

今天给大家讲一篇2023年3月在Nature Machine Intelligence上发表的一篇关于预训练模型如何进行微调的文章。作者提出一种增量式微调方法(Delta-tuning),即仅微调模型参数的一小部分,而其余部分保持不变。进一步,作者在超过 100 个 NLP 任务的结果展示了不同方法的性能比较后发现该方法可以避免重新训练整个模型,并降低计算和存储成本。在某些情况下可以获得与微调相当的性能。
预训练-微调范式研究背景
以Transformer模型为主的预训练语言模型(PLMs)现今已广泛运用于NLP任务。该类模型通常以自回归或序列到序列的方式作为模型基本架构。此外,随着各自不同模型的衍变,如何有效地让大模型适应特定的下游任务成为一个重要的研究问题。这里提出一个概念,全参数微调,即用预训练的权重初始化模型,更新所有参数,并为不同的任务生成单独的实例。然而在处理大模型时,除了部署和计算的成本开销较大,为不同的任务存储不同的实例也占较大内存。自适应微调方法如LoRA模型将注意力权重更新分解为低秩矩阵,以减少可训练参数的数量。此外,Delta-Tuning(增量微调)也是一种减少计算成本的微调方法,如图1所示,其主要分为三种,其一为引入额外的参数,训练时调整这些新增的参数,其二是冻结其他参数,只针对模型的部分参数进行训练。其三是针对模型的参数进行重新参数化,使其用于后续的训练中。

方法介绍
**2.1 增量式方法
增量式方****法通过引入了原模型中额外的可训练的模块以及参数来对模型进行微调,两个有代表性的方法为基于自适应的方法及基于提示的方法。前者是将小的模块加入到Transformer不同层中,且只微调这几个模块,进一步将输入特征投影到一个低维空间中。总的来说,基于自适应方法的微调可以在少样本和跨语言场景下比简单微调效果更好。基于提示的方法为仅在输入层中加入软提示,该引入的提示不是由预训练模型进行参数化得到的,而是一个附加的参数矩阵。在训练过程中,冻结模型其他参数,利用梯度下降方法更新软提示的参数。
**2.2 特定式方法
该方法通过微调固定参数,同时让模型自适应地微调一些固定参数,而保持其余参数不变,它并不改变模型的内部结构,而通过优化少量的参数来自适应处理特定的任务。
**2.3重参数式方法
重参数化方法可以将优化复杂度从高维压缩到低维,并使得微调时只在低维子空间内进行优化,从而降低计算和内存成本,该方法可以获得相较于微调方法相当的性能。LoRA假设在模型微调过程中变化的权重具有较低的秩,据此则提出对自注意力模块中原始权重矩阵进行低秩分解。通过这种方式,LoRA的结果与GLUE基准上的微调性能相当,表明该方法的有效性。
实验结果
