
大语言模型在序列推荐中的应用
一、简介
序列推荐技术通过分析用户的过往交互历史,能够有效挖掘出用户可能感兴趣的项目,对于提升各类应用的服务质量具有重要作用。近期,大语言模型(LLMs)的发展在应对复杂的推荐问题上展现出了显著的优势。不过,这种方法也面临一些挑战。本篇文章将重点探讨两项将大语言模型应用于序列推荐领域的相关研究。
二、Enhancing Sequential Recommendation via LLM-based Semantic Embedding Learning(WWW2024)
该框架利用大型语言模型(LLMs)显式学习基于文本的语义对齐项目ID嵌入。具体来说,SAID为每个项目使用了一个投影模块,将项目ID转换成一个嵌入向量,该向量会被输入到LLM中以产生与项目相关的精确描述性文本标记。这样做是为了使项目嵌入能够保持文本描述的细微语义信息。此外,学习到的嵌入可以与轻量级的下游序列模型结合,用于实际的推荐任务。通过这种方式,SAID避免了之前工作中存在的长令牌序列问题,减少了工业场景下的资源需求,并实现了更优秀的推荐性能。
2.1 总体框架
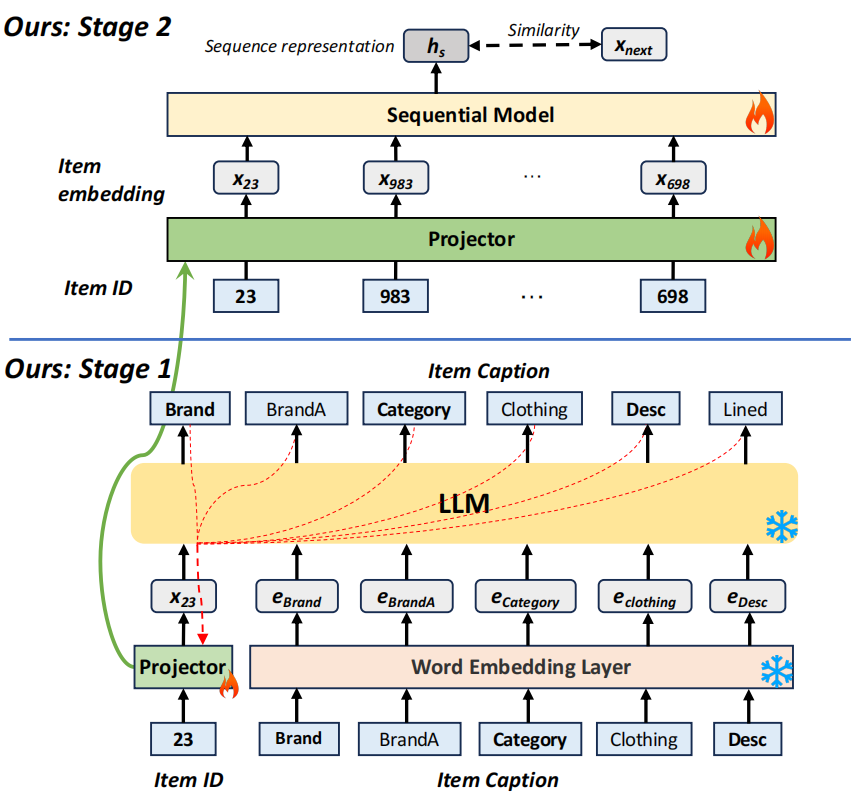
SAID的整体架构分为两个阶段:第一阶段是语义对齐嵌入学习,第二阶段是模型无关的序列推荐器训练。在第一阶段,SAID通过一个投影模块和现成的LLM来学习每个项目的嵌入。每个属性的嵌入大小等于特定LLM中单个令牌的嵌入大小。在第二阶段,第一阶段获得的嵌入作为初始特征被输入到下游模型(如RNN或Transformer)中进行序列推荐。值得注意的是,SAID对下游模型的具体选择具有高度的适应性和灵活性。
2.2 语义对齐嵌入学习
设表示参数集为𝜃的投影仪模块,则项目𝑖的嵌入可以表示如下: 投影模块的训练目标是确保生成的嵌入能够保留项目文本描述的细粒度语义信息,从而在LLM的嵌入空间中产生语义对齐的嵌入。具体实现上,SAID将项目ID通过投影模块转换为一个嵌入向量,然后将这个嵌入向量作为输入传递给LLM。LLM的任务是从给定的嵌入向量中生成项目的确切描述性文本标记。例如,对于项目23,其投影的语义嵌入将被送入LLM,LLM期望输出项目文本描述的第一个标记‘Brand’。接下来,和‘Brand’的词嵌入一起作为输入,LLM预期生成‘BrandA’。所有LLM输出标记的误差将反向传播以调整投影模块的参数。
