

强化学习(RL)在人工智能(AI)领域取得了一些最令人瞩目的进展。强化学习从深度神经网络的出现中获益匪浅,深度神经网络使学习代理能够在日益复杂的环境中逼近最优行为。特别是,竞争性 RL 的研究表明,在对抗环境中竞争的多个智能体可以同时学习,以发现它们的最优决策策略。
近年来,竞争性 RL 算法已被用于训练各种游戏和优化问题的高性能人工智能。了解训练这些人工智能模型的基本算法对于利用这些工具应对现实世界的挑战至关重要。网络安全领域正在考虑将竞争性 RL 的新兴研究成果应用于现实世界。
为了利用 RL 开发自动化网络行动(ACO) 工具,可以使用各种环境模拟网络安全事件。其中许多 ACO 环境都是在过去三年中开源的。这些新环境促进了探索人工智能在网络安全方面潜力的研究。这些环境中的现有研究通常是片面的:红方或蓝方智能体接受训练,针对具有固定策略的静态对手优化决策。
通过只针对一个对手或一组静态对手进行训练,学习型人工智能在面对场景中其他所有可能的对手时都无法保持高性能。竞争性 RL 可用来发现对抗环境中任何潜在对手的最佳决策策略。然而,在这些新兴的 ACO 模拟中还没有尝试过。本论文的目的是使用竞争性 RL 训练智能体,使其在模拟 ACO 环境中接近博弈论中的最优策略。
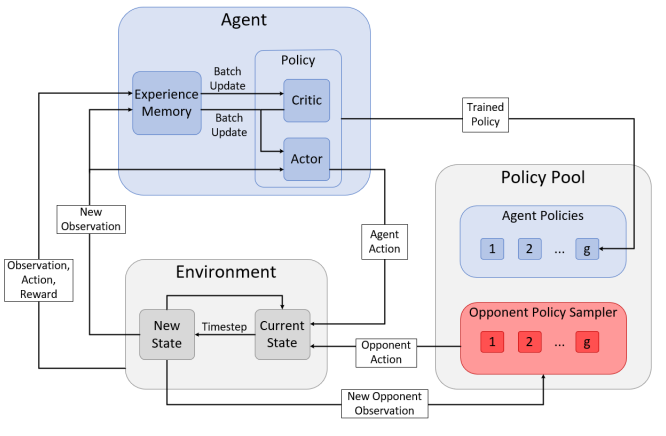
图 4:虚构游戏过程中使用的系统概览,包括actor-critic框架和对手采样。切换代理和对手,为对手的策略库训练新策略。
成为VIP会员查看完整内容
相关内容

Arxiv
42+阅读 · 2023年4月19日
Arxiv
219+阅读 · 2023年4月7日
Arxiv
151+阅读 · 2023年3月29日
Arxiv
84+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
219+阅读 · 2023年4月7日
Arxiv
151+阅读 · 2023年3月29日
Arxiv
84+阅读 · 2023年3月21日