
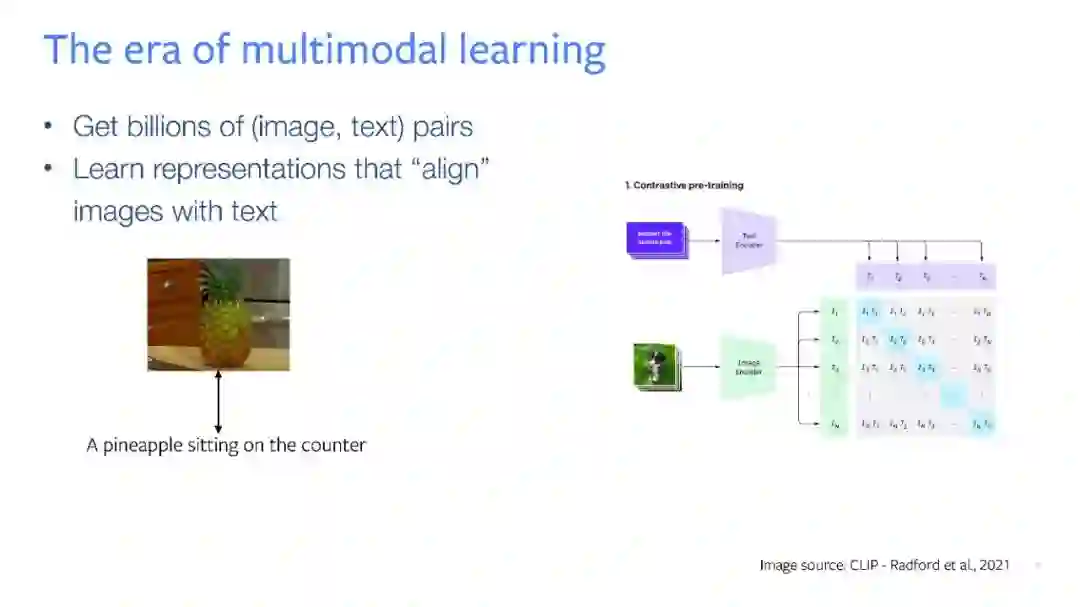
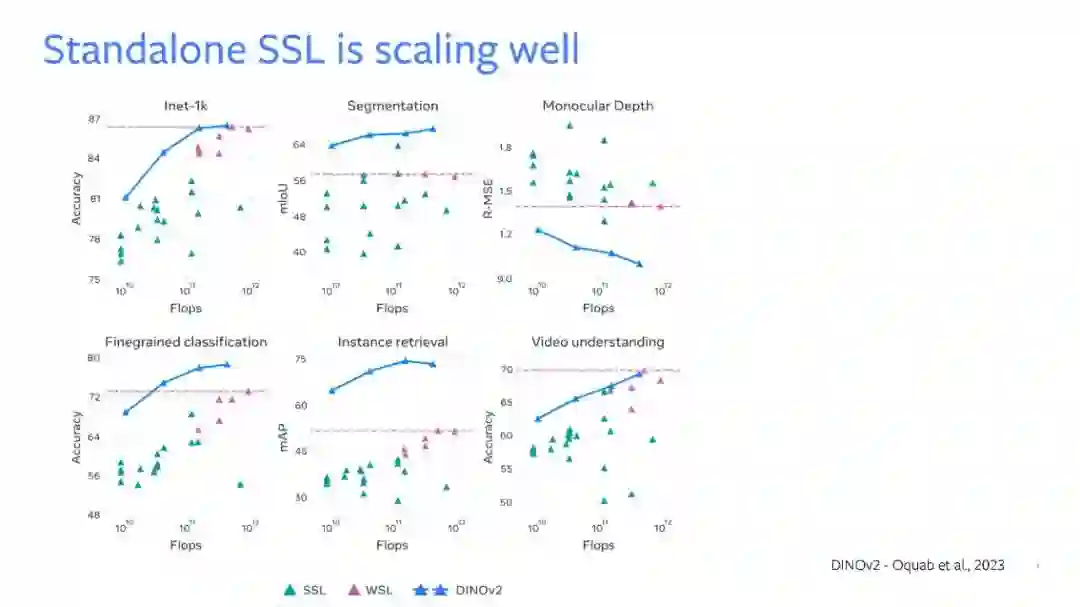
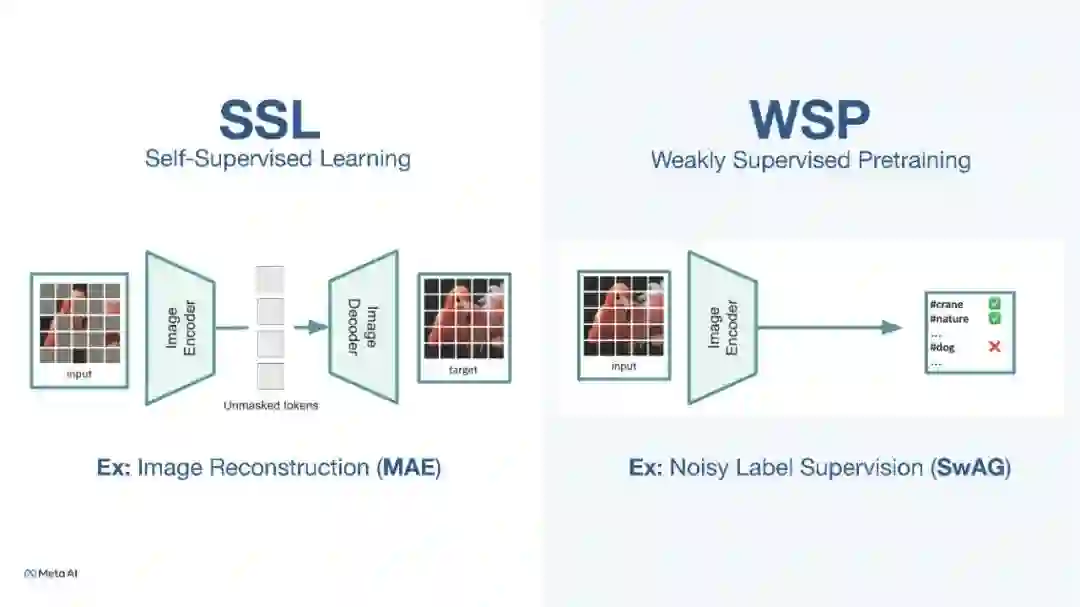
在本次演讲中,我将展示如何利用自监督学习来改进基础的多模态模型,使其能够扩展到更多的模态、学习到更好的表示,并提高其效率。训练基础多模态模型时的一个大挑战是配对数据的稀缺性。虽然我们有大量的(图像,文本)数据,但其他模态,如深度或IMU的数据集整体上则是有限的。我们在这方面的首次尝试名为ImageBind,它展示了图像可以用作一个通用的信号来“绑定”多种不同的模态。我们证明了自然出现的图像配对,如(图像,IMU),(图像,深度)可以被自动用来学习一个共享的嵌入空间,其中未见过的模态对是对齐的。ImageBind实现了零射击识别、跨模态检索和生成的新能力。我们的第二项工作显示,使用自监督学习作为“预”预训练阶段可以改进多模态(图像,文本)表示,在各种模型大小和数据大小上都有所表现。预预训练提高了数十亿参数在数十亿图像上训练的基础模型的性能,同时也加速了它们的收敛。由此产生的模型在完全微调、线性探测、图像和视频领域的零射击识别任务上都展现出了最先进的性能。




成为VIP会员查看完整内容
相关内容
专知会员服务
26+阅读 · 2022年3月1日
专知会员服务
25+阅读 · 2020年7月1日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日

相关VIP内容
专知会员服务
26+阅读 · 2022年3月1日
专知会员服务
25+阅读 · 2020年7月1日
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日