
OpenAI 的首个视频生成模型 Sora,让「一句话生成视频」的前沿 AI 技术向上突破了一大截,引发了业界对于生成式 AI 技术方向的大讨论。 OpenAI 探索了视频数据生成模型的大规模训练。具体来说,研究人员在可变持续时间、分辨率和宽高比的视频和图像上联合训练了一个文本条件扩散模型。作者利用对视频和图像潜在代码的时空补丁进行操作的 transformer 架构,其最大的模型 Sora 能够生成长达一分钟的高质量视频。
OpenAI 认为,新展示的结果表明,扩展视频生成模型是构建物理世界通用模拟器的一条有前途的途径。
**Unsupervised Learning of Video Representations using LSTMs
Paper•1502.04681•Published Feb 17, 2015 *
**Recurrent Environment Simulators
Paper•1704.02254•Published Apr 7, 2017 *
**World Models
Paper•1803.10122•Published Mar 27, 2018 *
**Generating Videos with Scene Dynamics
Paper•1609.02612•Published Sep 9, 2016 *
**MoCoGAN: Decomposing Motion and Content for Video Generation
Paper•1707.04993•Published Jul 17, 2017 *
**Adversarial Video Generation on Complex Datasets
Paper•1907.06571•Published Jul 16, 2019 *
**Generating Long Videos of Dynamic Scenes
Paper•2206.03429•Published Jun 8, 2022 *
**VideoGPT: Video Generation using VQ-VAE and Transformers
Paper•2104.10157•Published Apr 21, 2021•2 *
**NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
Paper•2111.12417•Published Nov 24, 2021 *
**Imagen Video: High Definition Video Generation with Diffusion Models
Paper•2210.02303•Published Oct 5, 2022 *
**Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
Paper•2304.08818•Published Apr 18, 2023•4 *
**Photorealistic Video Generation with Diffusion Models
Paper•2312.06662•Published Dec 12, 2023•20 *
**Language Models are Few-Shot Learners
Paper•2005.14165•Published May 29, 2020•7 *
**An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Paper•2010.11929•Published Oct 23, 2020•2 *
**ViViT: A Video Vision Transformer
Paper•2103.15691•Published Mar 29, 2021 *
**Masked Autoencoders Are Scalable Vision Learners
Paper•2111.06377•Published Nov 12, 2021•1 *
**Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
Paper•2307.06304•Published Jul 13, 2023•23 *
**High-Resolution Image Synthesis with Latent Diffusion Models
Paper•2112.10752•Published Dec 21, 2021•5 *
**Auto-Encoding Variational Bayes
Paper•1312.6114•Published Dec 21, 2013 *
**Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Paper•1503.03585•Published Mar 12, 2015 *
**Denoising Diffusion Probabilistic Models
Paper•2006.11239•Published Jun 20, 2020•1 *
**Improved Denoising Diffusion Probabilistic Models
Paper•2102.09672•Published Feb 19, 2021•1 *
**Diffusion Models Beat GANs on Image Synthesis
Paper•2105.05233•Published May 12, 2021 *
**Elucidating the Design Space of Diffusion-Based Generative Models
Paper•2206.00364•Published Jun 1, 2022•1 *
**Scalable Diffusion Models with Transformers
Paper•2212.09748•Published Dec 20, 2022•4 *
**Zero-Shot Text-to-Image Generation
Paper•2102.12092•Published Feb 24, 2021 *
**Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Paper•2206.10789•Published Jun 22, 2022•1 *
**Hierarchical Text-Conditional Image Generation with CLIP Latents
Paper•2204.06125•Published Apr 13, 2022•1 *
**SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Paper•2108.01073•Published Aug 3, 2021•4 *
**Attention Is All You Need
Paper•1706.03762•Published Jun 13, 2017•23
使用LSTMs的视频表示的无监着学习
我们使用多层长短期记忆(LSTM)网络来学习视频序列的表示。我们的模型使用一个编码器LSTM将输入序列映射成一个固定长度的表示。这个表示使用单个或多个解码器LSTM解码,以执行不同的任务,如重构输入序列或预测未来序列。我们实验了两种类型的输入序列 - 图像像素的补丁和使用预训练的卷积网络提取的视频帧的高级表示("感知")。我们探索了不同的设计选择,例如解码器LSTM是否应该依赖于生成的输出。我们定性地分析模型的输出,以查看模型如何将学习到的视频表示外推到未来和过去。我们尝试可视化和解释学习到的特征。我们通过在更长的时间尺度和领域外数据上运行模型来对模型进行压力测试。我们通过为监督学习问题微调它们来进一步评估表示 - 在UCF-101和HMDB-51数据集上的人类行为识别。我们展示了这些表示如何帮助提高分类准确性,尤其是当训练样本很少时。即使是在不相关数据集上预训练的模型(YouTube视频的300小时)也可以帮助提高行动识别性能。

