视觉系统看到并理解视觉场景的组合性质对于理解我们的世界至关重要。在真实世界的环境中,物体与其位置之间的复杂关系、模糊性和变化可以更好地用受到语法规则和其他模态(如音频和深度)制约的人类语言来描述。 模型学习如何弥合这些模态之间的差距,并结合大规模训练数据,促进了上下文推理、泛化和测试时的即时能力。这些模型被称为基础模型。这种模型的输出可以通过人提供的提示进行修改,而无需重新训练,例如,通过提供一个边界框来分割特定的物体,通过询问关于图像或视频场景的问题进行交互式对话,或通过语言指令操纵机器人的行为。 在这次调查中,我们提供了这些新兴基础模型的全面回顾,包括结合不同模态(视觉、文本、音频等)的典型架构设计、训练目标(对比性、生成性)、预训练数据集、微调机制,以及常见的提示模式:文本、视觉和异质性。 我们讨论了计算机视觉中基础模型的开放性挑战和研究方向,包括它们的评估和基准测试困难、对真实世界理解的差距、上下文理解的局限性、偏见、对对抗性攻击的脆弱性和解释性问题。我们回顾了这一领域的最新发展,全面系统地涵盖了基础模型的广泛应用。本工作研究的基础模型的全面列表可以在
https://github.com/awaisrauf/Awesome-CV-Foundational-Models上找到。
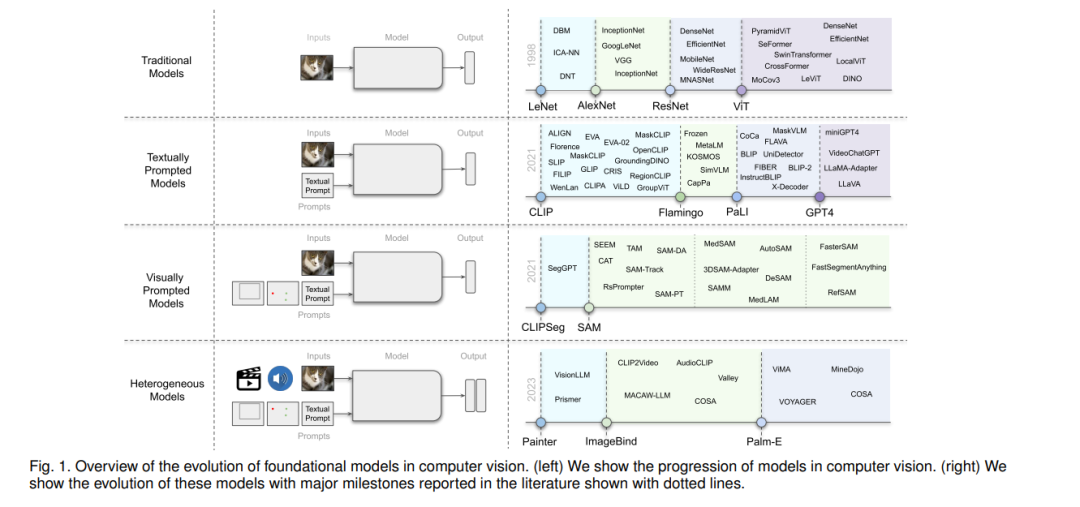
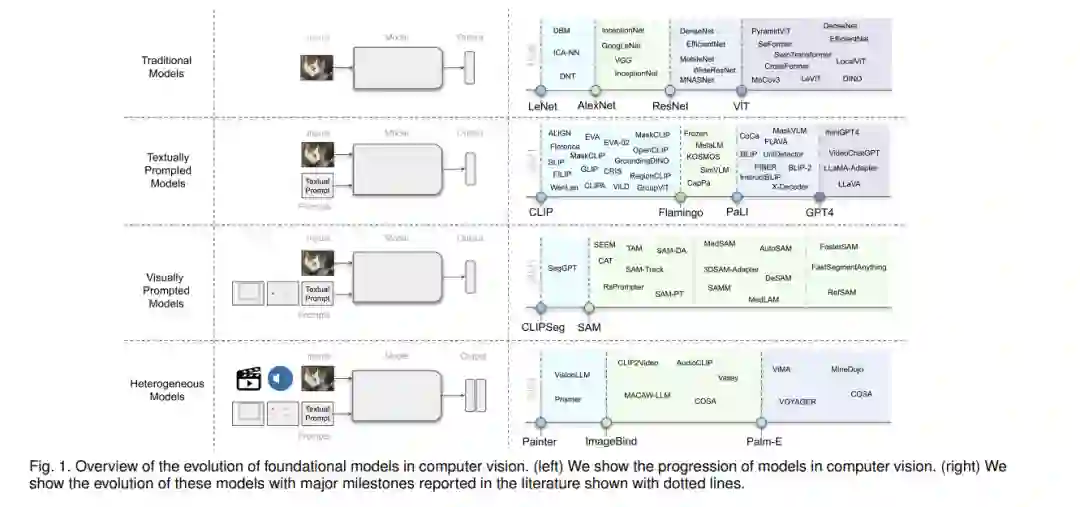
