
转载:机器之心

论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/ * 项目地址:https://github.com/facebookresearch/llama
总的来说,作为一组经过预训练和微调的大语言模型(LLM),Llama 2 模型系列的参数规模从 70 亿到 700 亿不等。其中的 Llama 2-Chat 针对对话用例进行了专门优化。
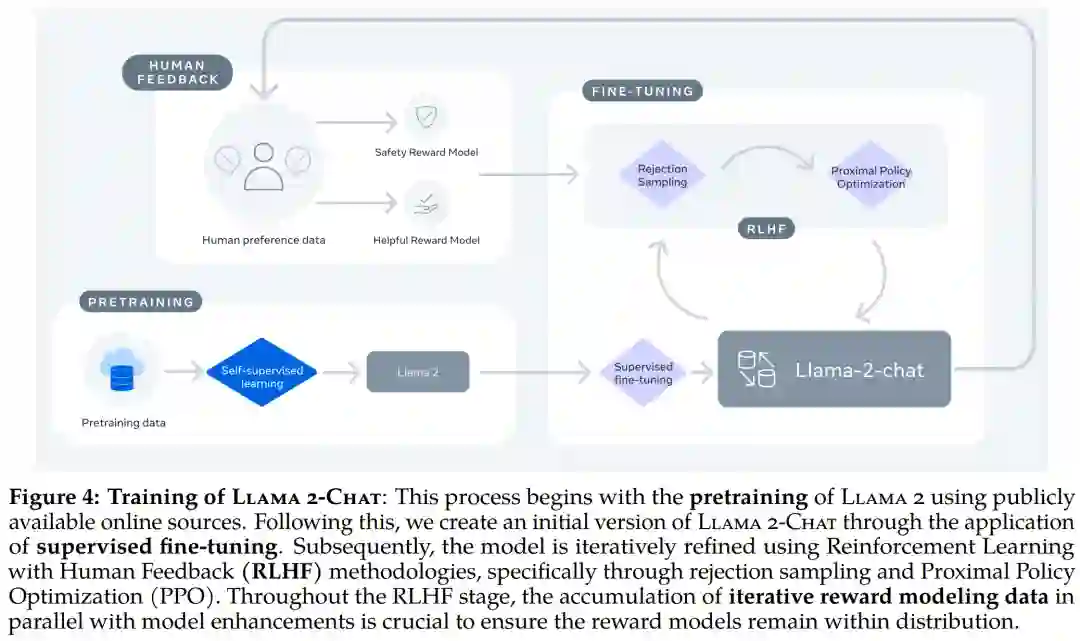
Llama 2-Chat 的训练 pipeline。
Llama 2 模型系列除了在大多数基准测试中优于开源模型之外,根据 Meta 对有用性和安全性的人工评估,它或许也是闭源模型的合适替代品。
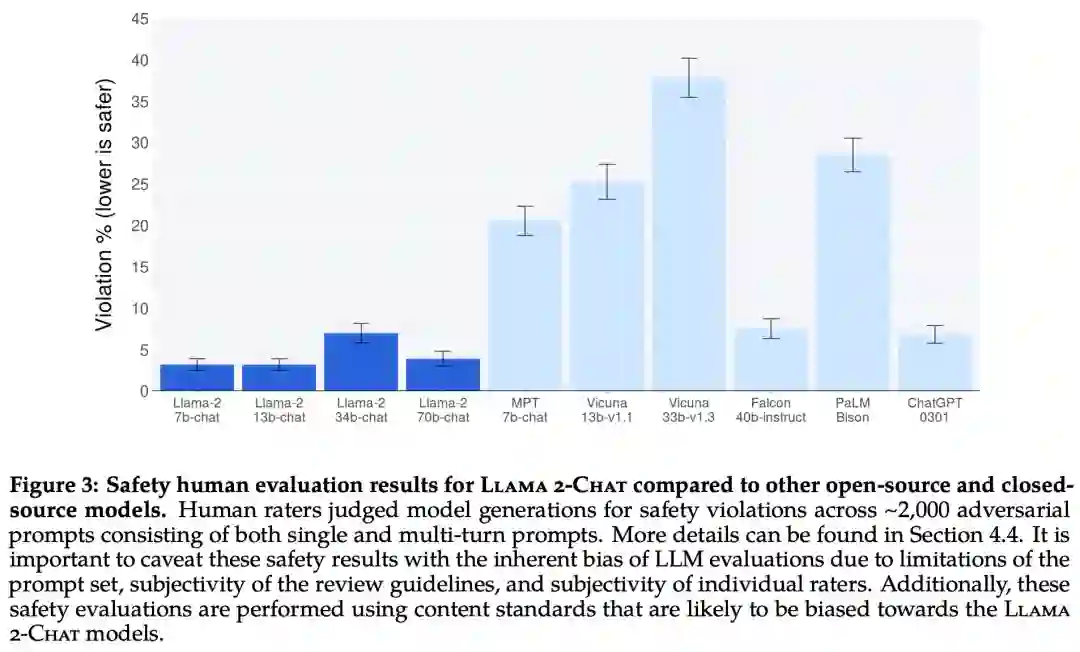
Llama 2-Chat 与其他开源和闭源模型在安全性人类评估上的结果。
Meta 详细介绍了 Llama 2-Chat 的微调和安全改进方法,使社区可以在其工作基础上继续发展,为大语言模型的负责任发展做出贡献。
预训练
为了创建全新的 Llama 2 模型系列,Meta 以 Llama 1 论文中描述的预训练方法为基础,使用了优化的自回归 transformer,并做了一些改变以提升性能。
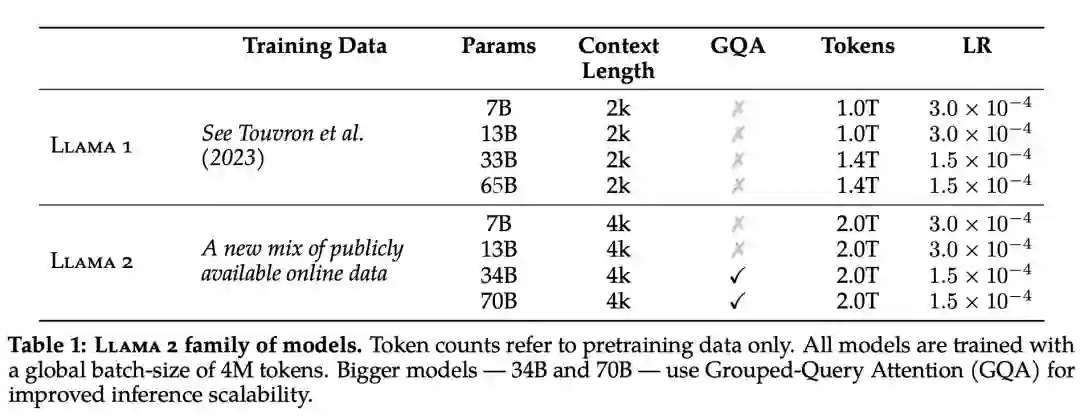
具体而言,Meta 执行了更稳健的数据清理,更新了混合数据,训练 token 总数增加了 40%,上下文长度翻倍。下表 1 比较了 Llama 2 与 Llama 1 的详细数据。
