口语语言处理领域正经历一场从为特定任务量身定制模型的训练范式,向使用并优化口语语言模型(Spoken Language Models, SLMs)这一通用语音处理系统的转变。这一趋势类似于文本自然语言处理领域中向通用语言模型发展的过程。 SLMs 既包括对语音进行建模的“纯”语言模型——即对标记化语音序列分布的建模,也包括将语音编码器与文本语言模型结合的混合模型,这类模型通常支持语音与文本的输入或输出。 该领域的研究极为多样,涵盖广泛的术语体系与评估设定。本文旨在通过统一视角下的文献综述,帮助读者更深入理解 SLMs,并将相关研究置于该领域演进的背景之中。 我们的综述从模型架构、训练策略与评估方法三方面对现有工作进行了分类,并指出了当前面临的关键挑战及未来研究方向。
1 引言
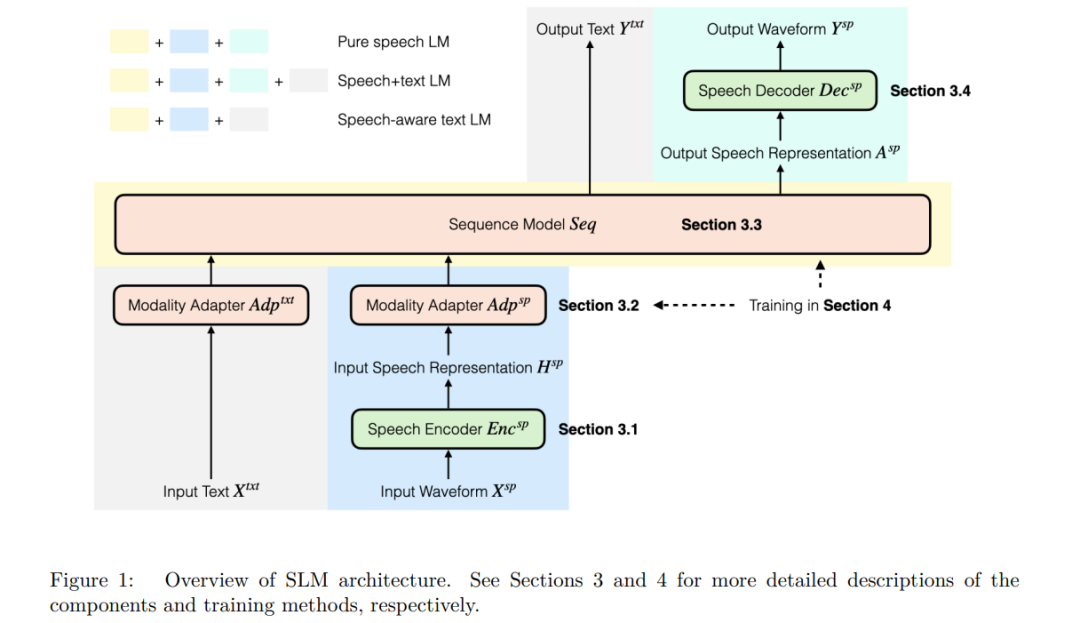
在过去的几年中,自然语言处理(NLP)领域经历了显著演进,从(1)从零开始训练大量任务专用模型,发展到(2)将预训练的多用途上下文表示模型(如 BERT(Devlin et al., 2019))与少量任务特定参数结合使用,再到(3)训练生成式的通用大型语言模型(LLMs(Brown et al., 2020;OpenAI et al., 2024)),这些模型能够在给定自然语言指令(提示)的情况下执行任意文本任务,并具备在新领域和新任务上的泛化能力(Wei et al., 2022a;Liu et al., 2023),最终发展为(4)能与用户直接交互、执行任务的对话系统/聊天机器人助手。 语音处理领域也在经历类似的演进,尽管略为滞后,当前主要集中在阶段(1)和(2)。在语音识别(ASR)、语音翻译(ST)、口语理解(SLU)以及说话人识别(SID)等常见的专用语音任务中,当前的最先进方法通常将一个预训练的自监督编码器模型(Mohamed et al., 2022)与任务特定的预测“头部”结合使用。对于某些高资源语言中的常见任务(如 ASR 和 ST),大型监督模型(Radford et al., 2023;Peng et al., 2023b)也展现出持续优异(即使不是 SOTA)性能。 近期研究开始发展口语语言模型(SLMs),类比于文本领域的 LLMs,这些模型在理论上能够在给定自然语言指令的条件下执行任意语音任务。然而,“SLM”这一术语尚未在文献中标准化,其适用范围比文本语言模型更广。当前出现了几类常被统称为 SLM 的模型类型: 1. 纯粹的 SLMs:建模语音分布 p(speech)p(\text{speech})p(speech) 的模型,通常仅在无标签的标记化语音数据上进行下一步标记预测目标训练,类似于文本 LLM 的预训练阶段(Lakhotia et al., 2021); 1. 语音+文本 SLMs:建模语音与对应文本联合分布 p(text,speech)p(\text{text}, \text{speech})p(text,speech) 的模型,通常使用配对的语音-文本转录数据训练,可视为第(1)类模型的直接扩展(Nguyen et al., 2025); 1. 具备语音感知能力的文本 LMs:将文本 LLM 与预训练的语音编码器结合,保留文本 LLM 的指令跟随(Instruction Following, IF)能力,同时具备对语音输入或音频进行推理的能力(Tang et al., 2024;Chu et al., 2023)。这类模型建模条件分布 p(text∣speech,text)p(\text{text}|\text{speech}, \text{text})p(text∣speech,text),以文本作为输入提示,对语音输入生成响应文本。