近年来,我们已经见证了开发基础模型的显著成功,这些模型在大规模的广泛数据上进行训练,一旦训练完成,它们就可以作为一个基础,并可以适应(例如,微调)与原始训练模型相关的广泛的下游任务[18]。尽管基础模型的基本组成部分,如深度神经网络和自监督学习,已经存在了很多年,但最近的激增,特别是通过大型语言模型(LLMs),主要可以归因于大规模地扩展数据和模型大小[346]。例如,像GPT-3 [20]这样拥有数十亿参数的最新模型已经被有效地用于零/少量样本学习,而无需大规模的任务特定数据或模型参数更新,从而实现了令人印象深刻的性能。同样,最近的5400亿参数的Pathways Language Model (PaLM)已经在从语言理解和生成到推理和代码相关任务的许多具有挑战性的问题上展示了最先进的能力[52, 8]。
与自然语言处理中的大型语言模型(LLMs)并行,最近的文献中也探讨了用于不同感知任务的大型基础模型。例如,像CLIP [214]这样的预训练的视觉-语言模型(VL)在不同的下游视觉任务上都展示出了有前景的零样本性能,包括图像分类和物体检测。这些VL基础模型通常使用从网络上收集的数百万的图像-文本对进行训练,并提供具有泛化和转移能力的表示。然后,这些预训练的VL基础模型可以通过为其提供给定任务的自然语言描述和提示来适应下游任务。例如,开创性的CLIP模型使用精心设计的提示在不同的下游任务上进行操作,包括零样本分类,其中文本编码器通过类名或其他自由形式的文本动态地构造分类器。