Llama 2 的训练语料库包含了来自公开可用资源的混合数据,并且不包括 Meta 产品或服务相关的数据。Llama 2 采用了 Llama 1 中的大部分预训练设置和模型架构,包括标准 Transformer 架构、使用 RMSNorm 的预归一化、SwiGLU 激活函数和旋转位置嵌入。
在超参数方面,Meta 使用 AdamW 优化器进行训练,其中 β_1 = 0.9,β_2 = 0.95,eps = 10^−5。同时使用余弦学习率计划(预热 2000 步),并将最终学习率衰减到了峰值学习率的 10%。
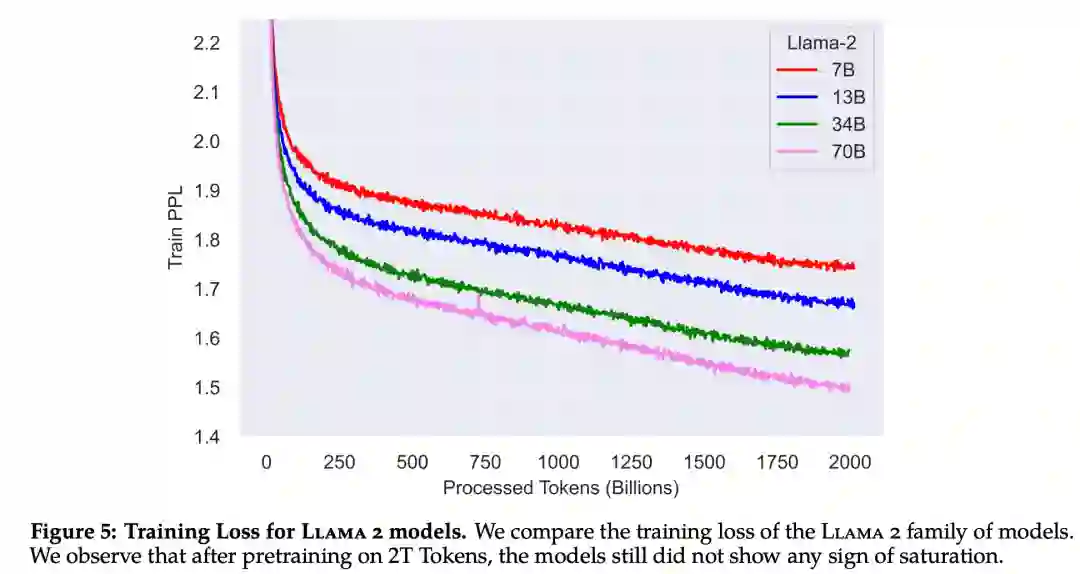
下图 5 为这些超参数设置下 Llama 2 的训练损失曲线。
在训练硬件方面,Meta 在其研究超级集群(Research Super Cluster, RSC)以及内部生产集群上对模型进行了预训练。两个集群均使用了 NVIDIA A100。
在预训练的碳足迹方面,Meta 根据以往的研究方法,利用 GPU 设备的功耗估算和碳效率,计算了 Llama 2 模型预训练所产生的碳排放量。
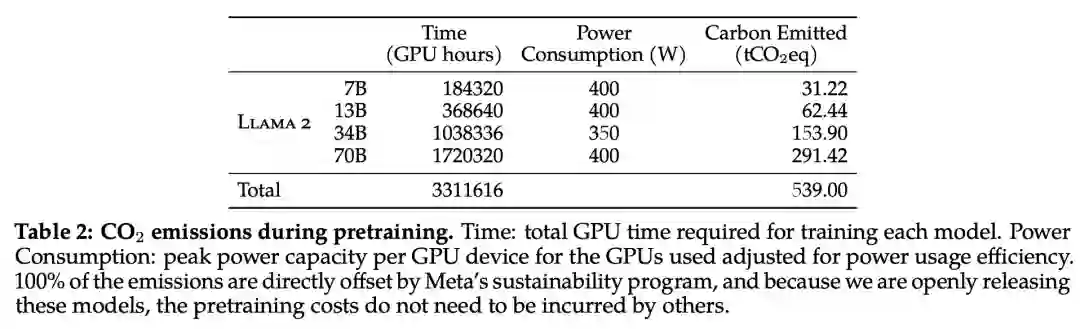
预训练期间 Llama 2 各个模型的碳排放量。
Llama 2 预训练模型评估
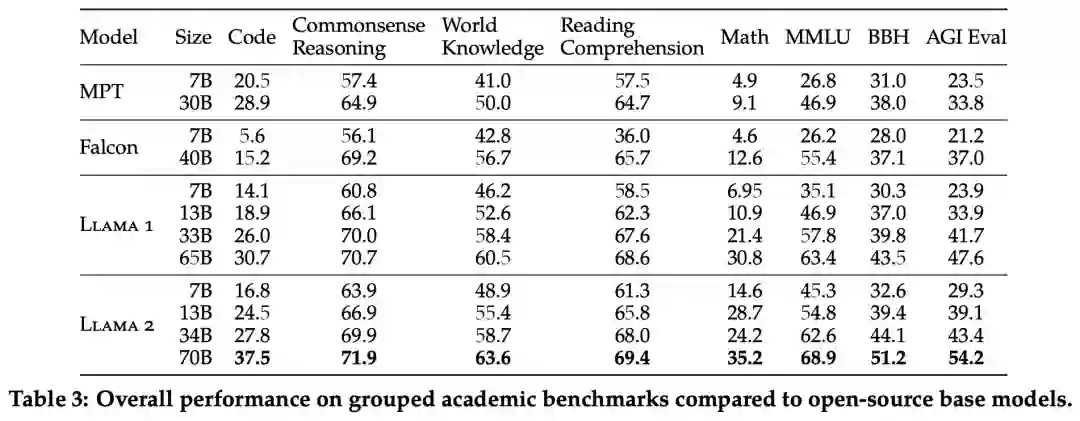
Meta 报告了 Llama 1、Llama 2 基础模型、MPT(MosaicML)和 Falcon 等开源模型在标准学术基准上的结果。
