【导读】“第十七届中国计算语言学大会”(The Seventeenth China National Conference on Computational Linguistics, CCL 2018)于2018年10月19日—21日在长沙理工大学举行。作为国内最大的自然语言处理领域的社团组织——中国中文信息学会(CIPS)的旗舰会议,CCL着重于中国境内各类语言的计算处理,为研讨和传播计算语言学最新的学术和技术成果提供了高水平的深入交流平台。作为本次大会重点内容之一,大会开展了CCL/NLP-NABD 2018讲习班暨中国中文信息学会《前沿技术讲习班》(ATT)第12期,内容包括来自RPI、微软亚研、北京大学的研究学者做了关于实体链接、机器学习理论、个性化推荐和强化学习的讲习报告。
![]()
讲习报告地址:
http://www.cips-cl.org/static/CCL2018/tutorials.html
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
机器学习理论——回顾与展望
![]()
讲者:王立威,北京大学信息科学技术学院教授。清华大学交叉信息研究院客座教授。主要从事机器学习理论研究。 在机器学习国际权威期刊会议发表高水平论文100余篇。多次担任国际机器学习旗舰会议NIPS领域主席;担任机器学习顶级期刊IEEE TPAMI编委。 2011年入选由人工智能国际期刊IEEE Intelligence Systems评选的AI’s 10 to Watch,是该奖项自设立以来首位获此荣誉的中国学者。 2012年获得首届国家自然科学基金优秀青年基金。带领团队获得包括首届天池AI医疗大赛决赛在内的多项比赛冠军。
报告摘要:衡量机器学习算法性能最重要的指标是其泛化能力。泛化理论也是机器学习作为一个独立的学科,区别其它学术领域的核心理论。 本次报告中,我将介绍机器学习中关于泛化能力的几个重要理论。首先介绍VC理论,该理论刻画了经验风险最小化算法的泛化能力。对于SVM和Boosting这类学习算法,margin理论描述了confidence与泛化的关系。我还将介绍algorithmic stability理论,这一理论说明所有具备训练稳定性的学习算法必然具有很好的泛化能力。 最后,我将对当前深度学习算法进行讨论。包括深度网络的损失函数性质、随机梯度算法的鞍点逃逸。并探讨深度学习对于经典泛化理论带来的挑战,以及未来理论的发展方向。
![]()
报告地址:
http://www.cips-cl.org/static/CCL2018/downloads/tutorialsPPT/T3.pdf
强化学习简介
![]()
讲者:秦涛,微软亚洲研究院资深研究员/经理,中国科学技术大学博士生导师。主要研究领域包括机器学习和人工智能(深度学习和强化学习的算法设计、理论分析及在实际问题中的应用),互联网搜索与计算广告,博弈论和多智能体系统,在国际会议和期刊上发表学术论文100余篇。曾任SIGIR、ACML、AAMAS领域主席,担任多个国际学术大会程序委员会成员,包括ICML、NIPS、KDD、IJCAI、AAAI、WSDM、EC、SIGIR、AAMAS、WINE,曾任多个国际学术研讨会联合主席。获得《北京青年》2017年度年度“工匠精神·青年榜样”奖。
报告摘要:近年来,强化学习特别是深度强化学习在棋类、视屏游戏、机器人控制等问题上取得了极大的成功,成为人工智能研究的热点。 讲者将在报告中对强化学习做一个简要介绍,该报告分为3个部分:
1. 强化学习基础,包括马氏决策过程、Bellman方程、规划、最优控制、蒙特卡洛采样以及TD算法。
2. 强化学习新算法,包括基于值函数的算法,基于策略函数的算法,以及基于两者的混合算法。
3. 强化学习所面临的挑战,如鲁棒性、样本效率等。
![]()
报告地址:
http://www.cips-cl.org/static/CCL2018/downloads/tutorialsPPT/T4.pdf
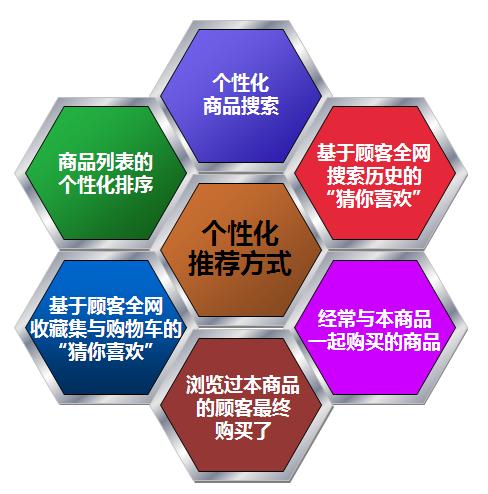
个性化推荐系统的未来:基于知识的推荐与可解释推荐
讲者:谢幸(微软亚洲研究院)、王希廷(微软亚洲研究院)
![]()
谢幸,微软亚洲研究院首席研究员,中国科技大学兼职博士生导师。他于2001年在中国科技大学获得博士学位。 他在国际会议和学术期刊上发表了200余篇学术论文,多次在KDD、ICDM等顶级会议上获最佳论文奖,并被邀请在ASONAM 2017、Mobiquitous 2016、SocInfo 2015、W2GIS 2011等会议做大会主题报告。 他是ACM、IEEE高级会员和计算机学会杰出会员,多次担任顶级国际会议程序委员会委员和领域主席等职位。 他是ACM TSC, ACM TIST, ACM IMWUT, GeoInformatica, Pervasive and Mobile Computing等杂志编委。 他参与创立了ACM SIGSPATIAL中国分会,并曾担任ACM UbiComp 2011、PCC 2012、IEEE UIC 2015、以及SMP 2017等大会程序委员会共同主席。
![]()
王希廷,微软亚洲研究院研究员。她于2011年在清华大学获得工学学士学位,并于2017年在清华大学获得工学博士学位。 她的研究成果发表在数据挖掘与可视化领域顶级会议和期刊上,包括KDD、TKDE、AAAI、IJCAI、VAST和TVCG等。她的论文被CCF A类期刊TVCG选为封面论文。 她在AAAI等会议担任程序委员会委员,并曾担任TKDE、TVCG、InfoVis等顶级会议或期刊审稿人。
报告摘要:由于信息的爆炸式增长,推荐系统在互联网服务中扮演着越来越重要的角色,也是学术界和工业界持续的研究热点。与此同时,随着定位技术、传感器和社交网络的高速发展,产生了大量的用户行为数据。这些数据可以全面的反映用户不同维度的特征,大大提高了个性化推荐的性能。在这次讲习班中,我们会介绍个性化推荐系统目前遇到的挑战,例如用户行为数据的异构性和稀疏性、缺乏可解释性等。我们还会介绍如何借助异构数据、知识图谱以及用户活动规律来提升推荐算法性能。在可解释性方面,我们将会介绍可解释推荐系统的分类、推荐解释生成方法以及可解释推荐面临的机遇和挑战。