循环环境模拟器

可以通过模拟环境如何响应行动来改变的模型,可以被代理用来有效地计划和行动。我们通过引入能够对未来数百个时间步进行时间上和空间上连贯预测的循环神经网络,改进了之前从高维像素观测中得到的环境模拟器。我们提供了对影响性能因素的深入分析,这是迄今为止最广泛的尝试,以深化理解这些模型的属性。我们解决了计算效率低下的问题,提出了一个不需要在每个时间步生成高维图像的模型。我们展示了我们的方法可以被用来改善探索,并且可以适应许多不同的环境,即10个Atari游戏,一个3D赛车环境,和复杂的3D迷宫。
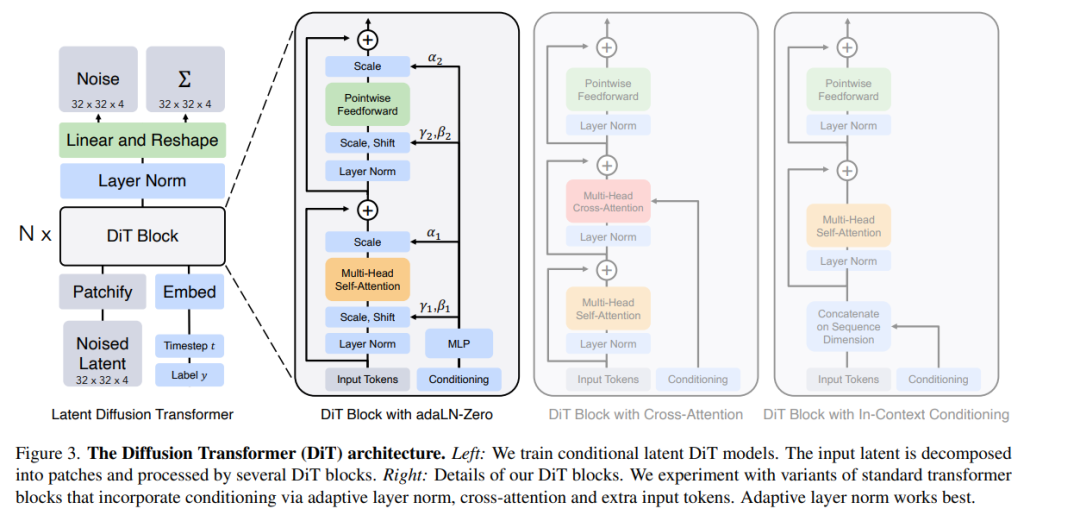
可扩展的Transformers扩散模型

我们探索了一类基于Transformers架构的新型扩散模型。我们训练了图像的潜在扩散模型,用操作潜在补丁的Transformer替换了通常使用的U-Net主干。我们通过前向传递复杂度(以Gflops衡量)的视角分析了我们的扩散Transformers(DiTs)的可扩展性。我们发现,具有更高Gflops的DiTs —— 通过增加Transformer的深度/宽度或增加输入令牌的数量 —— 一致地具有更低的FID。除了具有良好的可扩展性属性外,我们最大的DiT-XL/2模型在类条件ImageNet 512x512和256x256基准测试上超越了所有先前的扩散模型,后者实现了2.27的最先进FID。
CGL与图基础模型 大型语言模型(LLMs)在作为各种自然语言处理(NLP)下游任务的基础模型方面取得了显著的成功。然而,图基础模型还处于起步阶段。在本节中,我们将介绍CGL技术如何与构建有效的图基础模型相关联。 8.1 促进图基础模型训练 构建图基础模型的一个有前途的方法是设计策略来微调预训练的LLMs,使其接受分词化的图输入,以便图结构知识与语言数据中包含的知识对齐。然而,这样的连续训练不可避免地会触发灾难性遗忘问题,因为图数据与用于预训练LLMs的语言数据位于显著不同的领域。因此,在这个过程中,CGL技术和一般的持续学习技术变得不可或缺。 此外,理想的图基础模型,无论是基于预训练的LLMs之上开发还是从零开始训练,都应通过持续整合新出现的数据来维持一个最新的知识库。然而,这个持续学习过程也可能引起遗忘问题,这也是当前LLMs面临的问题。在这种情况下,应开发CGL技术来解决这个问题。 此外,当新的图数据对应于不同的领域时,例如,模型可能同时遇到生物网络数据和分子图数据,跨领域学习也可能触发遗忘问题。在这种情景下,可以开发领域增量学习(domain-IL)CGL技术来解决问题。 8.2 开发大型图模型的潜在高效方式 与LLMs不同,LLMs在NLP任务中展示了令人印象深刻的性能,而大模型对于图数据的有效性仍然是一个问题。基于参数隔离的CGL模型在可能显著增加大小的扩展数据集上学习,模型的大小相应扩展。因此,它提供了一种潜在的解决方案,通过逐步扩展模型和数据集从零开始开发大型图模型。一方面,逐步学习任务而不是同时针对所有任务优化模型可能会降低优化难度。另一方面,CGL方法只会在必要时分配新参数[3],这可以帮助缓解大型模型中的参数冗余问题。此外,现有的大型预训练图模型通常是特定于领域的[128],极大地限制了它们的能力。幸运的是,这一挑战可能通过利用在领域增量学习(domain-IL)下工作的CGL技术来解决,该技术旨在连续跨多个不同领域训练给定的图学习模型。