下表 3 总结了这些模型在一系列流行基准上的整体性能,结果表明,Llama 2 优于 Llama 1 。
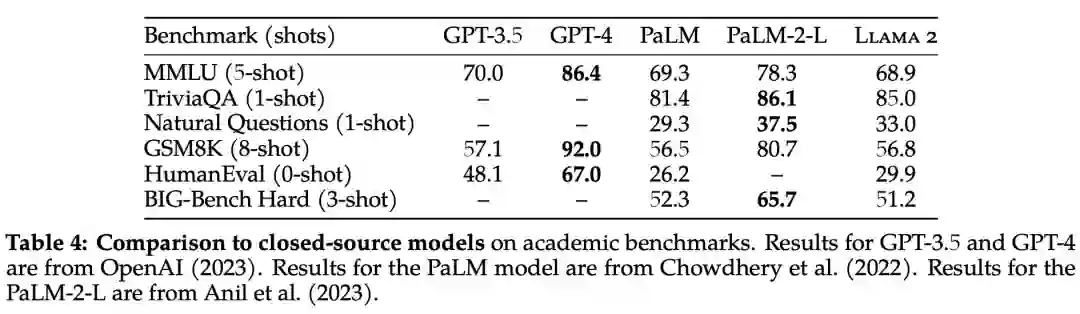
除了开源模型之外,Meta 还将 Llama 2 70B 的结果与闭源模型进行了比较,结果如下表 4 所示。Llama 2 70B 在 MMLU 和 GSM8K 上接近 GPT-3.5,但在编码基准上存在显著差距。
此外,在几乎所有基准上,Llama 2 70B 的结果均与谷歌 PaLM (540B) 持平或表现更好,不过与 GPT-4 和 PaLM-2-L 的性能仍存在较大差距。
微调
**
**
Llama 2-Chat 是数个月研究和迭代应用对齐技术(包括指令调整和 RLHF)的成果,需要大量的计算和注释资源。
监督微调 (SFT)
第三方监督微调数据可从许多不同来源获得,但 Meta 发现其中许多数据的多样性和质量都不够高,尤其是在使 LLM 与对话式指令保持一致方面。因此,他们首先重点收集了几千个高质量 SFT 数据示例,如下表 5 所示。

在微调过程中,每个样本都包括一个提示和一个回答。为确保模型序列长度得到正确填充,Meta 将训练集中的所有提示和答案连接起来。他们使用一个特殊的 token 来分隔提示和答案片段,利用自回归目标,将来自用户提示的 token 损失归零,因此只对答案 token 进行反向传播。最后对模型进行了 2 次微调。
RLHF
