[IEEE TPAMI 2021]卷积原型网络在开放集识别中的应用

一、研究背景
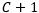 类分类问题,其中
类分类问题,其中
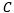 为已知类个数,而所有未知样本均被视为额外的1类。开放集识别更贴近实际应用要求,例如在自动驾驶中,未知的物体和场景会不断出现;在医学图像分析中,未知的疾病类型也会不断出现。
为已知类个数,而所有未知样本均被视为额外的1类。开放集识别更贴近实际应用要求,例如在自动驾驶中,未知的物体和场景会不断出现;在医学图像分析中,未知的疾病类型也会不断出现。
相较于广阔的未知世界,人们所收集标注的训练样本仅能覆盖实际中有限的少数类别。利用有限的训练数据,大多模式识别方法很难在未知样本上具备可信的泛化能力。在CNN中,其SoftMax操作输出的后验概率常被用于检测输入样本是否为未知样本。然而,实验表明,即便对差异很大的未知样本,CNN仍以较大置信度将其错误地分到已知类别中。CNN出现这样错误主要归结于两大原因。一方面,CNN中SoftMax操作将样本属于已知类的后验概率归一化为1,而未给未知类预留一定的概率,故根据其输出的类后验概率很容易将未知样本错分为已知样本。另一方面,CNN为纯判别模型,其本质上对整个特征空间进行了划分并将所有的特征区域分配给了已知类,而未给未知类预留一定的特征空间,这也使得它难以处理未知样本。相对于判别模型,生成模型显式地刻画了已知类的特征分布。若一个样本特征在已知类分布下似然较低,则可将其判为未知样本。故生成模型更适用于检测未知样本。然而,生成模型对已知类样本的分类精度通常较差。在开放集识别任务中,将生成模型和判别模型结合是一重要趋势。
类的分类器[2]。该方法较为直接,但收集或生成大量未知样本往往需要耗费大量的标注或计算代价。此外,增加的有限未知样本也很难体现真实而多变的未知世界。基于统计模型的方法对已知类特征或Logits进行统计建模,利用样本在模型下的似然度来判断样本是否为未知样本[3]。这类方法有很好的理论分析,且有不错的性能表现,是目前一类主流的开放集识别方法。但是,这类方法本质上是一种后处理的方式,在模型训练阶段并未将开放集识别任务考虑进去,而仍像传统闭集分类任务那样来训练模型。基于网络结构的方法通过利用特殊的网络结构,如Auto-encoder,Ladder Net,One-vs-rest层等来训练模型[4]。这类方法通常效果很好,但特殊的结构也限制了其在不同场景中的应用。在开放集识别任务中,大多数方法在性能、通用性、效率等方面仍与应用需求存在较大差距。
二、方法介绍
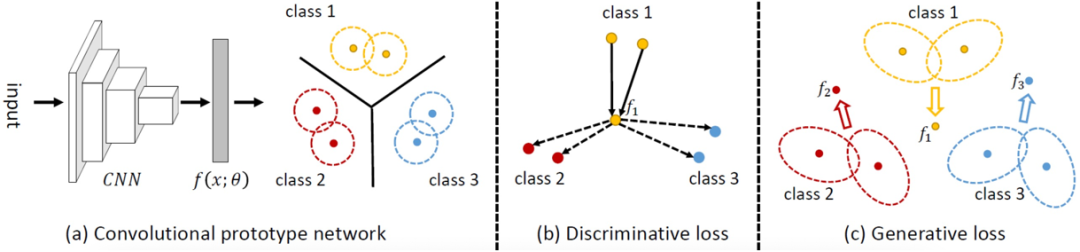
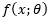 与各类的原型
与各类的原型
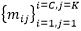 。其中
。其中
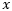 表示原始输入,
表示原始输入,
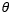 为CNN特征提取器的参数。为已知类个数,对每个类别
为CNN特征提取器的参数。为已知类个数,对每个类别
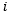 ,都学习和维护
,都学习和维护
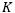 个原型模拟人类对该类的记忆。在判别阶段,CPN采取最近原型准则,通过特征和原型的距离匹配进行判别,即
个原型模拟人类对该类的记忆。在判别阶段,CPN采取最近原型准则,通过特征和原型的距离匹配进行判别,即
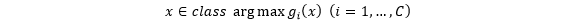
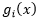 定义为
定义为
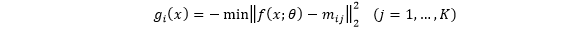 类的判别函数,也表示特征与类别的匹配分数。
类的判别函数,也表示特征与类别的匹配分数。
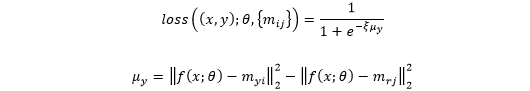
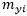 和
和
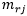 分别表示最近的正确类原型和最近的非正确类(竞争类)原型。从上述定义中可看出,当最小化MCE时,会减小特征到正确类原型的距离,而增加了特征到非正确类的原型的距离。
分别表示最近的正确类原型和最近的非正确类(竞争类)原型。从上述定义中可看出,当最小化MCE时,会减小特征到正确类原型的距离,而增加了特征到非正确类的原型的距离。
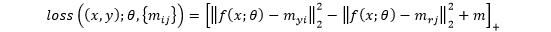 和分别表示最近的正确类原型和最近的非正确类(竞争类)原型,
和分别表示最近的正确类原型和最近的非正确类(竞争类)原型,
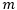 为设置的Margin参数。
为设置的Margin参数。
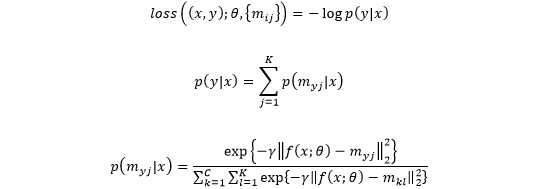
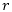 为半径构建原型球。基于此,每个类对应原型球并集即为该类的合法区域。对于训练样本,我们显式地要求其属于正确类的合法区域,同时要求其不属于其他所有非正确类的合法区域,由此导出了对应的OVA损失。经过具体推导后,OVA具体定义为:
为半径构建原型球。基于此,每个类对应原型球并集即为该类的合法区域。对于训练样本,我们显式地要求其属于正确类的合法区域,同时要求其不属于其他所有非正确类的合法区域,由此导出了对应的OVA损失。经过具体推导后,OVA具体定义为:
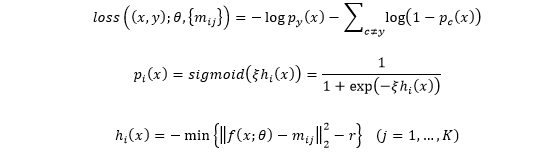 ,假设其类内特征分布为混合高斯分布,且该类原型为对应各高斯成分的均值,且不同类、不同高斯成分都共享同一个协方差矩阵
,假设其类内特征分布为混合高斯分布,且该类原型为对应各高斯成分的均值,且不同类、不同高斯成分都共享同一个协方差矩阵
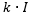 。基于这样的分布,对一个训练样本,可求出其在该分布下的似然度,并利用其负Log似然作为相应的生成损失。经过推导和简化后,生成损失具体定义为:
。基于这样的分布,对一个训练样本,可求出其在该分布下的似然度,并利用其负Log似然作为相应的生成损失。经过推导和简化后,生成损失具体定义为:

