

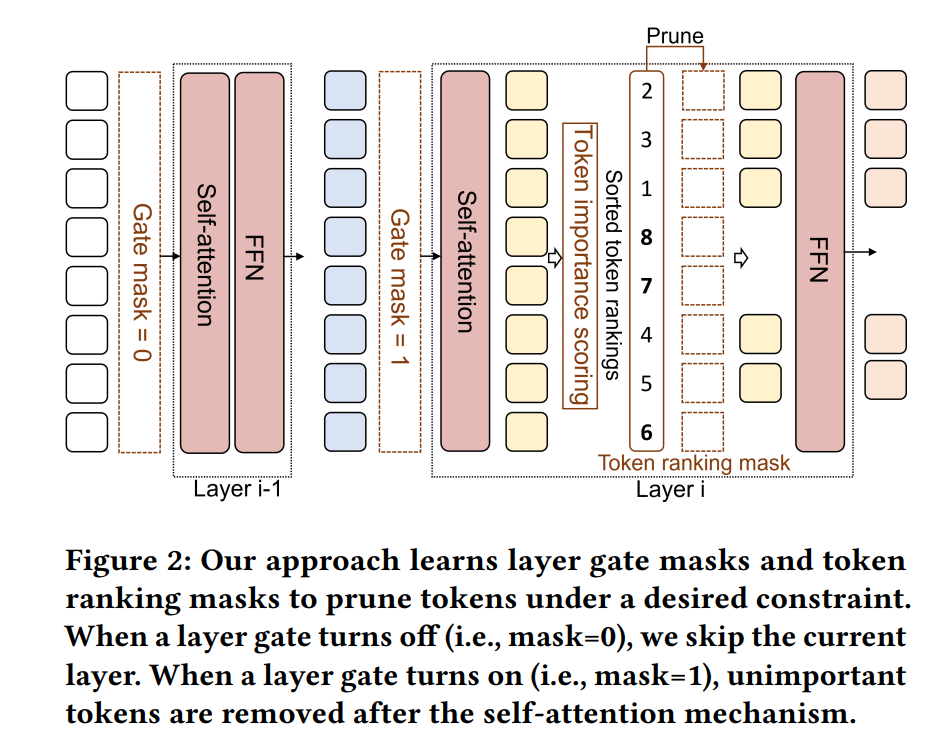
在资源受限的场景中,部署像BERT这样的预训练Transformer模型到下游任务上是具有挑战性的,因为它们的推理成本很高,并且随着输入序列长度的增加而迅速增加。在这项工作中,我们提出了一种约束意识的并且使用排名提炼的令牌剪枝方法ToP,它在输入序列通过各层时选择性地移除不必要的令牌,使模型在保持准确性的同时提高在线推理速度。ToP通过一种排名提炼的令牌提炼技术克服了传统自注意力机制中令牌重要性排名不准确的限制,该技术从未剪枝模型的最后一层提炼有效的令牌排名到剪枝模型的早期层。然后,ToP引入了一种从粗糙到精细的剪枝方法,它自动选择Transformer层的最佳子集,并通过改进的𝐿0正则化在这些层内优化token剪枝决策。在GLUE基准测试和SQuAD任务上的大量实验表明,ToP在准确性和加速方面超越了最先进的令牌剪枝和模型压缩方法。ToP将BERT的平均FLOPs降低了8.1倍,同时在GLUE上实现了具有竞争力的准确性,并在Intel CPU上提供了最高7.4倍的实际延迟加速。
https://www.zhuanzhi.ai/paper/052ae1af5bdb61e9121ba73b5ab31c1c
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日