RLHF 是一种模型训练程序,适用于经过微调的语言模型,以进一步使模型行为与人类偏好和指令遵循相一致。Meta 收集了代表了人类偏好经验采样的数据,人类注释者可据此选择他们更喜欢的两种模型输出。这种人类反馈随后被用于训练奖励模型,该模型可学习人类注释者的偏好模式,然后自动做出偏好决定。
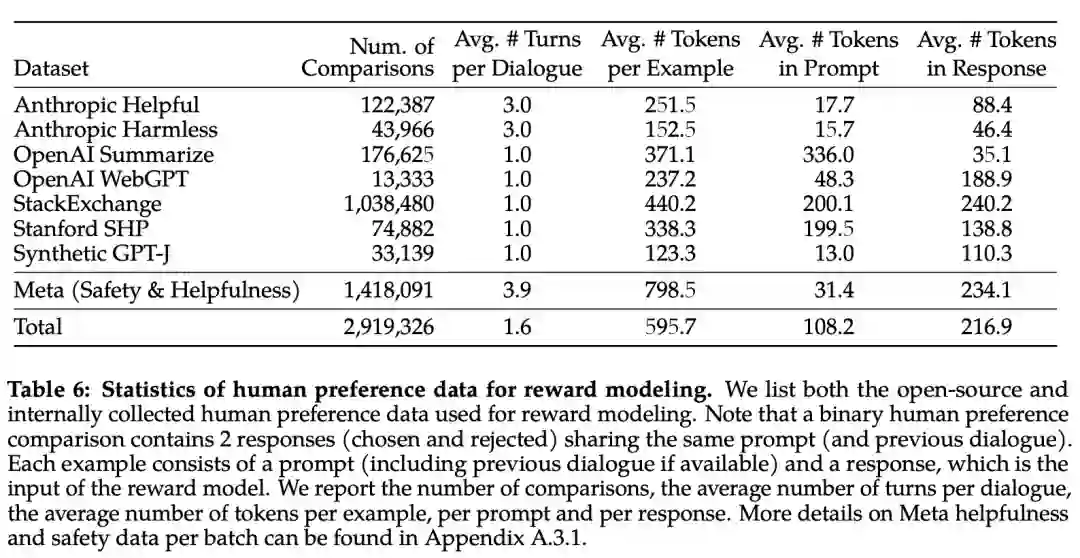
下表 6 报告了 Meta 长期以来收集到的奖励建模数据的统计结果,并将其与多个开源偏好数据集进行了对比。他们收集了超过 100 万个基于人类应用指定准则的二元比较的大型数据集,也就是元奖赏建模数据。
请注意,提示和答案中的标记数因文本领域而异。摘要和在线论坛数据的提示通常较长,而对话式的提示通常较短。与现有的开源数据集相比,本文的偏好数据具有更多的对话回合,平均长度也更长。
奖励模型将模型响应及其相应的提示(包括前一轮的上下文)作为输入,并输出一个标量分数来表示模型生成的质量(例如有用性和安全性)。利用这种作为奖励的响应得分,Meta 在 RLHF 期间优化了 Llama 2-Chat,以更好地与人类偏好保持一致,并提高有用性和安全性。
在每一批用于奖励建模的人类偏好注释中,Meta 都拿出 1000 个样本作为测试集来评估模型,并将相应测试集的所有提示的集合分别称为「元有用性」和「元安全性」。
下表 7 中报告了准确率结果。不出所料,Meta 自己的奖励模型在基于 Llama 2-Chat 收集的内部测试集上表现最佳,其中「有用性」奖励模型在「元有用性」测试集上表现最佳,同样,「安全性」奖励模型在「元安全性」测试集上表现最佳。