类比文本 LLMs,第(1)类与第(2)类模型可视为预训练 LLM 的语音版本。这些模型也可通过提示、偏好或其他方式进行后训练(post-training),以学习所需输出语音(第1类)或语音+文本(第2类)分布。在第(3)类中,模型通常基于已微调的文本 LLM 进行进一步后训练,使其对齐语音与文本表示,并执行新的语音任务。 尽管这些模型使用了不同的先验与建模方法,所有上述三类 SLM 都可视为迈向通用语音处理系统的重要步骤。本文将通用语音处理系统定义为满足以下条件的模型: 1. 具备语音输入与语音输出,文本输入与/或输出为可选项。语音输入可作为指令或上下文; 1. 模型具有“通用性”,即原则上应能够处理任意口语任务,包括传统任务与更复杂的语音数据推理任务; 1. 模型接收自然语言形式的指令或提示(语音或文本均可),而不仅限于任务标识符(Radford et al., 2023)或软提示(Chang et al., 2024)。
这是一个功能性定义,并未限制模型的形式。我们也指出,目前多数文献中的模型(包括本文综述的)并未同时满足上述所有标准,例如许多模型并不具备语音输入与输出的能力,且训练与评估时所涵盖的任务范围有限。尽管如此,这些模型均可被视作通往通用语音处理系统道路上的重要一步,正如预训练与后训练的文本 LLM 是实现通用书面语言处理系统的关键里程碑一样。 或许有人会提出,将语音识别、文本 LLM 与语音合成串联是否更适合作为通用语音处理路径。事实上,这对许多任务来说确实是一个强基线方法(Huang et al., 2025;Yang et al., 2024b)。然而,有些任务需要访问音频信号中除文本字符串以外的信息,例如说话者特征、情绪状态、语调或其他声学属性。此外,即使对于仅依赖文本内容即可完成的任务,端到端的 SLM 也能避免串联系统中 ASR、LLM 与 TTS 所引入的误差叠加与效率损失问题。 近年来,SLM 的研究进展迅速,但对该领域设计与建模决策的深入综述仍相对有限。此外,这些模型往往在不同任务与数据集上进行评估,难以对比不同方法的相对性能。作为本综述的一部分,我们收集并整理了当前已有的评估方法(尽管标准化评估仍是一项亟待解决的挑战)。此外,由于 SLM 的定义因应用场景与建模思路而异,我们也在本文中提出了统一的 SLM 描述框架与术语体系(见第2节)。 本综述旨在作为该领域演进现状的一份“快照”,回顾近期研究成果,并统一界定 SLM 及其组成部分。虽然新的 SLM 模型仍在不断涌现,我们希望通过本综述帮助读者更好地理解新模型所处的语境,并厘清当前 SLM 所取得的成就与仍存的局限,助力未来构建真正的通用语音处理系统。
本文综述范围
