语言模型(LM)基于深度神经网络(DNN)的构建,最近在软件工程任务中,如代码生成、代码补全和代码修复,表现出了突破性的效果。这为基于语言模型的代码优化技术的出现铺平了道路,这些技术对于提升现有程序的性能,特别是加速程序执行时间,具有重要意义。然而,专门针对这一特定应用的全面综述尚缺乏。为了解决这一空白,我们进行了一项系统的文献综述,分析了超过50篇核心研究,识别出新兴趋势并回答了11个专业性问题。结果揭示了五个关键的开放性挑战,例如平衡模型复杂性与实际可用性、提升模型的普适性以及建立对人工智能驱动解决方案的信任。此外,我们提供了八个未来的研究方向,以促进更高效、稳健和可靠的基于语言模型的代码优化。因此,本研究旨在为快速发展的这一领域的研究人员和从业人员提供可操作的见解和基础性参考。
1. 引言
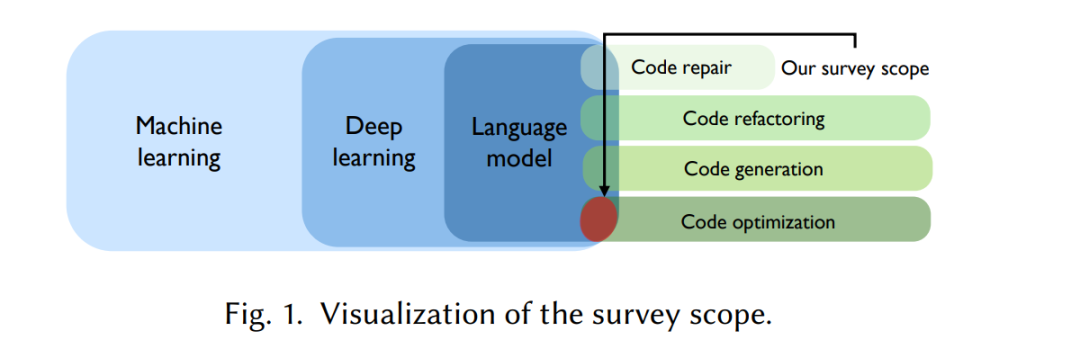
代码优化,或程序优化,长期以来一直是计算领域中的一项重要任务[137]。代码优化通过在不同层级上转换程序——如源代码[119]、编译器中间表示[28]或二进制[11, 36, 78]——以实现特定的性能目标,例如减少执行时间[84]、最小化代码大小[48, 111]或优化内存使用[39]。它支撑着广泛的软件工程(SE)任务,包括代码生成[71]、代码修复[65]、代码编辑[51]和代码改进[158]。
传统上,代码优化依赖于专家设计的启发式方法和规则[137]。这些技术通常与基于编译器的代码分析[146]相结合,以捕获程序的关键属性,例如数据和控制依赖,进而识别出优化代码的最有效方法。随着时间的推移,已经开发出多种优化技术,涵盖从低级策略,如指令调度[33]、寄存器分配[19]、向量化[3]和循环转换[139]——这些通常应用于编译器的中间表示或链接时优化——到更高级的策略,旨在通过在源代码级别更改算法或数据结构来提高性能[112]。
代码优化的一个关键挑战是存在大量可能的优化方式,使得穷举搜索在计算上是不可行的,通常需要耗费大量的计算资源来全面探索[112]。在这个庞大的优化空间中,好的优化往往是稀缺的,并且在不同的程序之间差异很大[48, 137]。对于低级性能优化,最佳优化往往依赖于底层计算硬件[26, 132]。这使得手工设计有效的优化策略变得极为具有挑战性。即使能够开发出一种调优良好的启发式方法,它也可能需要随着应用负载和计算硬件的变化而进行调整[29]。