总体而言,Meta 的奖励模型优于包括 GPT-4 在内的所有基线模型。有趣的是,尽管 GPT-4 没有经过直接训练,也没有专门针对这一奖励建模任务,但它的表现却优于其他非元奖励模型。
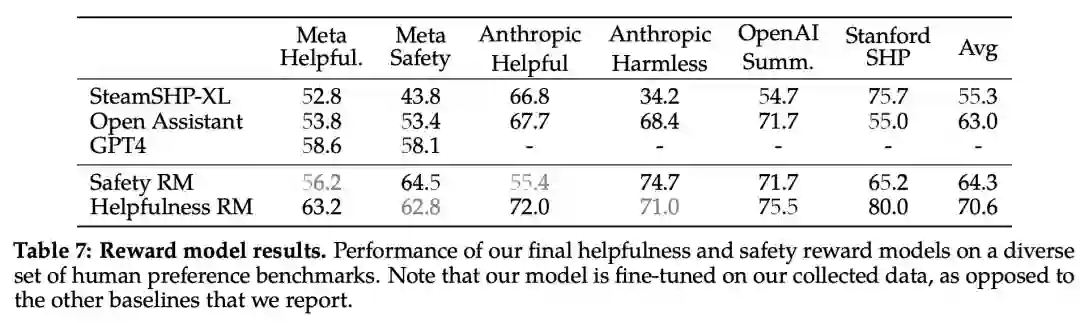
缩放趋势。Meta 研究了奖励模型在数据和模型大小方面的缩放趋势,在每周收集的奖励模型数据量不断增加的情况下,对不同的模型大小进行了微调。下图 6 报告了这些趋势,显示了预期的结果,即在类似的数据量下,更大的模型能获得更高的性能。
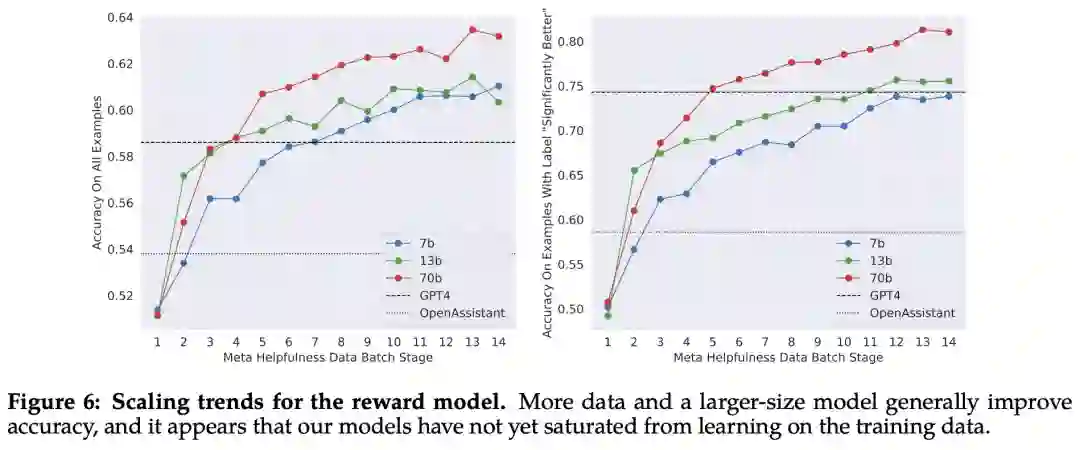
随着收到更多批次的人类偏好数据注释,能够训练出更好的奖励模型并收集更多的提示。因此,Meta 训练了连续版本的 RLHF 模型,在此称为 RLHF-V1、...... , RLHF-V5。
此处使用两种主要算法对 RLHF 进行了微调:
近端策略优化 (PPO); * Rejection 采样微调。
RLHF 结果
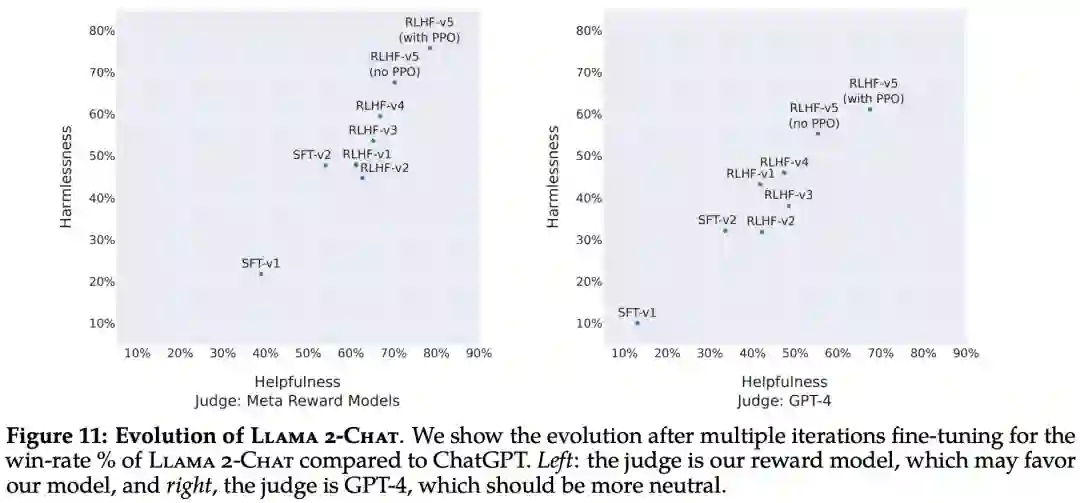
首先是基于模型的评估结果。下图 11 报告了不同 SFT 和 RLHF 版本在安全性和有用性方面的进展,其中通过 Meta 内部的安全性和有用性奖励模型进行评估。
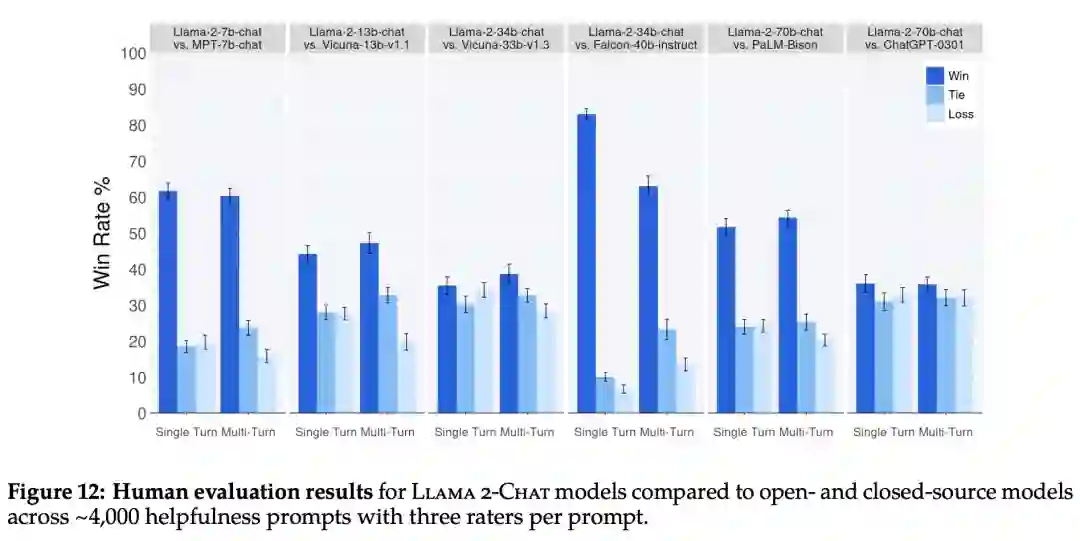
再来看人类评估结果。如下图 12 所示,Llama 2-Chat 模型在单轮和多轮提示方面均显著优于开源模型。特别地,Llama 2-Chat 7B 在 60% 的提示上优于 MPT-7B-chat,Llama 2-Chat 34B 相对于同等大小的 Vicuna-33B 和 Falcon 40B,表现出了 75% 以上的整体胜率。