2.3 模型无关的序列推荐器训练
在完成了第一阶段的投影模块训练后,可以为每个项目获得其语义对齐的嵌入。如图所示的第二阶段,这些由投影模块产生的嵌入可以无缝地与下游的序列模型集成,用于推荐任务。这一特性使得SAID对下游推荐模型的选择具有高度的灵活性和适应性。需要注意的是,为了进一步提高训练和推理的效率,本文将作为单个项目的表现形式,而不是通过序列模型来传递它,以期望模型能够自动学习与真实下一项的表示之间的关联性。
2.4 实验结果
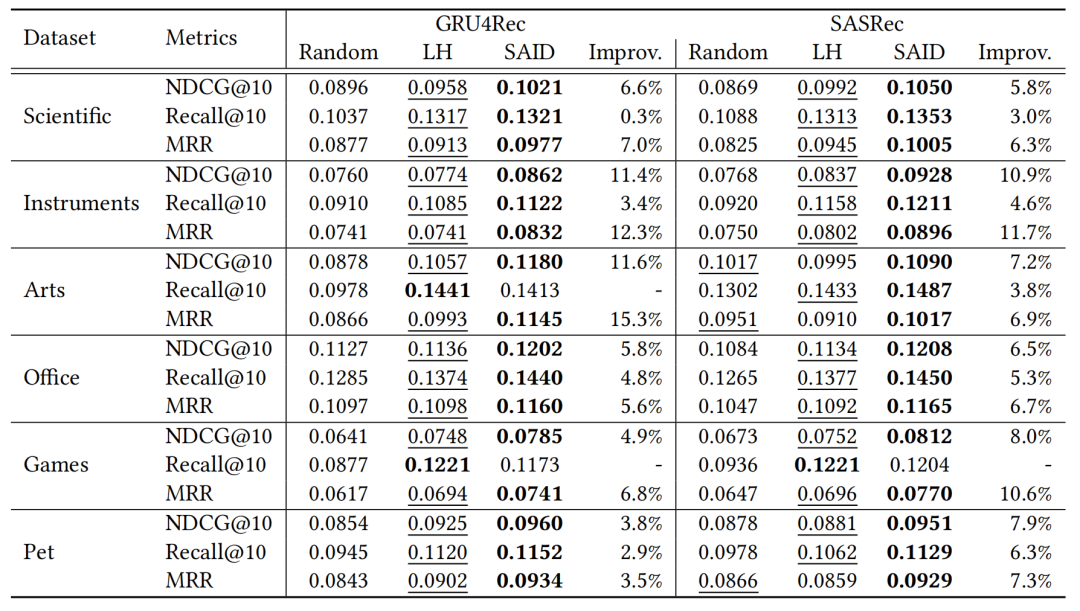
实验部分在六个公开数据集上进行了测试,结果表明SAID在NDCG@10指标上相比基线方法提高了约5%到15%。此外,SAID已被部署于支付宝的在线广告平台,实现了相对于基线方法3.07%的CPM相对提升,同时在线响应时间控制在20毫秒以内。

三、Text is all you need: Learning language representations for sequential recommendation(KDD2023)
本文提出了一个名为Recformer的新框架,旨在通过学习语言表示来解决序列推荐问题。现有的序列推荐方法通常依赖于明确的项目ID或通用的文本特征来进行序列建模,以理解用户偏好。然而,这些方法在处理冷启动项目或迁移到新数据集时仍面临挑战。Recformer通过将用户偏好和项目特征建模为语言表示,从而克服了这些限制,实现了对新项目和数据集的泛化能力。
3.1 总体框架
Recformer的模型结构下图所示,主要包括以下几个部分:
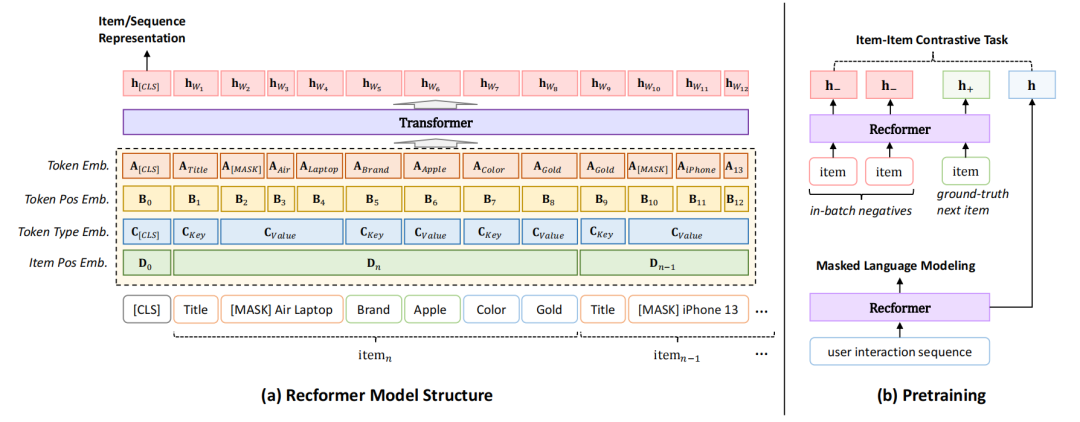
嵌入层:Recformer使用多种嵌入层来编码项目属性。具体来说,每个项目属性都会被转换为一个嵌入向量,包括项目ID嵌入、位置嵌入、类型嵌入和令牌嵌入。这些嵌入层共同作用,使得模型能够更好地理解和捕捉用户行为的动态变化。 双向Transformer编码器:Recformer使用了一个双向Transformer编码器,类似于Longformer,但针对序列推荐任务进行了优化。