

大规模语言模型(LLM)在多个领域具有变革性的潜力,包括推荐系统(RS)。已有一些研究专注于通过LLM赋能推荐系统。然而,之前的工作主要集中于将LLM作为推荐系统,这可能面临LLM推理成本过高的问题。最近,LLM与推荐系统的结合——即LLM增强推荐系统(LLMERS)——因其在实际应用中解决延迟和内存限制的潜力,受到了广泛关注。本文对最新的研究工作进行了全面的综述,旨在利用LLM提升推荐系统的能力。我们发现,随着LLM被引入在线系统,特别是通过避免在推理阶段使用LLM,领域内出现了一个关键的转变。我们的综述将现有的LLMERS方法按推荐系统模型增强的组件分为三种主要类型:知识增强、交互增强和模型增强。我们深入分析了每个类别,讨论了相关方法、挑战以及近期研究的贡献。此外,我们还指出了几个有前景的研究方向,这些方向可能进一步推动LLMERS领域的发展。
1 引言
大规模语言模型(LLM)在语言理解和推理方面展现了前所未有的能力 [3, 69, 87]。考虑到传统推荐系统(RS)仅利用协同信号 [2, 65, 66],通过LLM为推荐系统提供语义信息显得尤为有吸引力。因此,许多研究提出了弥合自然语言与推荐之间差距的方法,从而打造更强大的推荐系统。尽管将LLM应用于推荐系统取得了一定的成功,但对话系统与推荐系统之间的一个显著区别在于推理延迟。推荐系统通常要求对大量请求提供低延迟响应,而LLM(例如LLaMA-7B)在响应时间上通常需要几秒钟。然而,许多早期的研究主要集中在直接使用LLM进行推荐 [13],这使得它们难以满足实际应用的需求。最近,越来越多的研究者开始关注这一问题,并深入探索LLM增强推荐系统的实践应用。因此,本文旨在总结和概述该领域的最新研究成果。为了明确本综述的范围,我们首先给出LLMERS的定义:传统推荐系统通过LLM的辅助来增强训练或补充数据,但在服务过程中无需使用LLM进行推理。尽管已有一些关于LLM在推荐系统中应用的综述,但存在三点关键差异: i) 目前的大多数综述集中在如何将LLM本身作为更好的推荐系统,包括生成推荐 [28, 31, 70] 和判别推荐 [4, 6, 20, 33, 56, 89]。相比之下,我们的综述专门探讨LLM增强推荐系统(LLMERS)。 ii) LLM在推荐系统中的应用是一个前沿方向,发展迅速。一些综述 [4, 33, 70, 89] 并未涵盖最新的论文。相比之下,本综述包含了超过50篇2024年后发布的工作。 iii) 很少有综述提及LLM增强推荐系统 [4, 33],但它们仅关注特征工程方面的增强。而本综述则首次从综合视角总结了LLMERS,包括特征和模型两个方面。
1.1 初步介绍
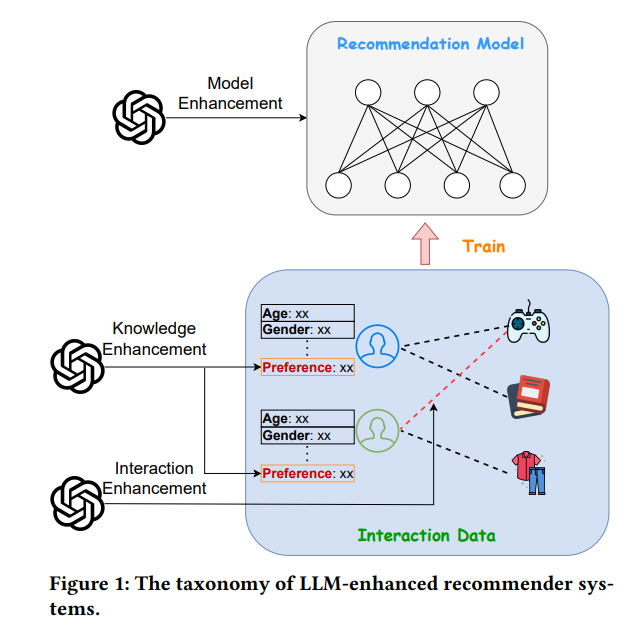
由于LLM增强推荐系统是基于传统推荐系统的,因此有必要先介绍其组件和面临的挑战,以便理解为什么以及在何处需要使用LLM。如图1所示,传统推荐系统通常由交互数据和推荐模型组成。
交互数据
传统推荐系统通过捕捉用户-物品记录中的协同信号 [26] 来进行训练,因此数据中的交互信息对训练是必不可少的。此外,许多基于内容的模型 [43] 提取用户和物品特征中的共现关系来进行推荐。因此,特征和交互数据是数据中的两个必要组成部分。然而,数据面临的两个挑战限制了传统推荐系统的进一步发展:
- 挑战1:对于特征,它们通常会被转换为数值或类别值进行使用,但缺乏来自知识层面的推理和理解。
- 挑战2:对于交互数据,数据稀疏性导致推荐系统模型的训练不足。
推荐模型
随着深度学习技术的广泛应用,推荐模型遵循“嵌入-深度网络”的模式。嵌入层将原始特征转化为密集的表示 [88],而深度网络则捕捉用户的兴趣 [84]。然而,它们也面临一个独特的挑战:
- 挑战3:推荐模型只能捕捉协同信号,但无法利用语义信息。
1.2 分类法
LLMERS通过增强传统推荐系统的基本组件,即交互数据和推荐模型,从而在服务过程中仅使用传统的推荐系统模型。根据LLM在解决这些挑战时的作用,我们将LLM增强推荐系统分为三大类,如图1所示:
- 知识增强
这类方法利用LLM的推理能力和世界知识为用户或物品生成文本描述。这些描述作为额外的特征,补充推理和理解的知识,从而解决挑战1。(第二部分)
- 交互增强
为了解决数据稀疏性问题(即挑战2),一些研究采用LLM生成新的用户-物品交互数据。(第三部分)
- 模型增强
LLM能够从语义角度分析交互数据,因此一些研究尝试利用LLM来辅助传统的推荐模型,从而解决挑战3。(第四部分) 为清晰起见,我们在图2中根据分类法展示了所有相关的LLMERS论文。

