
人工智能的一项基本任务是学习。深度神经网络已经被证明可以完美地应对所有的学习模式,比如监督学习、非监督学习和强化学习。然而,传统的深度学习方法利用云计算设施,不能很好地扩展到计算资源低的自主代理。即使在云计算中,它们也会受到计算和内存的限制,无法用于为假定网络中有数十亿神经元的代理恰当地建立大型物理世界的模型。在过去几年里,可扩展深度学习这一新兴课题解决了这些问题,该课题在训练前和训练过程中利用了神经网络中的静态和自适应稀疏连通性。本教程分两部分涵盖了这些研究方向,重点关注理论进步、实际应用和实践经验。
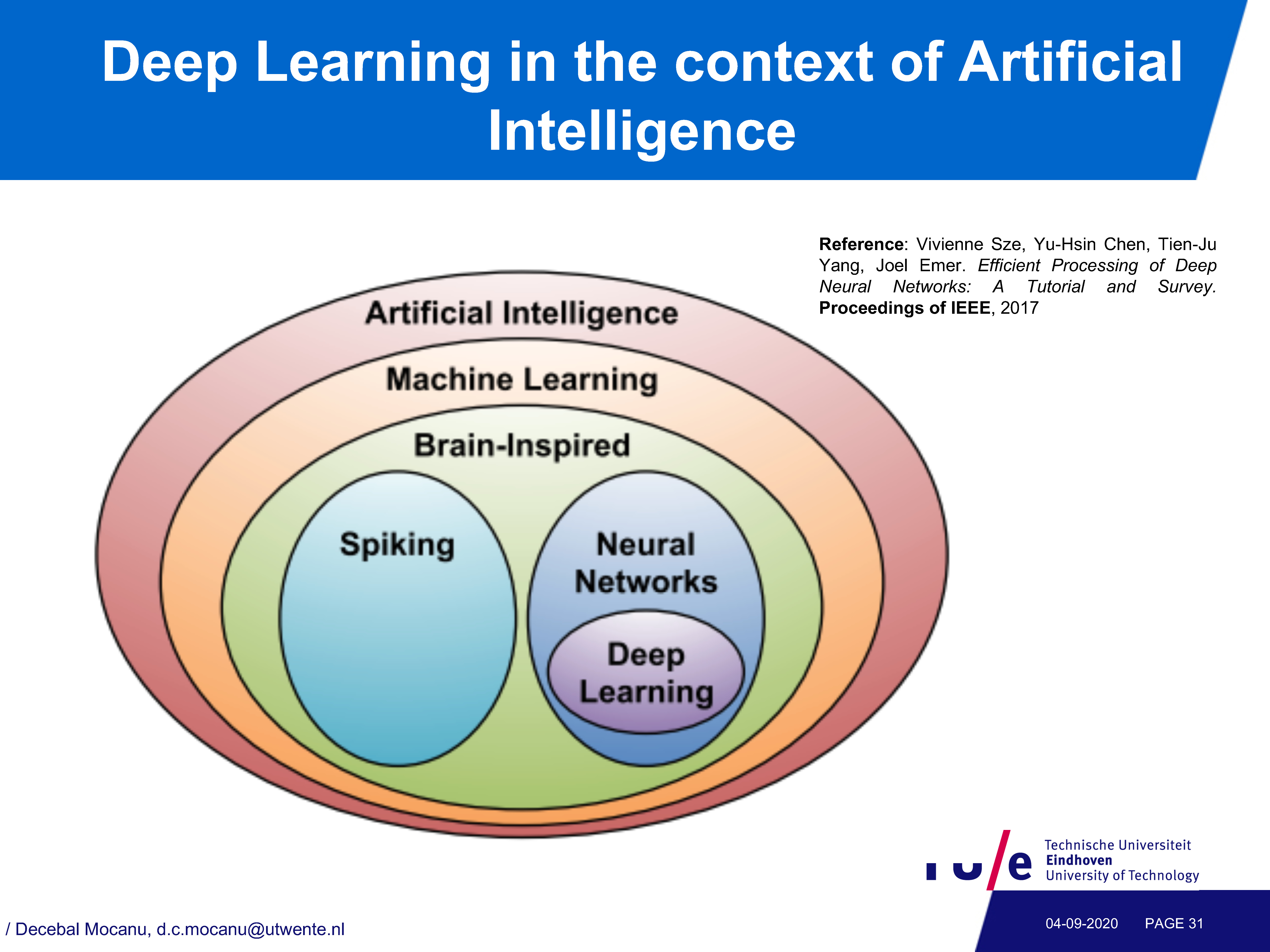
本教程的第一部分侧重于理论。我们首先简要讨论了复杂网络和系统背景下的基础科学范式,并修正了目前有多少代理使用深度神经网络。然后介绍神经网络的基本概念,并从函数和拓扑的角度对人工神经网络和生物神经网络进行了比较。我们继续介绍90年代早期关于高效神经网络的第一批论文,这些论文利用稀疏性强制惩罚或基于各种显著性准则对全连接网络进行权值修剪。然后,我们回顾了一些最近的工作,从全连通网络开始,利用剪枝-再训练循环压缩深度神经网络,使其在推理阶段更有效。然后我们讨论另一种方法,即神经进化的扩充拓扑(NEAT)及其后续,使用进化计算以增长有效的深度神经网络。
进一步,我们引入了深度强化学习,并为可扩展的深度强化学习铺平了道路。我们描述了在深度强化学习领域的一些最近的进展。
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯
相关论文