

信息社会时刻面临着信息战的威胁,信息战可以针对军事和民用目标实施。事实证明,破坏电子硬件安全成功地摧毁了电力网络、核研究项目和证券交易所。然而,针对作为社会技术系统重要生物组成部分的人类,也能取得类似的结果。我们所说的影响/信息作战(info ops),信息系统的用户既是最容易受到攻击的点,也是攻击的目标。虽然信息作战是信息战的一个子领域,但它的范围很广,包括一系列针对人类认知的方法。本论文的重点是信息饱和攻击,即用大量信息压倒目标的战术。
电子商务是一种非常规的饱和攻击目标。但是,亚马逊每年花费数亿美元打击假冒产品列表,这一事实表明了此类攻击的潜力。虽然欺骗性列表很可能是多个独立的欺诈者为谋取经济利益所为,但可以想象,一个强大的恶意行为者可以在其竞争对手的电子商务平台上放大欺骗性列表的生产,从而损害其经济利益。我们开发了一个性能更佳的实体匹配框架,以帮助应对针对电子商务数据库的饱和攻击。
在对饱和攻击采取防御措施时,应注意防止间接的自我伤害。以假新闻和讽刺新闻为例。不加区分地删除所有非真实新闻将导致讽刺性新闻的消失,而讽刺性新闻在提高政治意识和参与度方面发挥着既定的作用。通过对讽刺新闻和假新闻进行有效的鉴别,我们并不能更有效地打击假新闻本身,但却能使决策者有能力制定更细致入微的反误导政策,在追求安全的同时不损害其自身的更广泛利益,如健康的公民社会。
饱和攻击还能操纵信息的流行度,而这些信息是主观意见,而不仅仅是既定事实。在这种情况下,通过饱和攻击暗中支持对意见的压制,有可能被指责为新闻检查。在另一些情况下,人们可能需要主动预防即将发生的饱和攻击。在这两种情况下,唯一可行的策略可能就是对自己的民众实施饱和攻击。为了模拟成群的人类和有动机的宣传者(即机器人)试图在网络社交媒体平台上最大限度地采纳他们对某一问题的意见,我们提出了一个基于智能体的信息扩散模型。该模型的设计参考了我们对推特上一个实际争议问题的舆论动态进行的广泛研究:戴口罩预防 COVID-19。该模型还结合了有实证支持的概念,如带动力和同伴压力,来模拟人类对舆论操纵的易感性。通过展示社交媒体上饱和攻击的成功和失败条件,我们的信息扩散模型能够规划针对饱和攻击的防御措施,而无需在现实世界中测试干预措施的道德窘境。
总之,本论文介绍了涉及各种信息环境中饱和攻击的四个原创研究项目,并提供了应对这些攻击的可能方法。我们工作的贡献在于推动了社会网络安全这一新兴领域的发展,该领域关注的是保护信息时代社会技术系统中最薄弱的环节--人类。