在过去的几十年中,已有大量研究探讨了机器学习在代码优化中的应用[7, 12, 137]。现有的证据充分表明,机器学习技术在各种代码优化任务中具有显著的效果[137]。更近些年,基于深度神经网络(DNN)的语言模型(LM)和生成性人工智能(genAI)的出现,标志着这一领域的重要突破[119]。这些先进的模型在从训练数据中提取知识并将其迁移到测试样本中表现出了强大的能力[44],并在性能上超越了传统的机器学习方法[26]。它们能够对复杂的代码结构进行建模和推理,进一步推动了将语言模型应用于软件工程的广泛研究[57],并在自动化和增强代码优化过程中取得了良好的成果。机器学习、语言模型和代码优化之间日益增强的协同作用,为这一领域的研究和创新开辟了新的方向。
然而,尽管基于语言模型的代码优化在不断增长的重要性和前景中取得了显著进展,现有文献中关于语言模型在代码相关任务中的应用的综述大多集中在它们在软件工程中的一般应用[79]或特定领域,如自动程序修复[155]。值得注意的是,文献中仍然存在一个重要的空白——尚没有系统地综述基于语言模型的代码优化技术。正如图1所示,本文旨在填补这一空白,提供一项系统的文献综述(SLR),聚焦于基于语言模型的最前沿代码优化方法。具体来说,我们通过六个学术索引引擎进行检索,识别并系统地回顾了53篇核心研究[1]。基于四个研究问题(RQ)和11个具体的子问题,我们对这些研究进行了分类,概括了结果中的关键发现,并为读者提供了有价值的建议。例如,我们的主要发现包括:
-
像 GPT-4 这样的通用语言模型(LM)被比专门用于代码的语言模型(43个实例)更广泛地采用(61个实例),这是由于其更广泛的理解和推理能力。
-
大多数研究(57%)利用了预训练模型,以节省时间和资源,而43%的研究通过微调模型来定制任务特定需求。
-
最常被提到的挑战是性能和代码相关的问题,例如一步优化的限制(18项研究)、平衡正确性和效率(15项研究)以及代码语法的复杂性(10项研究)。
-
大多数研究通过设计专门的模型(51个实例)来解决现有挑战,这些模型虽然有效,但缺乏通用性。提示工程(Prompt Engineering)作为第二大类(34个实例)因其数据效率而脱颖而出,尽管依赖于专家知识。另一类则通过提出新的代码优化问题(33个实例)提供了更大的优化灵活性,但也需要大量的数据集准备工作。
