[51]、[52]、[53]、[54]、[55]、[56]、[57],在这里一系列基于LoRA的PEFT方法被开发。各种方法的∆W参数重新参数化的具体细节可以在表II中看到。

**D. 混合微调 **
混合微调方法旨在结合各种PEFT方法,如适配器、前缀调整和LoRA,以利用每种方法的优势并减轻它们的弱点。通过整合PEFT方法的不同特点,混合微调比单个PEFT方法实现了更好的整体性能。这些工作被分为两种方法:手动组合[16]、[35]、[58]、[59],在这种方法中,通过精巧的设计手动结合多种PEFT方法;以及自动组合[60]、[61]、[62],在这种方法中,通过结构搜索自动整合各种PEFT方法。 **结论 **
本文对PLM的PEFT方法进行了全面和结构化的研究。通过对NLP中的PEFT方法进行分类,我们确定了与它们相关的主要技术和挑战。我们采用几种具有代表性的PEFT方法对基于编码器的RoBERTa、基于编码器-解码器的T5和基于解码器的LLaMA进行了各种下游任务的微调。实验结果表明,大多数PEFT方法显著提高了参数效率,并且与完全微调相比,实现了可比较甚至更好的性能。此外,大多数PEFT方法降低了内存占用,QLoRA大幅减少了计算内存需求,缓解了微调LLM时的内存挑战。此外,我们介绍了PEFT方法的常见应用,并概述了未来的研究方向。随着LLM的发展,显然需要开发能够在微调过程中有效减少计算资源需求和内存使用的PEFT方法。本调查旨在提供对PLM PEFT方法的鸟瞰视角,并激发在这一领域的进一步研究。