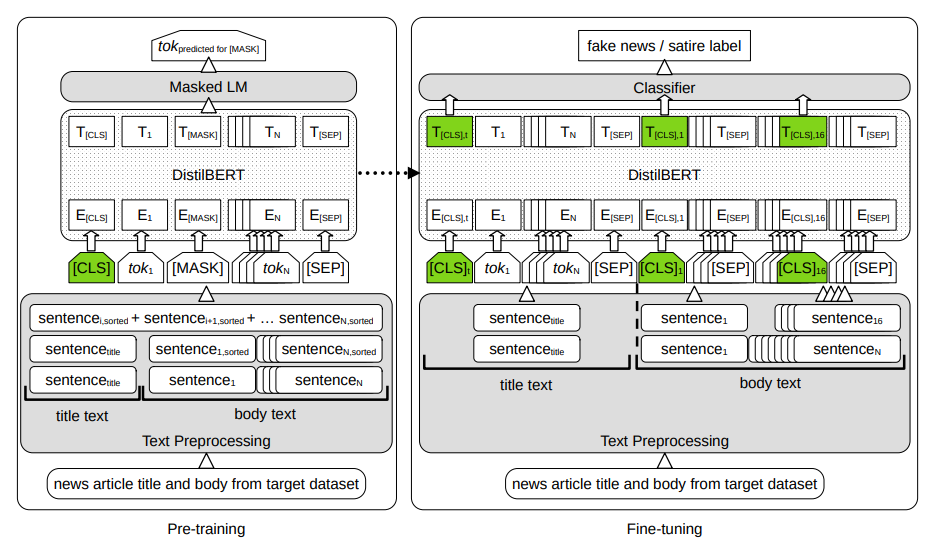
图 3.1: 假新闻和讽刺作品分类框架。图中展示的特定配置(MultiCLS-SimSents-Title+Body)是使用与目标/下游假新闻和讽刺分类任务所用数据集相同的掩码语言建模任务进行预训练的。在预训练过程中,文章正文中的句子首先按照与标题(SimSents)的相似度重新排序。然后,随机选取一个句子 i 作为起点,将其与后面的句子连接起来,并进行标记化处理。在微调过程中,DistilBERT 参数使用预训练结束时获得的值进行初始化。在微调(MultiCLS)过程中使用了 17 个特殊的聚合标记[CLS],其中 1 个用于文章标题,其余 16 个用于文章正文的前 16 个句子,并保留其原始顺序(标题+正文)。
本文贡献
本文所报告的研究项目代表了原创性学术成果和对现有知识体系的独特贡献。每个项目都是为了实现第 1.4 节中列出的一个研究子目标。这些贡献按相应子目标的顺序排列如下:
-
改进了现有框架,这些框架依靠转换器(Transformer)来解决实体解析(ER)问题下的实体匹配(EM)子问题。我们的框架 AttendEM 通过多次重复使用单个转换器架构来创建不同的模型,并异步构建这些模型的集合,从而实现了最先进的(SOTA)结果。正如我们在 DeBERTa 和 ConvBERT 之间互换所证明的那样,该框架与所使用的转换器架构无关。识别重复实体是采取针对重复实体的行动(即防御饱和攻击)的先决条件。
-
区分讽刺和假新闻的新颖框架。在发表论文时,我们是第一个将转换器(特别是 DistilBERT)应用于区分讽刺和假新闻这一特定任务的人。该框架首先使用新闻数据集对其中的转换器语言模型进行预训练,帮助模型与新闻文章中使用的语言类型保持一致。然后对预训练模型进行微调,以完成区分假新闻和讽刺新闻的任务。我们的框架取得了 SOTA 结果。从假新闻中识别出讽刺新闻是防止针对假新闻的行动也影响到讽刺新闻的先决条件,即防止针对饱和攻击所采取的防御措施造成附带损害。
-
关于 SARS-CoV-2 大流行初期 Twitter 上戴口罩言论的研究。所研究的话题与其他话题(如疫苗接种和气候变化)不同,它在数据收集期开始时缺乏根深蒂固的观点,因此具有独特性。本研究的视角是,在讨论中交流的所有信息(推文)都可以归类为立场和主题。立场代表一条推文对戴口罩问题的立场。主题则代表影响立场的不同方面,例如,某人反对戴口罩的言论是否得到权威医学来源的支持。