在这里,Meta 也指出了人工评估的一些局限性。
虽然结果表明 Llama 2-Chat 在人工评估方面与 ChatGPT 不相上下,但必须指出的是,人工评估存在一些局限性。
按照学术和研究标准,本文拥有一个 4k 提示的大型提示集。但是,这并不包括这些模型在现实世界中的使用情况,而现实世界中的使用情况可能要多得多。 * 提示语的多样性可能是影响结果的另一个因素,例如本文提示集不包括任何编码或推理相关的提示。 * 本文只评估了多轮对话的最终生成。更有趣的评估方法可能是要求模型完成一项任务,并对模型在多轮对话中的整体体验进行评分。 * 人类对生成模型的评估本身就具有主观性和噪声性。因此,使用不同的提示集或不同的指令进行评估可能会产生不同的结果。
安全性
该研究使用三个常用基准评估了 Llama 2 的安全性,针对三个关键维度:
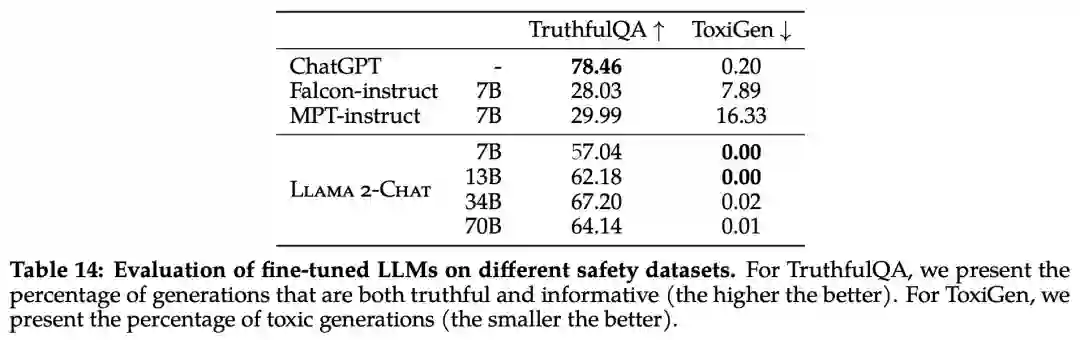
真实性,指语言模型是否会产生错误信息,采用 TruthfulQA 基准; * 毒性,指语言模型是否会产生「有毒」、粗鲁、有害的内容,采用 ToxiGen 基准; * 偏见,指语言模型是否会产生存在偏见的内容,采用 BOLD 基准。
预训练的安全性
首先,预训练数据对模型来说非常重要。Meta 进行实验评估了预训练数据的安全性。
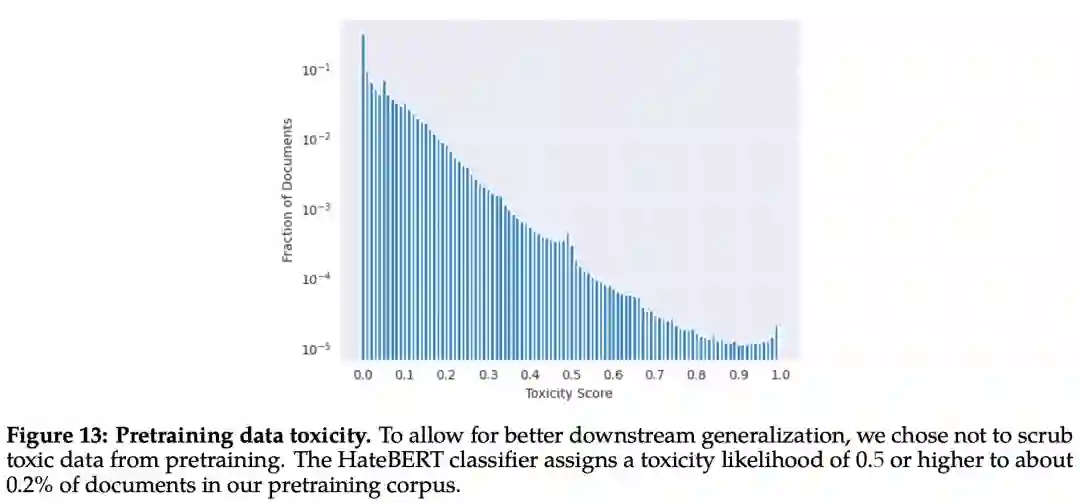
