

论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/ * 项目地址:https://github.com/facebookresearch/llama 总的来说,作为一组经过预训练和微调的大语言模型(LLM),Llama 2 模型系列的参数规模从 70 亿到 700 亿不等。其中的 Llama 2-Chat 针对对话用例进行了专门优化。
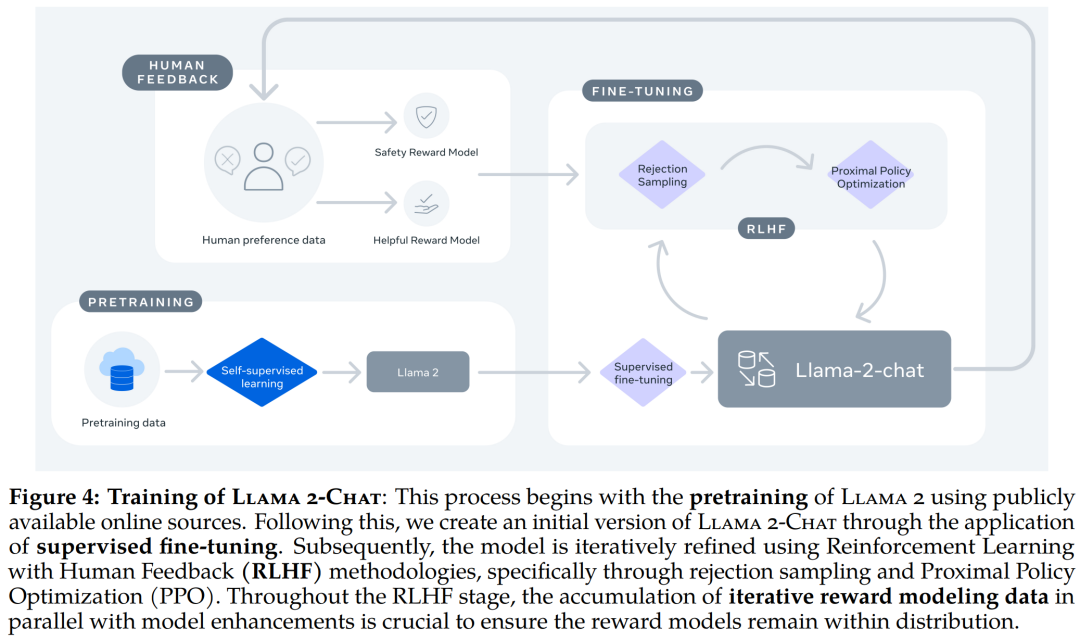
Llama 2-Chat 的训练 pipeline。 Llama 2 模型系列除了在大多数基准测试中优于开源模型之外,根据 Meta 对有用性和安全性的人工评估,它或许也是闭源模型的合适替代品。
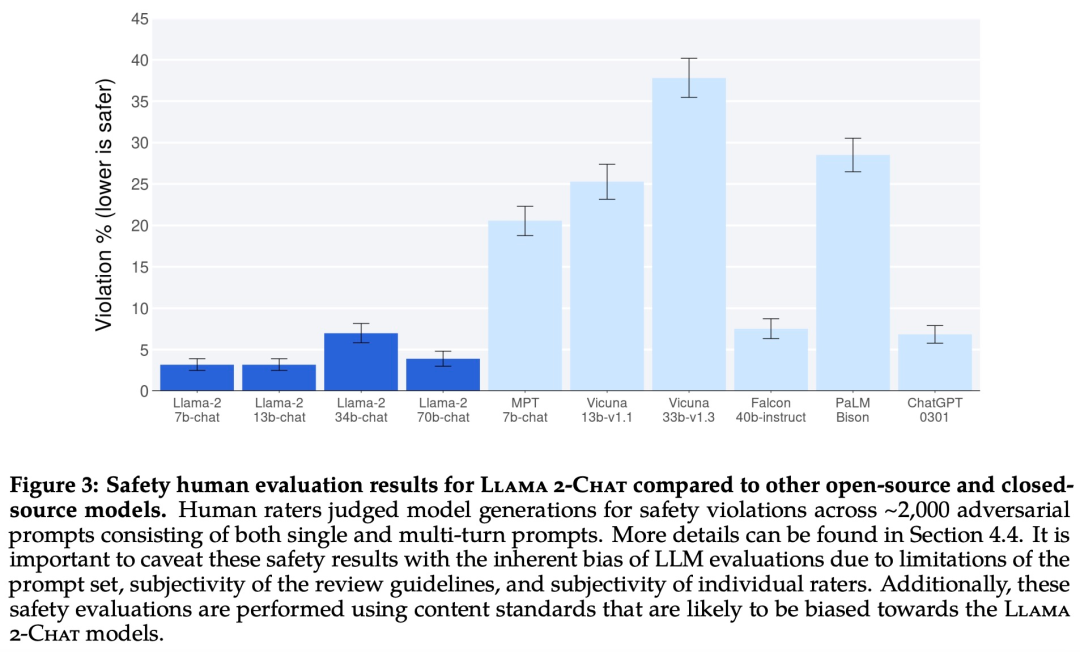
Llama 2-Chat 与其他开源和闭源模型在安全性人类评估上的结果。 Meta 详细介绍了 Llama 2-Chat 的微调和安全改进方法,使社区可以在其工作基础上继续发展,为大语言模型的负责任发展做出贡献。 Vedanuj 目前在 Meta AI 的 LLM 研究团队担任研究工程师,他主要关注 LLM 的预训练和扩展技术。他最近参与了训练“Llama 2”系列模型,这迅速成为了社区中最广泛采纳和下载的开放模型之一。在此之前,Vedanuj 是“不遗余力的语言翻译”和“为未书写的语言提供普遍的语音翻译”项目的研究负责人。在深入研究 LLM 和翻译之前,他在 FAIR 从事多模态研究,领导了如 FLAVA 和 MMF 这样的知名项目。