研究考虑了不同立场和主题的参与度指标,如点赞数,包括比率计量学。研究的一个意外发现是,有证据表明社交媒体平台背后的决策者打破了集中讨论,从而损害了一种立场。这项研究提高了我们对有争议话题的信息扩散动态的理解,因为戴面具问题在推特上引起了激烈的争论,而加深理解对于开发模拟饱和攻击的精确模型以及针对攻击的干预措施至关重要。
-
基于智能体的社交媒体信息传播合作模型--Diluvsion。该模型的显著特点是强调间接影响,即信息可以在信息源与目标之间不存在友谊纽带的情况下到达目标,而参与度指标形式的辅助信息可以影响目标采取某种立场的决定。模型中存在两类不同的智能体:机器人和人类,前者代表有动机的宣传者,后者代表天真的用户。Diluvsion 模型的优势体现在对正统信息行动的模拟中,例如,最大限度地采纳一种立场;创建回声室;诱导极化;以及非正统信息行动,例如,同时支持多种立场作为传播主题的特洛伊木马战术。该模型在开发过程中吸收了我们在推特上的研究成果,能够模拟饱和攻击,并对饱和攻击进行干预。
提纲
为了让读者了解本论文其余各章之间的高层次联系,尤其是介绍四个原创研究项目/论文的章节,我们请读者参阅第 1.4 节,在这一节中,我们讨论了这些论文所要实现的研究子目标的演变轨迹。本论文的其余部分结构如下:
- 第 2 章讨论实体匹配框架 AttendEM。
- 第 3 章讨论虚假与讽刺辨别框架。
- 第 4 章讨论对 Twitter 上 COVID-19戴口罩言论的研究。
- 第 5 章讨论信息扩散模型 Diluvsion。
- 最后一章,即第 6 章,总结了本文中介绍的研究项目的主要贡献,讨论了这些工作的总体影响,并提出了未来的研究方向。
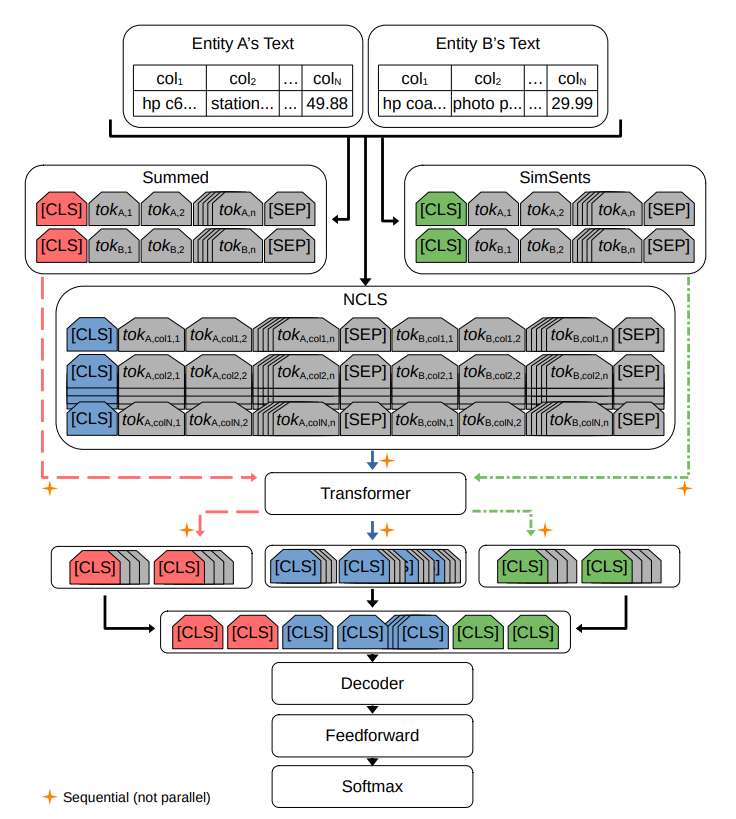
图 2.2: AttendEM 的工作流程显示了文本预处理(NCLS/属性对齐、求和、Simsents,详见第 2.3.3 节)、聚合标记插入(dual-CLS、NCLS,详见第 2.3.4 节)、如第 2.3.5 节所述对文本跨度的不同表示的输出进行集合,以及包含自注意层(解码器)和前馈层的分类器头(如第 2.2.5 节所述处理串联[CLS]嵌入)。 分类器头部包含一个自注意层(解码器),以及处理连接[CLS]嵌入的前馈层,详见第 2.2.5.2 节和第 2.3.5 节。转换器代表一种可替代的架构,如 DeBERTa 或 ConvBERT。如图左下角所示,四角星表示处理过程是顺序而非并行的。

