

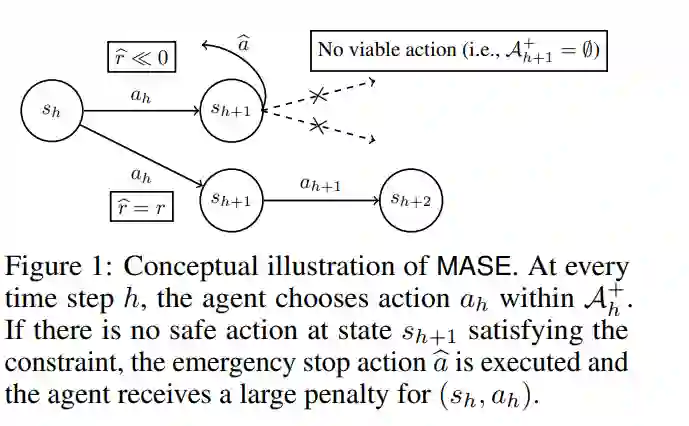
在许多实际情境中,安全探索对于增强学习(RL)的实用性至关重要。在本文中,我们提出了一个通用安全探索(GSE)问题,作为常见安全探索问题的统一公式。接着,我们提出了一个安全探索的元算法MASE作为GSE问题的解决方案,该算法结合了一个无约束的RL算法和一个不确定性量化器,以保证在当前情节中的安全,同时在实际安全违规之前适当地惩罚不安全的探索,以防止它们在未来的情节中出现。MASE的优势在于,我们可以在保证有很高概率不会违反任何安全约束的情况下,优化策略。具体来说,我们提出了两种不同构造的不确定性量化器的MASE变体:一种基于带有安全和接近最优性理论保证的广义线性模型,另一种结合了高斯过程以确保安全性和深度RL算法以最大化奖励。最后,我们证明了我们提出的算法在格子世界和Safety Gym基准测试中比现有技术更优秀,即使在训练期间也不违反任何安全约束。
https://www.zhuanzhi.ai/paper/bfda323a5d9d59281497f4e599b516b8
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日