尽管通用目标是构建可通过自然语言指令完成任意任务的模型,但目前许多受语言模型启发的方法仍然是任务特定的。例如,Whisper(Radford et al., 2023)与 OWSM(Peng et al., 2023b)等模型属于条件概率模型 p(text∣speech)p(\text{text}|\text{speech})p(text∣speech) 的特例,用于语音识别与翻译;VALL-E(Chen et al., 2025b)与 VoiceBox(Le et al., 2024)属于 p(speech∣text)p(\text{speech}|\text{text})p(speech∣text) 的条件生成模型,用于文本到语音的合成。此外,一些模型虽然更具通用性,但依赖于任务标识符或软提示(如 Qwen-Audio(Chu et al., 2023)与 SpeechPrompt(Chang et al., 2024))。本综述聚焦于原则上具备任务无关性、并且以自然语言作为输入的模型(即不依赖任务 token 或软提示)。当然,我们也会在相关背景下讨论若干重要的任务特定模型。 此外,如第2节所述,SLM 通常由多个模块组成,包括语音编码器、语音解码器、语音-文本对齐模块(如适用)以及序列建模模块。本文将简要介绍语音的编码与解码过程(已有较多综述对此进行了充分讨论,如 Wu et al., 2024a),重点放在序列建模与语音-文本对齐等 SLM 特有方面。 最后,音乐与一般音频在多个方面与语音相似。已有多种语言建模方法专门针对音乐与通用音频(如 Copet et al., 2023;Agostinelli et al., 2023),且部分 SLM 研究已将语音与其他音频信号结合(如 Gong et al., 2023b)。本综述仅在音频用于 SLM 的上下文中涵盖非语音音频内容。
相关综述
为了便于定位本文在现有研究中的位置,我们指出已有若干综述探讨了与 SLM 相关的部分内容。Zhang et al.(2024a)与 Chen et al.(2024a)对多模态 LLM 进行了综述,涵盖了部分 SLM。Latif et al.(2023)则综述了大规模音频模型,覆盖了更广泛的音频语言模型(包括环境声音、音乐等),但对 SLM 的细节覆盖不足,亦未纳入近年来的指令跟随类模型。Wu et al.(2024a)综述了神经音频编解码器及基于编解码器的模型(第3节将涉及),其关注点主要在语音标记化,而非完整 SLM 系统。Guo et al.(2025)也综述了标记化方法。Ji et al.(2024)则聚焦于 SLM 在对话系统中的应用。Peng et al.(2024a)则关注于语音感知型文本语言模型,但未涵盖其他类型的 SLM。Cui et al.(2024)有一项与本文并行的综述,涵盖类似范围的 SLM,我们的工作在历史演进脉络与模型分类方法上提供了互补视角。
内容结构
在接下来的章节中,我们将首先给出 SLM 的统一建模形式(第2节),接着讨论其设计选择(第3节),包括语音编码器与解码器、模态适配器与序列建模方法。第4节介绍 SLM 的多种优化训练流程,第5节则对若干代表性模型进行回顾与分类。第6节探讨 SLM 向对话模式(即“全双工”)的适配,第7节介绍 SLM 的现有评估方式。最后,第8节总结当前方法的局限性并提出未来研究建议。