

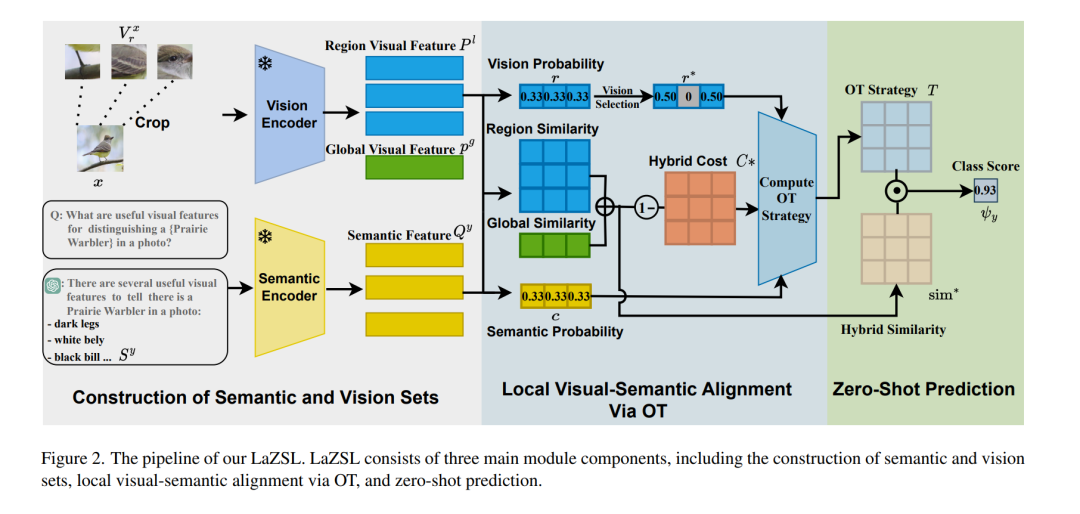
大规模视觉-语言模型(VLMs),如 CLIP,通过利用大规模图文对数据集,在零样本学习(ZSL)任务中取得了显著成功。然而,这类方法通常缺乏可解释性,因为它们是通过计算整张查询图像与类别词嵌入之间的相似度来进行预测,难以解释其决策过程。为了解决这一问题,一种思路是通过引入语言构建可解释模型,即使用离散属性构建分类器,模仿人类感知方式。这带来了一个新的挑战:如何在预训练的视觉-语言模型基础上,有效对齐局部视觉特征与对应的属性。 为此,我们提出了一种用于可解释零样本学习的局部对齐视觉-语言模型——LaZSL。LaZSL 通过最优传输实现局部视觉-语义对齐,使视觉区域与其相关属性之间能够有效交互,从而实现有效对齐,并在无需额外训练的前提下提供可解释的相似性度量。大量实验证明,我们的方法在可解释性、准确性和跨领域泛化能力方面均表现出明显优势。 代码地址:https://github.com/shiming-chen/LaZSL
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
213+阅读 · 2023年4月7日


相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
213+阅读 · 2023年4月7日