编码器负责将输入的项目序列转换为高维表示,以便进行后续的推荐任务。 掩码语言建模:为了增强模型的语言理解能力,Recformer采用了掩码语言建模(Masked Language Modeling, MLM)任务。在MLM任务中,模型需要根据上下文预测被掩码的单词。这有助于模型学习项目属性之间的语义关系。 项目-项目对比任务:除了MLM任务,Recformer还引入了一个项目-项目对比任务,以增强模型对项目之间关系的理解。在这个任务中,模型需要区分正样本(即真实的下一个项目)和负样本(即随机选择的其他项目)。
3.2 预训练和微调
为了有效学习语言表示,Recformer提出了一套新颖的预训练和微调方法,结合了语言理解和推荐任务。 预训练:在预训练阶段,Recformer在大规模文本语料库上进行训练,以学习通用的语言表示。预训练的目标是使模型能够理解和生成高质量的文本表示。具体来说,Recformer使用了掩码语言建模(MLM)任务,通过预测被掩码的单词来训练模型。 微调:在微调阶段,Recformer在具体的推荐任务上进行训练,以适应特定的推荐场景。微调的目标是使模型能够根据用户的历史交互序列预测下一个项目。具体来说,Recformer使用了项目-项目对比任务,通过区分正样本和负样本来训练模型。
3.3 算法流程
Recformer的算法流程如下:

3.4 实验结果
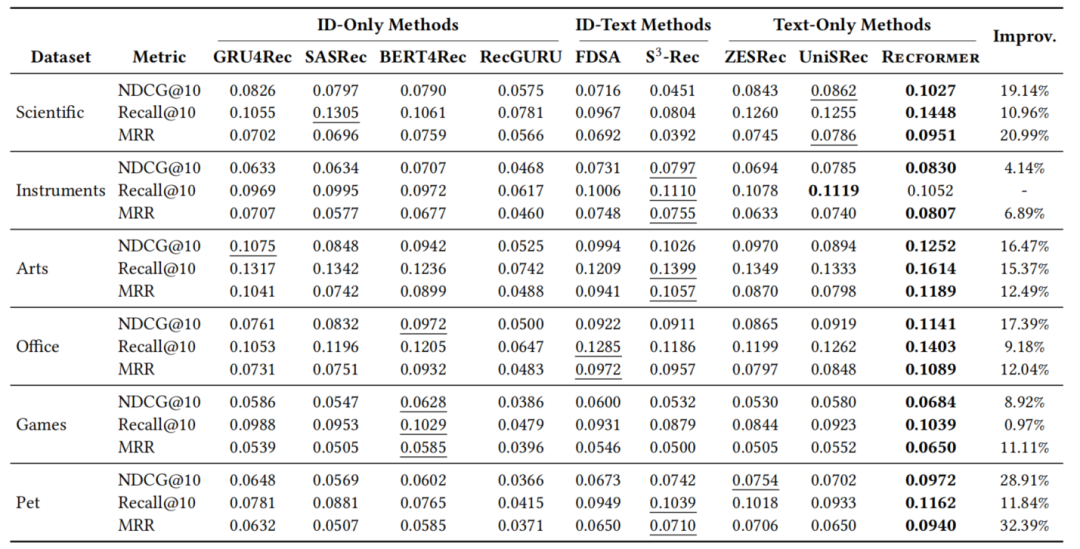
实验结果表明,Recformer在所有数据集上都表现优异,特别是在NDCG@10和MRR指标上。与最佳基线方法相比,Recformer在NDCG@10指标上平均提升了15.83%,在MRR指标上平均提升了15.99%。此外,Recformer在零样本推荐任务中也表现出色,进一步证明了其泛化能力。
四、总结
两篇文章都致力于通过大语言模型(LLMs)提高序列推荐的性能,但采用了不同的方法和技术。SAID通过显式学习语义对齐的项目ID嵌入,解决了现有方法在处理长令牌序列时的效率问题。Recformer通过将项目及其属性转换为文本表示,使用双向Transformer编码器进行建模,解决了冷启动问题和跨数据集泛化问题。这两篇文章都为序列推荐领域提供了新的解决方案,具有重要的理论和实践意义。