该研究使用在 ToxiGen 数据集上微调的 HateBERT 分类器来测量预训练语料库英文数据的「毒性」,具体结果如下图 13 所示:
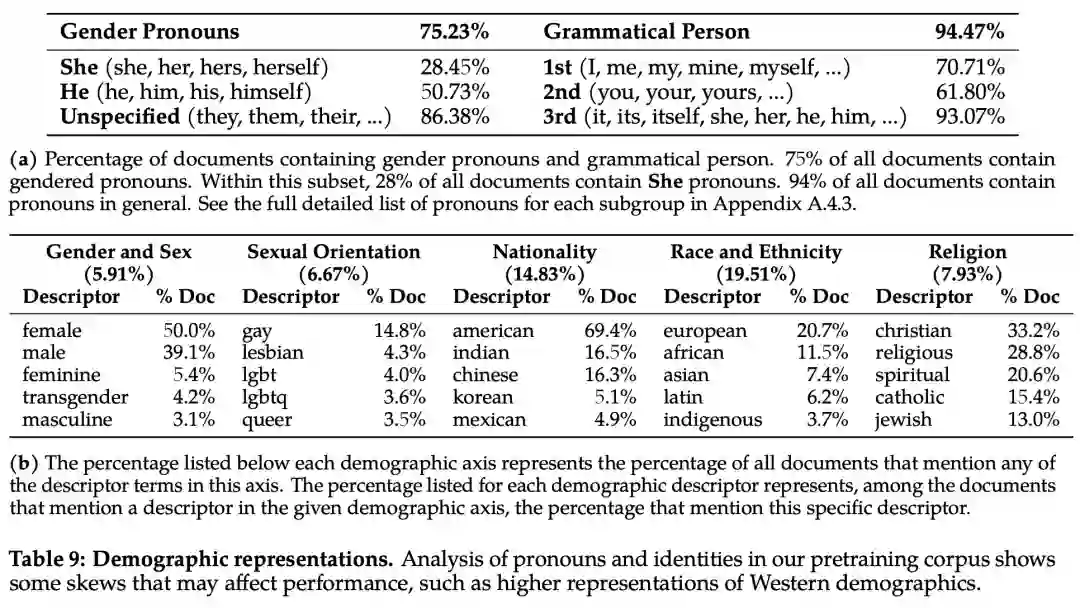
为了分析偏见方面的问题,该研究统计分析了预训练语料库中的代词和身份相关术语及其占比,如下表 9 所示:
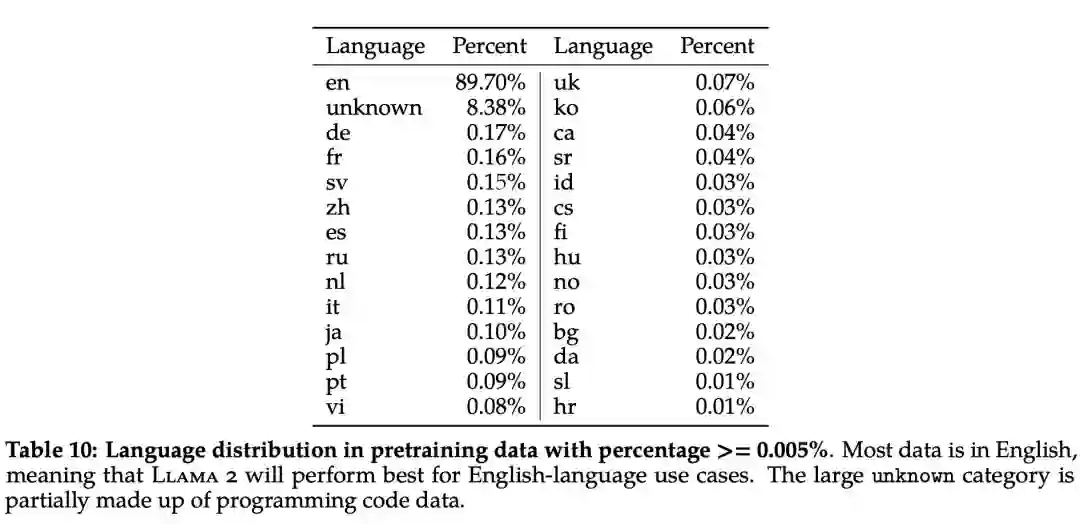
此外,在语言分布方面,Llama 2 语料库涵盖的语种及其占比如下表 10 所示:
安全微调
具体来说,Meta 在安全微调中使用了以下技术:1、监督安全微调;2、安全 RLHF;3、安全上下文蒸馏。
Meta 在 Llama 2-Chat 的开发初期就观察到,它能够在有监督的微调过程中从安全演示中有所总结。模型很快就学会了撰写详细的安全回复、解决安全问题、解释话题可能敏感的原因并提供更多有用信息。特别是,当模型输出安全回复时,它们往往比普通注释者写得更详细。因此,在只收集了几千个有监督的示范后,Meta 就完全改用 RLHF 来教模型如何写出更细致入微的回复。使用 RLHF 进行全面调整的另一个好处是,它可以使模型对越狱尝试更加鲁棒。
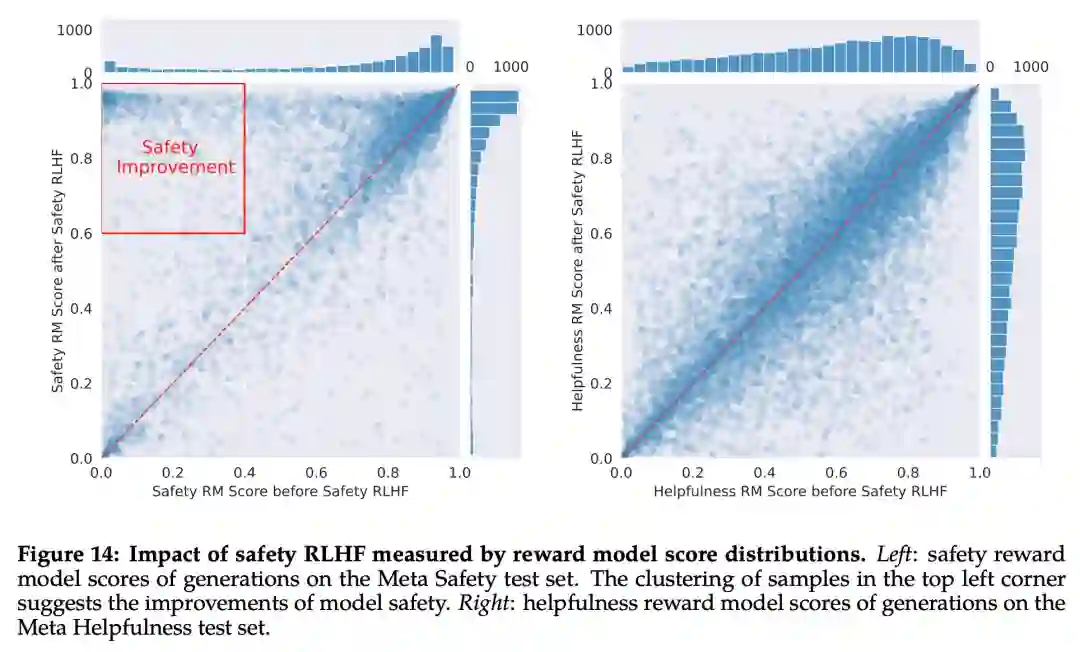
Meta 首先通过收集人类对安全性的偏好数据来进行 RLHF,其中注释者编写他们认为会引发不安全行为的 prompt,然后将多个模型响应与 prompt 进行比较,并根据一系列指南选择最安全的响应。接着使用人类偏好数据来训练安全奖励模型,并在 RLHF 阶段重用对抗性 prompt 以从模型中进行采样。
