279页ppt!Interspeech 2022《弱标签学习》教程,CMU Bhiksha Raj讲授

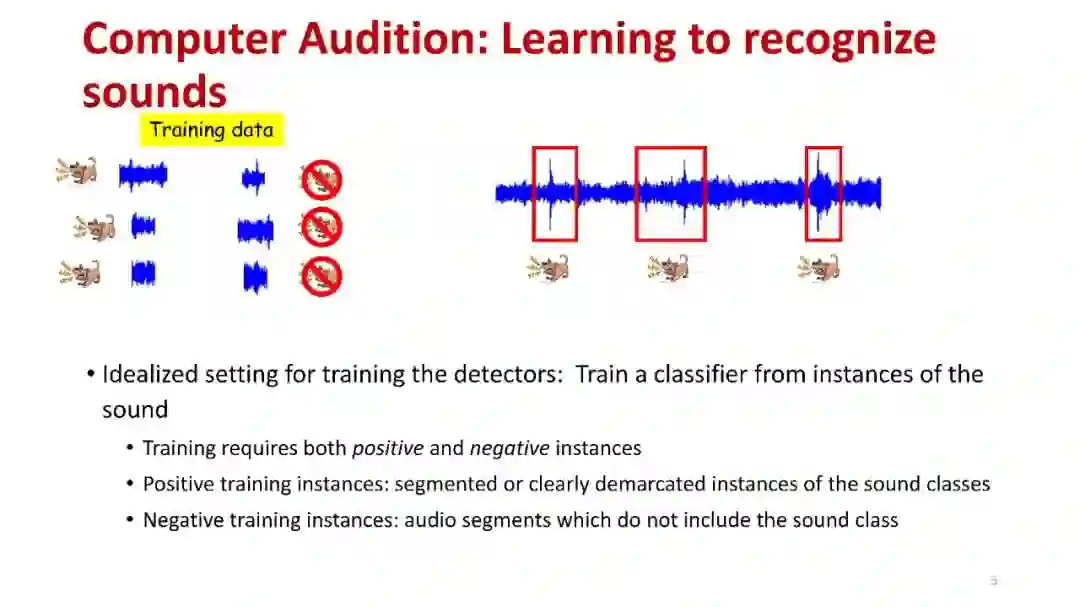
训练各种精确音频分类器的关键瓶颈之一是需要“强标记”的训练数据,这些数据提供要识别的音频事件的精确划分实例。然而,这种数据很难获得,特别是大量的数据。另一种更受欢迎的方法是使用“弱”标记数据来训练模型,这种数据包括只标记声音类别存在或不存在的录音,而不添加关于声音出现次数或它们在录音中的位置的额外细节。弱标记的数据比强标记的数据更容易获得;然而,使用这些数据进行培训也面临许多挑战。在本教程中,我们将讨论从弱标签数据中训练音频(和其他)分类器的问题,包括几种最先进的形式,它们的限制和局限性,以及未来的研究领域。
Bhiksha Raj
IEEE会员,卡内基梅隆大学教授。Bhiksha Raj是卡内基梅隆大学计算机科学学院的教授。他的研究领域包括语音和音频处理以及声学场景分析。他是从弱标签学习音频分类器领域的先驱之一。Raj之前曾在ICASSP、Interspeech和其他各种会议上主持过几次教程。他是IEEE会士




专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“W279” 就可以获取《279页ppt!Interspeech 2022《弱标签学习》教程,CMU Bhiksha Raj讲授》专知下载链接



登录查看更多
相关内容

Bhiksha Raj,卡内基梅隆大学计算机学院教授,IEEE研究员。官方主页:http://mlsp.cs.cmu.edu/people/bhiksha/index.php
相关主题


相关VIP内容
相关资讯
相关论文