在这里,文本提示是手工制作的模板,例如,“一张{label}的照片”,这有助于指定文本与视觉图像内容相对应。最近,许多工作也探索了通过在特定的指令集上对它们进行微调,为VL模型添加交互式能力[169, 360, 57, 190, 314]。
除了大型的视觉-语言基础模型,还有一些研究努力致力于开发可以由视觉输入提示的大型基础模型。例如,最近推出的SAM [140]可以执行与类别无关的分割,给定一个图像和一个视觉提示,如盒子、点或遮罩,这指定了在图像中要分割的内容。这样的模型在数十亿的物体遮罩上进行训练,遵循模型在循环中的数据集注释设置(半自动化)。进一步说,这种基于通用视觉提示的分割模型可以被适应于特定的下游任务,如医学图像分割[189, 292]、视频物体分割[316]、机器人学[303]和遥感[35]。除了基于文本和视觉提示的基础模型,研究工作还探索了开发模型,努力对齐多个配对的模态(例如,图像-文本、视频-音频或图像-深度),以学习对不同下游任务有帮助的有意义的表示[92, 102, 188]。
论文组织
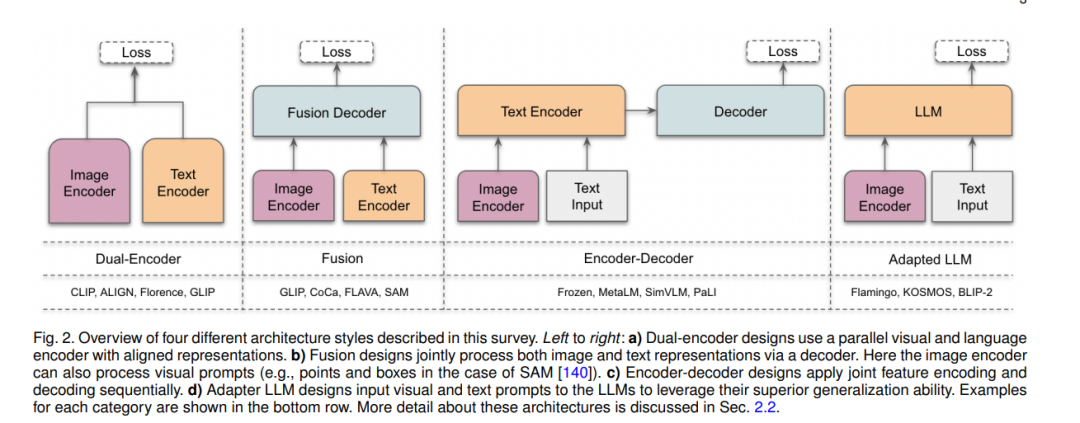
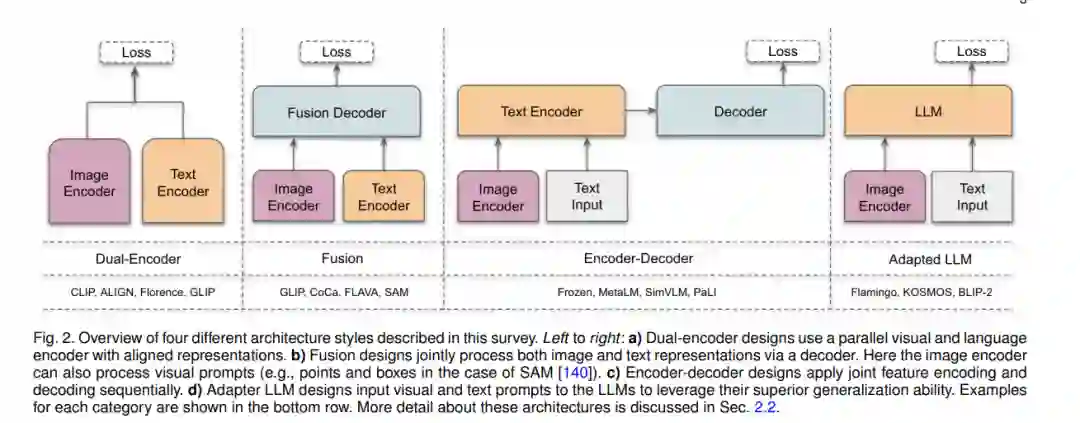
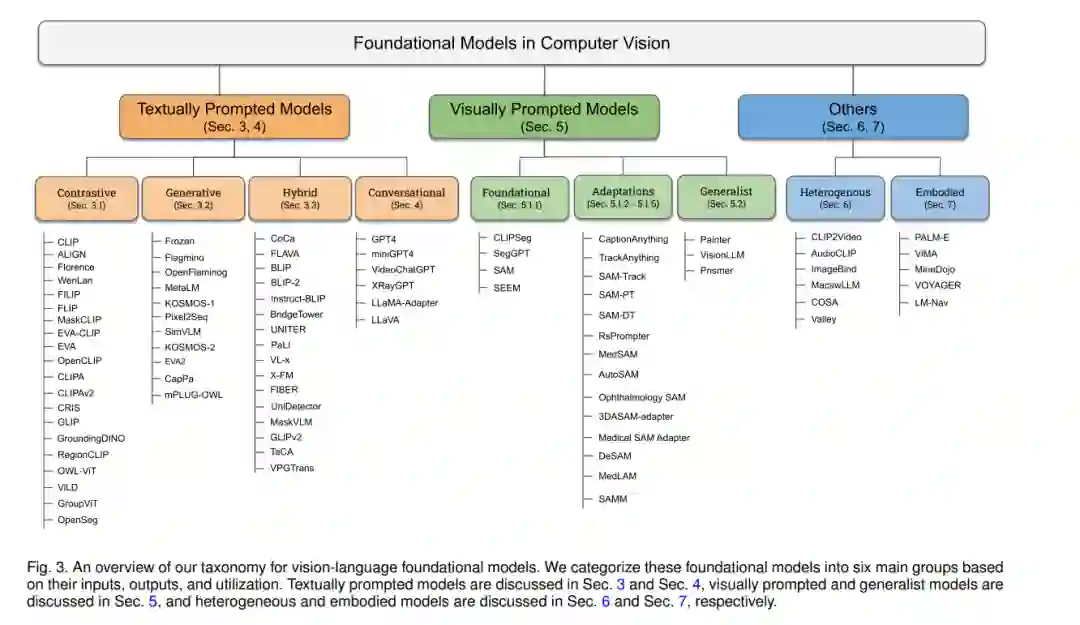
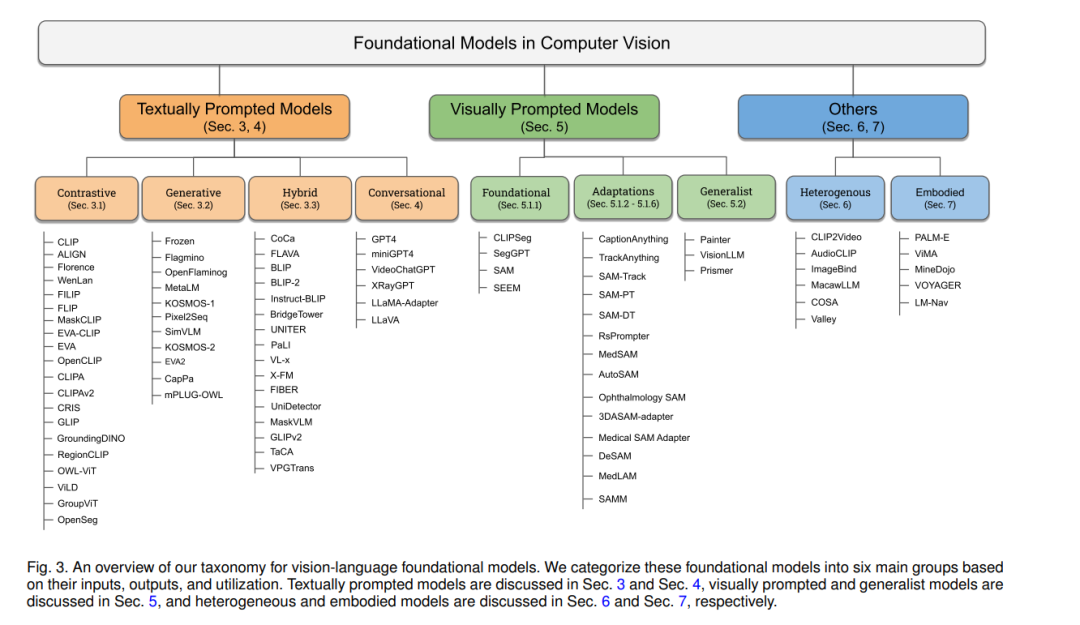