如下图 15 所示,Meta 使用平均奖励模型得分作为模型在安全性和有用性方面的表现结果。Meta 观察到,当他们增加安全数据的比例时,模型处理风险和对抗性 prompt 的性能显著提高。
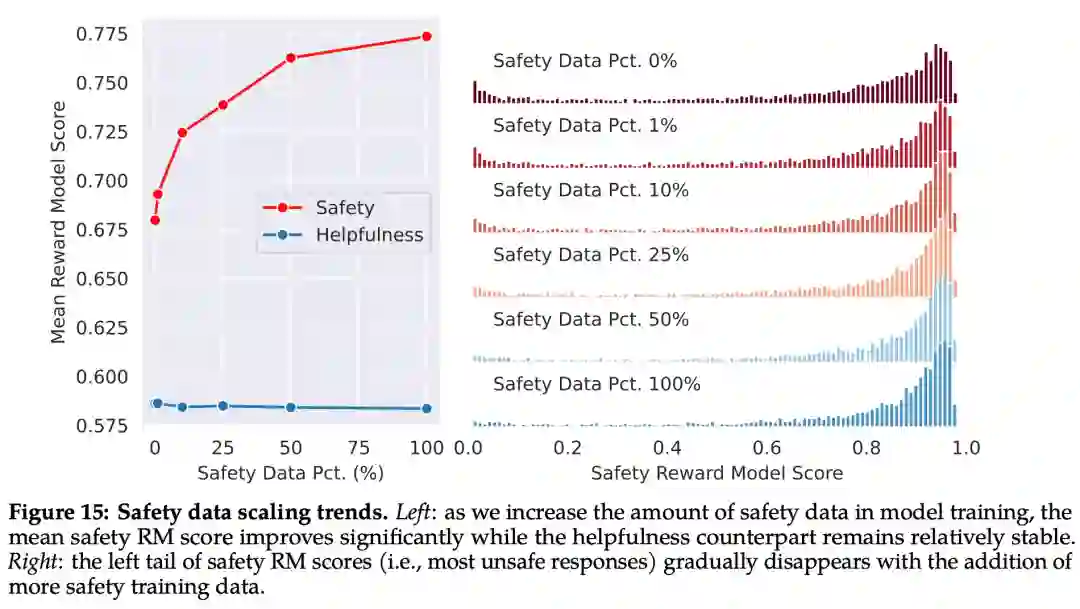
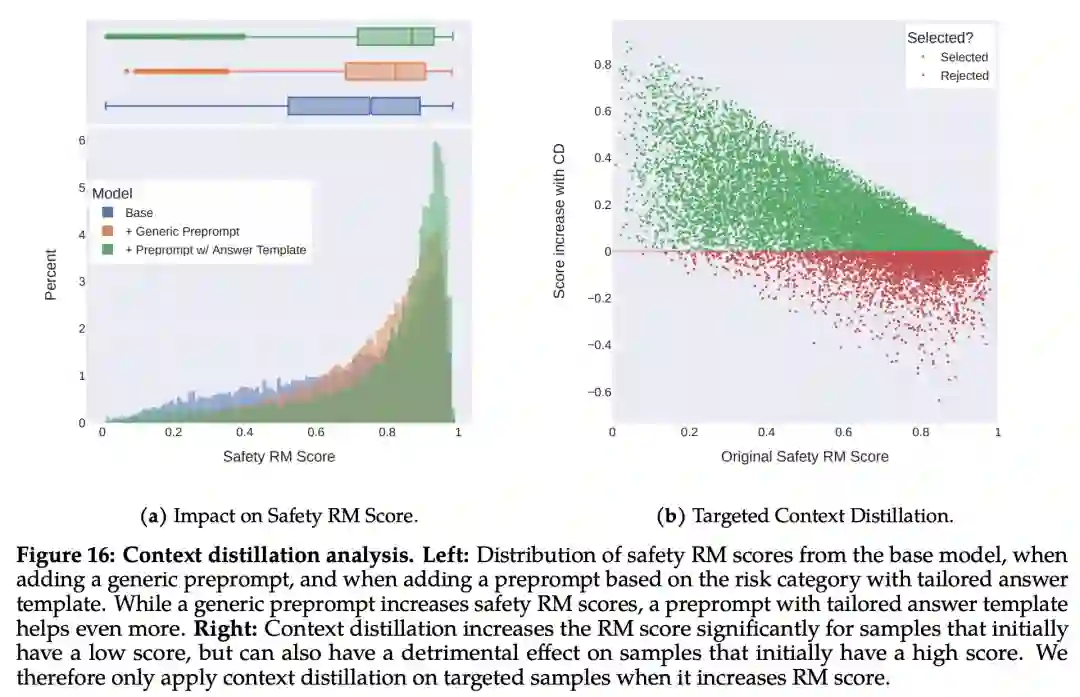
最后,Meta 通过上下文蒸馏完善了 RLHF 流程。这涉及到通过在 prompt 前加上安全前置 prompt 来生成更安全的模型响应,例如「你是一个安全且负责任的助手」,然后在没有前置 prompt 的情况下根据更安全的响应微调模型,这本质上是提取了安全前置 prompt(上下文)进入模型。
Meta 使用了有针对性的方法,允许安全奖励模型选择是否对每个样本使用上下文蒸馏。
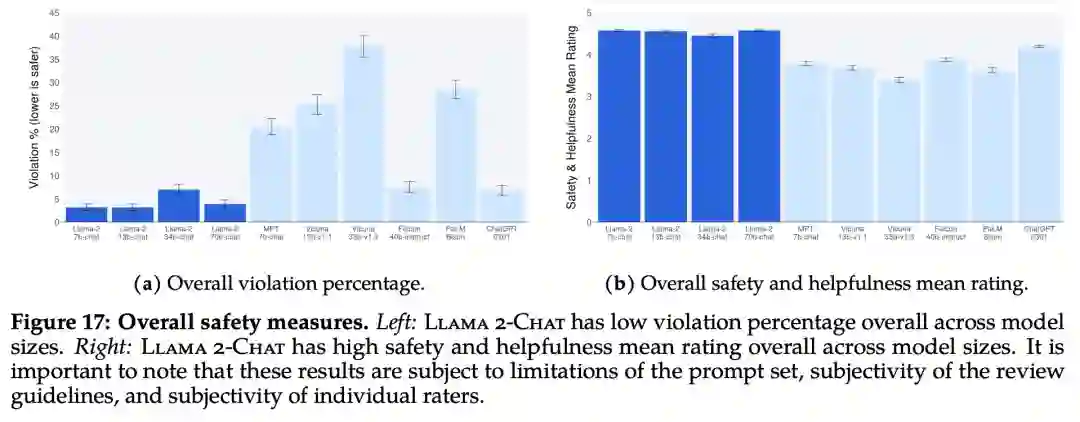
下图 17 展示了各种 LLM 的总体违规百分比和安全评级。
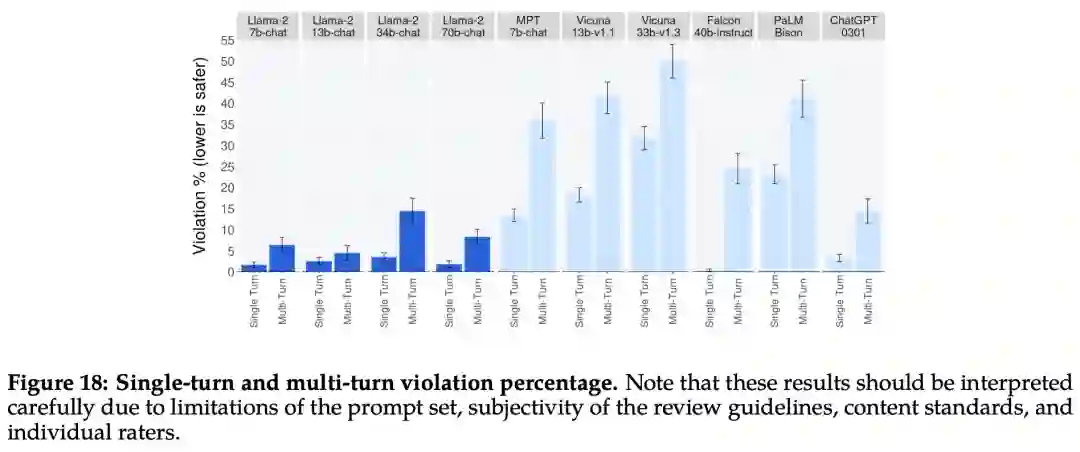
下图 18 展示了单轮和多轮对话的违规百分比。跨模型的一个趋势是,多轮对话更容易引发不安全的响应。也就是说,与基线相比,Llama 2-Chat 仍然表现良好,尤其是在多轮对话中。
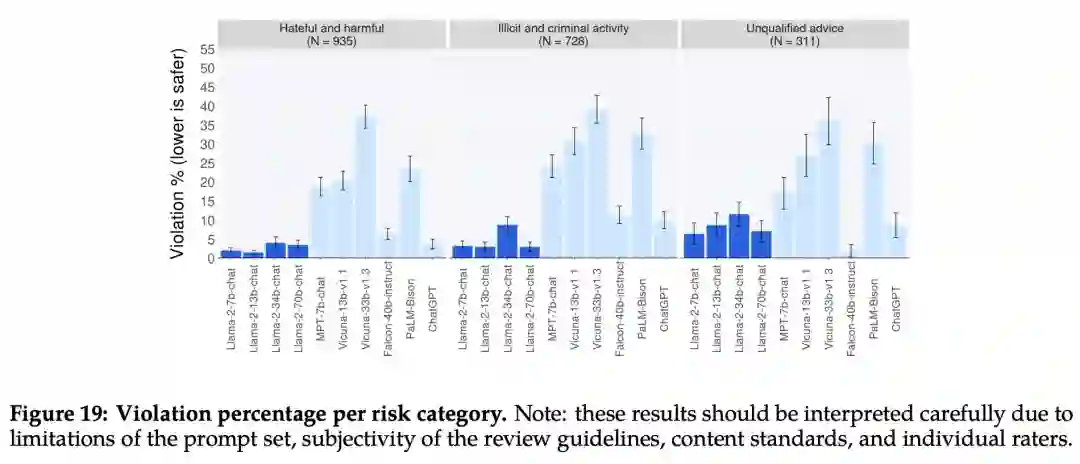
下图 19 显示了不同 LLM 在不同类别中安全违规百分比。
参考链接:https://ai.meta.com/llama/