从生成损失的定义中可看出,最小化生成损失可压缩类内特征分布。通过与判别损失配合,CPN可学到类内紧致,类间分隔的特征分布。此种分布可预留更大的空间给未知类,故可提高CPN在开放集识别中的可用性。
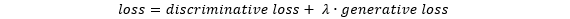
由于判别损失和生成损失对原型和CNN参数均可导,故基于这样的损失可对CNN特征提取器和原型进行端到端的训练。
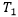 ,同时计算样本特征到所有原型的距离,若:
,同时计算样本特征到所有原型的距离,若:
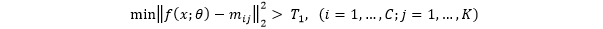
在PR中,给定阈值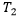
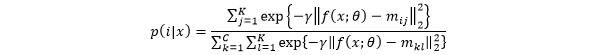
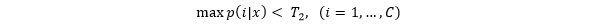
三、实验结果

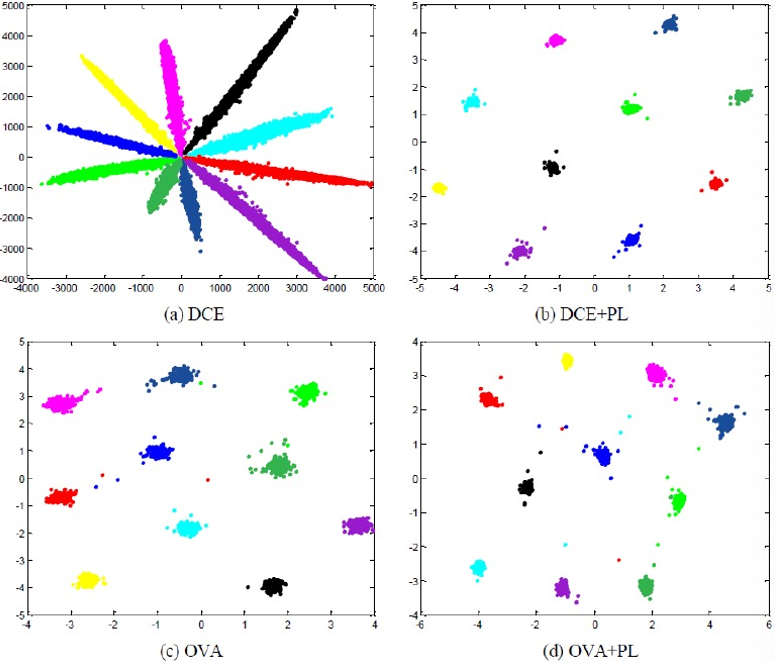
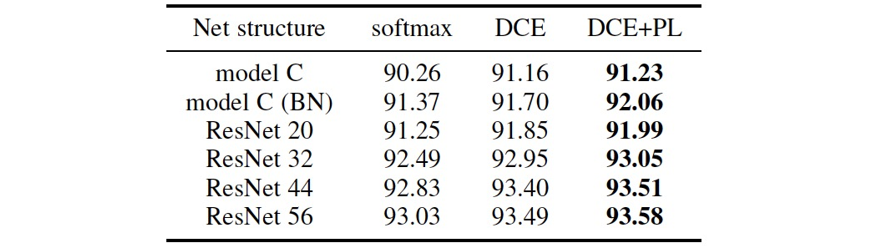
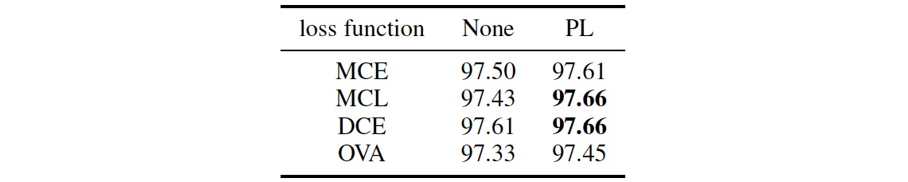
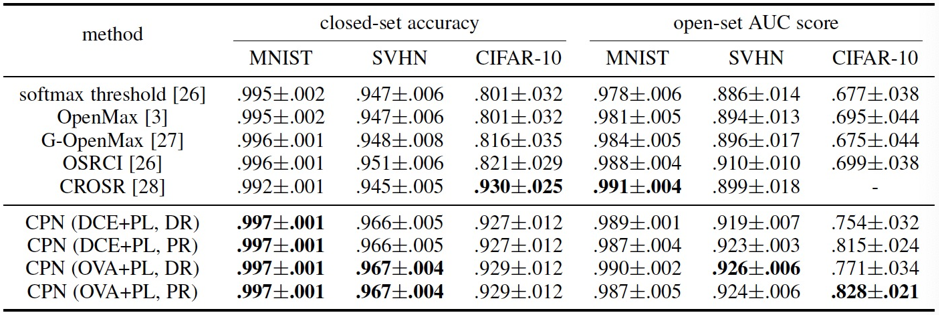
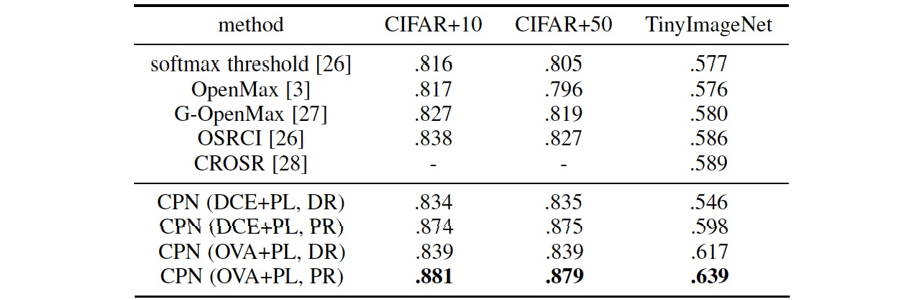
从表4和表5中可看出,相对已有方法,CPN在开放集识别任务中有很大的性能优势。相比已有方法,CPN更加高效,其不需要额外的训练数据,不需要复杂的未知样本判断逻辑,且可进行端到端的训练。
我们进一步在ImageNet上进行实验来考察CPN的开放集识别性能。在ImageNet中,分别采取前100/200类作为已知类,其他类作为未知类,相关实验结果如下表所示:

从表6中结果可看出,即使是在更复杂困难的ImageNet数据集上,我们的方法也具备更好的开放集识别性能。
之前实验中,已知和未知样本均来自同一个数据集,其本身有一定相关性。为进一步考察CPN对噪声的拒识性能,我们在CIFAR-10和ImageNet上进行了实验。我们考虑了两种不同形式的噪声,即高斯噪声(Gaussian Noise,GN)和合成噪声(Synthetic Noise,SN)。在SN中,我们将一幅图片分成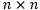

四、论文链接
https://ieeexplore.ieee.org/abstract/document/9296325
[1] W. J. Scheirer, A. Rocha, A. Sapkota, T. E. Boult. Toward open set recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013.
[2] L. Neal, M. Olson, X. Fern, W. Wong, F. Li. Open set learning with counterfactual images. Proceedings of the European Conference on Computer Vision, 2018.
[3] A. Bendale and T. E. Boult. Towards open set deep networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
[4] R. Yoshihashi, W. Shao, R. Kawakami, S. You, M. Iida, T. Naemura. Classification-reconstruction learning for open-set recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019.
[5] B.-H. Juang and S. Katagiri. Discriminative learning for minimum error classification (pattern recognition). IEEE Transactions on Signal Processing, 1992.
审校:殷 飞
发布:金连文
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CPN” 可以获取《[IEEE TPAMI 2021]卷积原型网络在开放集识别中的应用》专知下载链接索引