在这项工作中,我们系统地回顾了计算机视觉中的基础模型。首先,我们简要介绍了基础模型的背景和初步内容,简要涵盖了常见的架构类型、自监督学习目标、大规模训练和提示工程(第2节)。然后,我们将现有的工作区分为基于文本的提示(第3-4节)、基于视觉的提示(第5节)、基于异构模态(第6节)和基于具体实体的基础模型(第7节)。在基于文本提示的基础模型中,我们进一步将它们区分为对比、生成、混合(对比和生成)以及会话型VL模型。最后,我们根据我们的分析讨论了开放的挑战和研究方向(第8节)。接下来,我们回顾了与我们相关的其他调查,并讨论了它们的差异和独特之处。
总结
对于开发能够有效感知和推理现实世界的AI系统,具有对多种模态(包括自然语言和视觉)的基础理解的模型是至关重要的。这次调查回顾了视觉和语言基础模型,重点关注它们的架构类型、训练目标、下游任务适应性及其提示设计。我们为基于文本提示、基于视觉提示和异构模态模型提供了系统的分类。我们广泛地涵盖了它们在各种视觉任务中的应用,包括零样本识别和定位能力、关于图像或视频的视觉对话、跨模态和医学数据理解。我们总结了视觉中的基础模型如何作为通用模型同时解决多个任务,以及它们与大型语言模型的结合如何催生基础实体代理,这些代理可以在复杂环境中不断学习和导航。我们希望这一努力将进一步推动研究者充分利用基础模型的潜力,同时解决它们的局限性,例如有限的上下文理解、偏见和对恶意使用的脆弱性。