

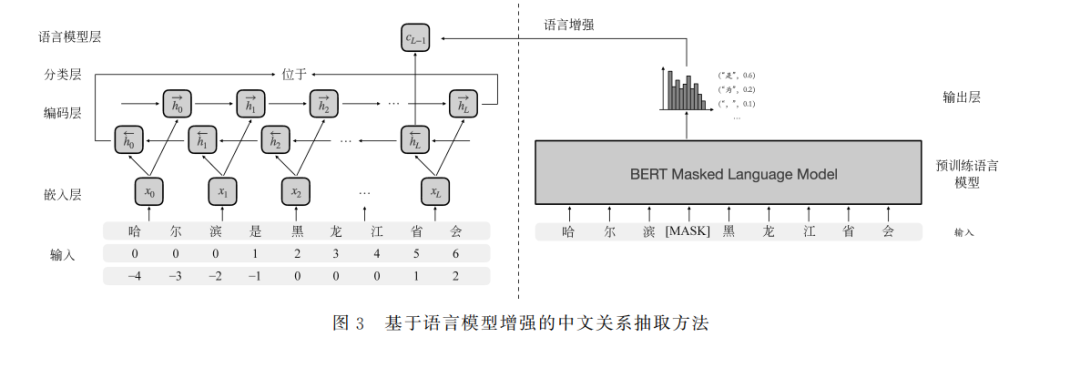
中文关系抽取任务旨在识别中文文本中实体对的语义关系。基于预训练语言模型的方法达到了当前最优 结果。得益于大规模的训练语料,预训练语言模型能够学习到训练语料中的语言知识,提高了中文关系抽取模型 的泛化能力,但其庞大的参数规模需要消耗大量的存储和计算资源。为此,该文提出了基于语言模型增强的中文 关系抽取方法,该方法基于多任务学习范式,促进轻量级的中文关系抽取模型学习预训练语言模型中的语言知识。 该文在三个中文关系抽取数据集上的实验结果表明了基于语言模型增强的中文关系抽取方法的有效性,仅使用预 训练语言模型1%的参数即可达到其95%的性能。
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年10月30日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年10月30日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日