![]()
报告地址:
http://www.cips-cl.org/static/CCL2018/downloads/tutorialsPPT/T2.pdf
Cross-lingual Entity Discovery and Linking
![]()
讲者:季姮(Rensselaer Polytechnic Institute), Heng Ji Edward P. Hamilton Chair Professor in Computer Science Department of Rensselaer Polytechnic Institute.
报告摘要:Cross-lingual Entity Discovery and Linking (EDL) (Ji et al., 2014) is the task of extracting entity mentions from foreign language texts and linking them to an external English knowledge base (KB). Beyond the motivation that drives the mono-lingual English EDL task – knowledge acquisition and information extraction – in the crosslingual case and especially when dealing with low resource languages, the hope is to provide improved natural language understanding capabilities for the many languages for which we have few linguistic resources and annotation and no machine translation technology. The LoreHLT2016-2018 evaluations and recent NIST TAC-KBP EDL tasks target really low-resource languages like Northern Sotho or Kikuyu which only have about hundreds of Wikipedia pages. The primary goals of this tutorial are to review the framework of cross-lingual EDL and motivate it as a broad paradigm for the Information Extraction task. We will start by discussing the traditional EDL techniques and metrics and address questions relevant to the adequacy of these to across domains and languages. We will then present more recent approaches such as Neural EDL, discuss the basic building blocks of a state-of-the-art neural EDL system. In particular, we will discuss and compare multiple methods that make use of multi-lingual common semantic space construction and cross-lingual transfer learning. The tutorial will be useful for both senior and junior researchers (in academia and industry) with interests in cross-source information extraction and linking, knowledge acquisition, and the use of acquired knowledge in natural language processing and information extraction. We will try to provide a concise road-map of recent approaches, perspectives, and results, as well as point to some of our state-of-the-art EDL data sets, resources and systems that are available to the research community.
![]()
报告地址:
http://www.cips-cl.org/static/CCL2018/downloads/tutorialsPPT/T1.pdf
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!
登录www.zhuanzhi.ai或者点击阅读原文,使用专知,可获取更多AI知识资料!
专知运用有多个深度学习主题群,欢迎各位添加专知小助手微信(下方二维码)进群交流(请备注主题类型:AI、NLP、CV、 KG等)
AI 项目技术 & 商务合作:bd@zhuanzhi.ai, 或扫描上面二维码联系!
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知