

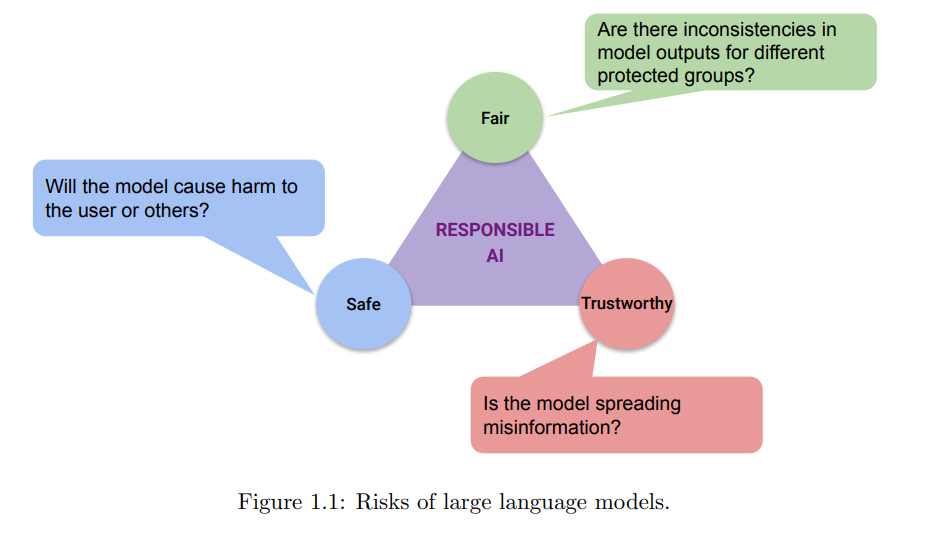
大型语言模型推动了自然语言处理领域的最新进展,并在摘要生成、问题回答和文本分类等任务中取得了成功。然而,这些模型是基于大规模数据集进行训练的,这些数据集可能包含有害信息。研究表明,因此,这些模型在训练后可能会表现出社会偏见,并产生错误信息。本论文讨论了在公平性、可信赖性和安全性领域分析和解释大型语言模型风险的研究。
论文的第一部分分析了大型语言模型中与社会偏见相关的公平性问题。我们首先研究了与非裔美国英语和标准美国英语相关的方言偏见问题,以及在文本生成的背景下的这些问题。我们还分析了更复杂的公平性设置:多个属性相互影响以形成复合偏见的情况。这在与性别和资历属性的关系中进行了研究。
第二部分专注于可信赖性和在不同范围内传播错误信息的问题:预防、检测和记忆。我们描述了一个用于新兴领域的开放域问答系统,该系统使用各种检索和重新排名技术,为用户提供来自可信来源的信息。这在新兴的 COVID-19 大流行的背景下得到了证明。我们进一步致力于通过创建一个大规模数据集来检测潜在的在线错误信息,该数据集将错误信息检测扩展到图像和文本的多模态空间。由于错误信息可能是人类编写的,也可能是机器编写的,我们研究了通过阴谋论的视角来记忆和随后生成错误信息。
论文的最后一部分描述了关于可能导致物理伤害的文本的 AI 安全方面的最新工作。这项研究分析了在包括生成、推理和检测在内的各种语言建模任务中的隐蔽不安全文本。
总体而言,这项工作揭示了大型语言模型中未被发现和代表性不足的风险。这可以推动当前研究朝着构建更安全、更公平的自然语言处理系统的方向发展。我们最后讨论了扩展这三个领域工作的负责任 AI 的未来研究。


成为VIP会员查看完整内容
相关内容
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日