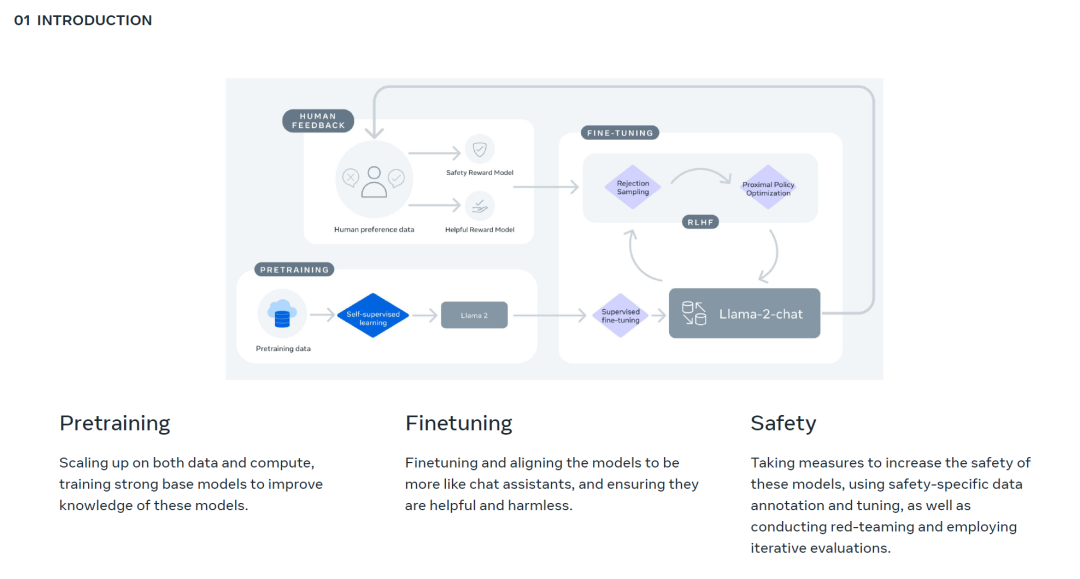

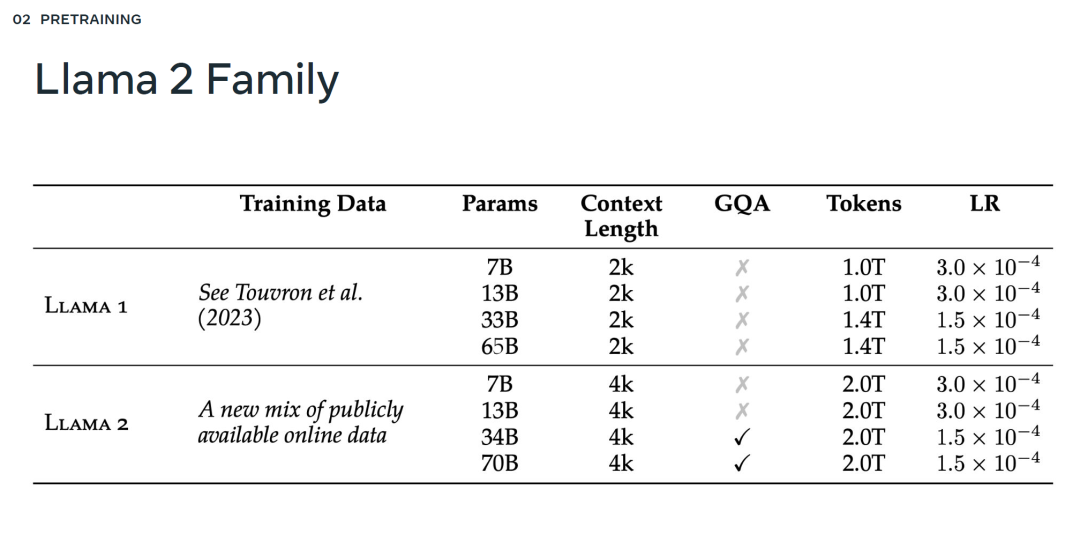
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2023年12月7日
Arxiv
0+阅读 · 2023年12月6日
Arxiv
0+阅读 · 2023年12月3日
Arxiv
0+阅读 · 2023年12月1日
Arxiv
24+阅读 · 2021年9月20日
相关VIP内容
相关资讯