**3.1收敛率及效率分析
作者从Huggingface数据集上选择了100多种有代表性的任务,并且将提示微调、固定微调、LoRA及自适应方法在不同的时间步上进行比较。如图2所示,微调方法(FT)是其中收敛最快的。此外,在相当长的时间步范围内,各个方法的性能和收敛性对进行微调的参数数量不敏感,而对微调的方法较为敏感。在效率方面,主要分为两点,其一是Delta-Tuning的结构可能对反向过程的时间产生相当大的影响,即增量式微调的反向时间比仅仅微调更短。其二是随着预训练模型规模的扩大,Delta-Tuning的收敛速度也在增长。
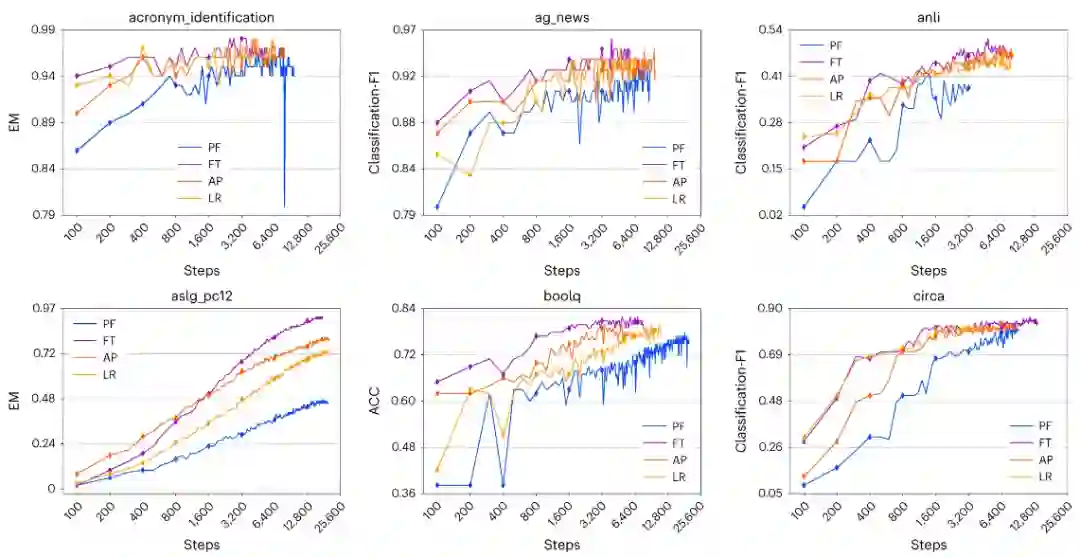
图2 与基准方法比较收敛率、准确率、F1
**3.2 预训练模型规模比较
随着预训练模型规模的增长,提示微调在性能上更有优势,并且对于具有超过100亿参数的预训练模型,提示微调甚至可以达到与完全微调相当的性能,而且提示微调的收敛速度也更快。作者探讨其他Delta-Tuning方法是否也具有类似结论,首先选择MNLI和QNLI两个自然语言推理数据集,三个预训练模型(T5SMALL、T5BASE和T5XXL),三者的规模逐渐增大,以此来评估五种代表性的Delta-Tuning方法的性能。如图3所示,随着预训练模型规模的增大,所有的Delta-tuning方法在性能和收敛速度方面都有了显著的提升。同样证明了上述观点。
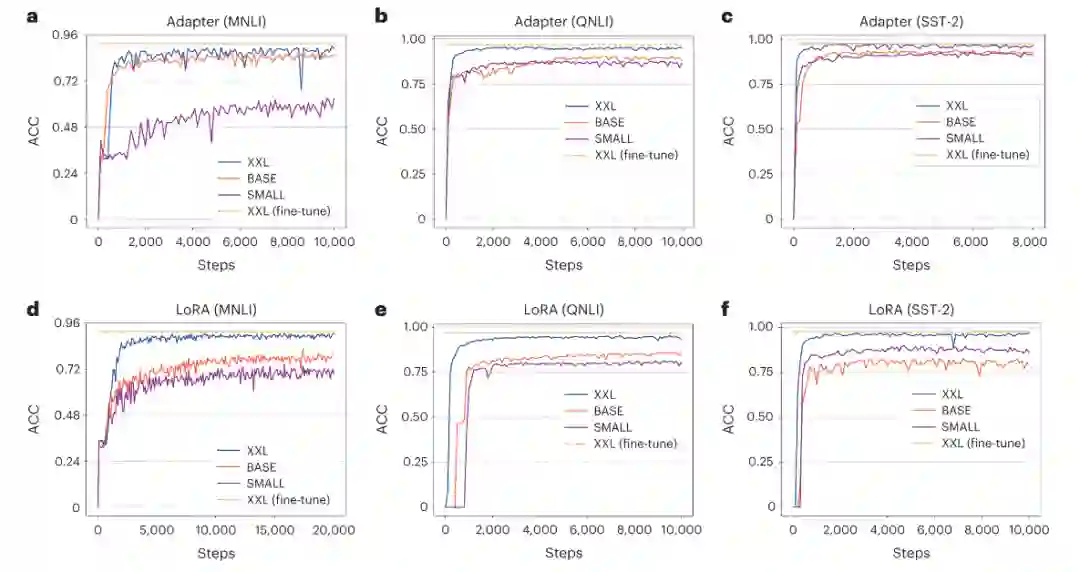
图3 Delta-tuning中的预训练规模比较
结论
作者聚焦于增量式微调方法如何运用于预训练模型中。首先提出了两个框架,即分别从优化和最佳控制角度分析增量式微调。从实验结论上看,作者在100多个NLP任务上进行了广泛的实验,以便对任务级可迁移性,Delta-tuning方法的组合及规模进行评估,为该方法的设计提供了理论依据。此外,Delta-tuning可以大大减少存储空间,加速反向传播,并获得与微调近似的效果。总之,Delta-tuning在深度挖掘 预训练模型潜力方面 表现出了相当的优势。参考文献
Cummings, M. D. & Sekharan, S. Structure-based macrocycle design in small-molecule drug discovery and simple metrics to identify opportunities for macrocyclization of small-molecule ligands. J. Med. Chem. 62, 6843–6853 (2019)



