

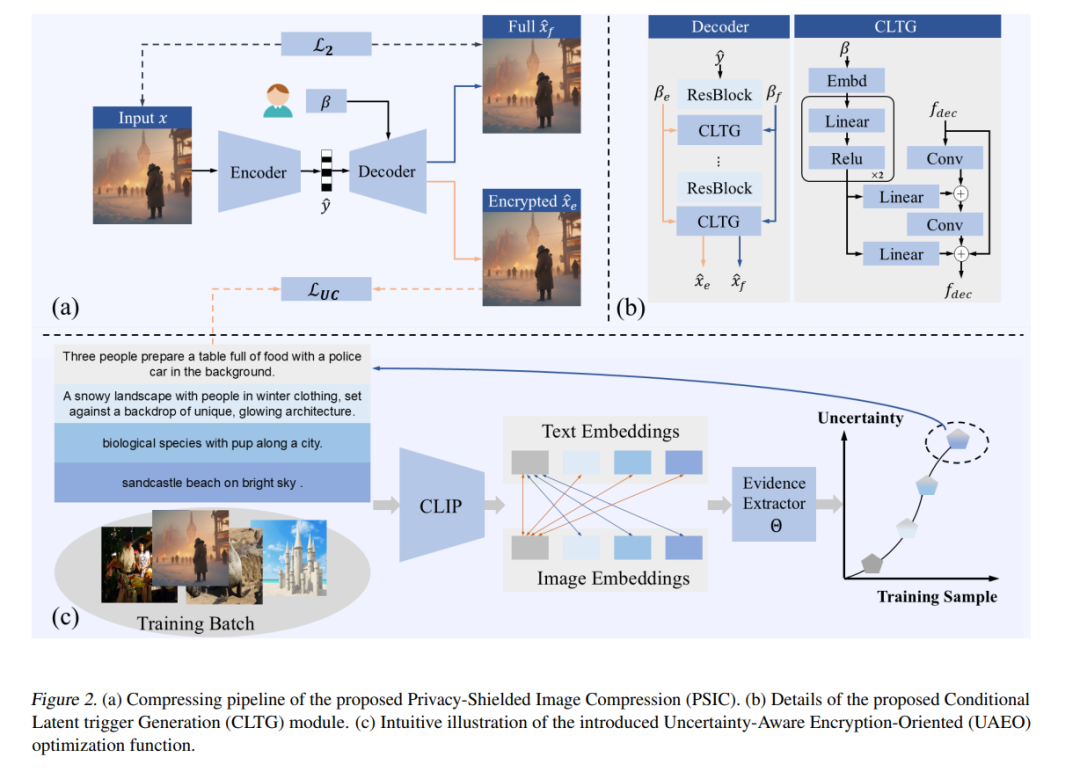
视觉-语言预训练模型(VLP)在语义理解方面的提升,使得保护公开发布图像不被搜索引擎等工具滥用变得愈发困难。在此背景下,本文尝试通过在图像压缩阶段引入防护机制,以防止图像被滥用,从而保护用户隐私。具体而言,我们提出了一种灵活的编码方法,称为隐私防护图像压缩(Privacy-Shielded Image Compression,PSIC),该方法能够生成具有多种解码选项的比特流。默认情况下,该比特流可解码为感知质量良好的图像,同时阻止视觉-语言预训练模型对其进行语义理解。
此外,该方法仍保留了原有的图像压缩功能。在提供可定制的输入条件下,PSIC 可重建保留完整语义信息的图像。我们提出了一个条件潜变量触发生成(Conditional Latent Trigger Generation,CLTG)模块,用于根据定制条件生成偏置信息,引导解码过程生成不同的图像版本。同时,我们设计了一个不确定性感知的加密优化函数(Uncertainty-Aware Encryption-Oriented,UAEO),通过利用目标 VLP 模型对训练数据的不确定性推断出的软标签,来提升对抗能力。
为同时兼顾图像的加密性能与感知质量,本文还引入了一种自适应多目标优化策略,可在统一的训练过程中实现二者的协同优化。所提出的方法具有即插即用的特性,可无缝集成至大多数现有的学习型图像压缩(Learned Image Compression,LIC)模型中。大量实验结果表明,该方法在多个下游任务中均表现出色,有效验证了其设计的有效性。
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
144+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
144+阅读 · 2023年3月29日