此外,我们还揭示了现有文献中的五个关键挑战,并提供了未来研究的潜在方向,总结如下:
-
语言模型(LM)的规模和复杂性的增加要求在大规模代码库中进行代码优化时,需要大量的计算资源,这就提出了模型压缩和集成技术的需求。
-
基于语言模型的代码优化方法通常在孤立的环境中操作,缺乏与外部系统的无缝集成,强调了具有主动性(agentic)的语言模型的重要性。
-
单语言研究的主导地位(81%)和对单一性能指标的强调(79%)凸显了通用性问题,以及对多语言和多目标优化方法的需求。
-
大多数基于语言模型的方法的研究(68%)是在合成数据集上进行评估的,而不是在更大且更复杂的真实世界代码库上进行的,这表明需要标准化基准测试,以反映不同的真实世界场景。
-
语言模型常常生成不一致或幻觉化的输出,因此人类与语言模型的协作对于利用AI的计算能力至关重要,同时确保优化结果的可信度和可靠性。
本文的其余部分安排如下:第2节阐述了代码优化技术的演变。第3节概述了采用的系统文献综述(SLR)方法论。第4、5、6和7节分别展示了四个研究问题的结果和发现。第8节探讨了现有的挑战和未来方向。最后,第9节总结了本文内容。 方法论
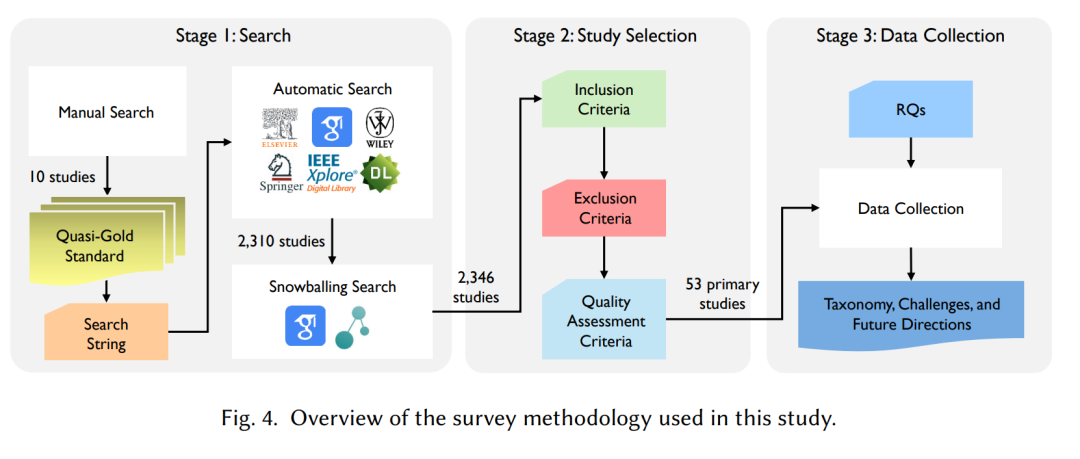
本次调研遵循了Kitchenham和Charters[69]提出的软件工程领域系统文献综述(SLR)指南,这些指南也被许多SLR研究所采纳[44, 57, 134, 143, 155]。如图4所示,研究方法包括三个关键阶段:
- 搜索:进行了全面的自动化检索,使用了精心定义的搜索字符串,遵循“准黄金标准”方法论[152],并辅以雪球式搜索,以确保覆盖面广泛。
- 研究选择:对检索到的研究进行严格的纳入和排除标准筛选,随后进行质量评估,只包含可靠且高质量的研究。
- 数据收集:制定了四个主要研究问题(RQ),包含11个具体问题,以指导数据提取和分析,最终得出本次调研的主要成果。
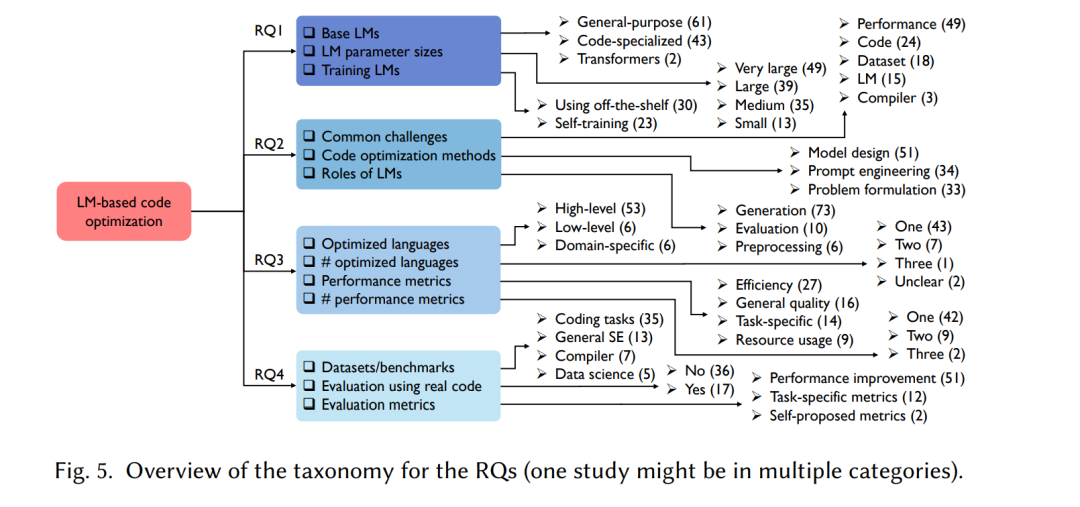
图5提供了所有问题的分类概述,接下来的各节将分别介绍每个研究问题的详细分类、发现和可操作建议。