【导读】计算机视觉顶会CVPR2022接收论文列表已公布,你的文章中了吗?

根据官方信息统计,今年共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。

作为人工智能领域的顶级会议,CVPR 每年都会吸引大量研究机构和高校参会,近年来,CVPR 的投稿数量也在持续增加,从 2019 年的 5000 多篇有效投稿增长到 2021 年 7500 篇,去年达到 8100 多篇有效投稿。今年更是数量稳增,达到 9155 篇。今年大会将于 6 月 18 日至 22 日在温哥华会议中心举行。
CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。

虽然论文接收列表还没有公布,但已经有机构、学者等开始分享论文被接收的喜悦。

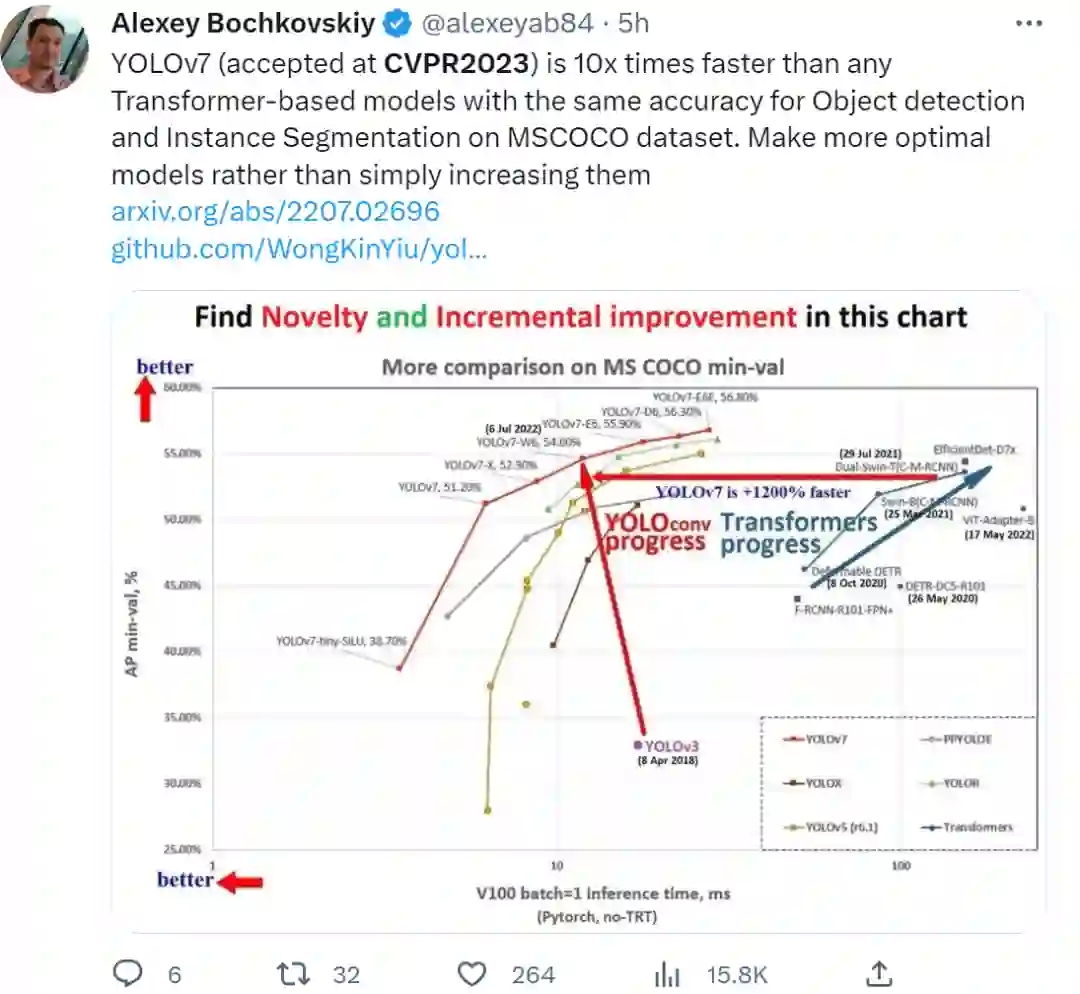
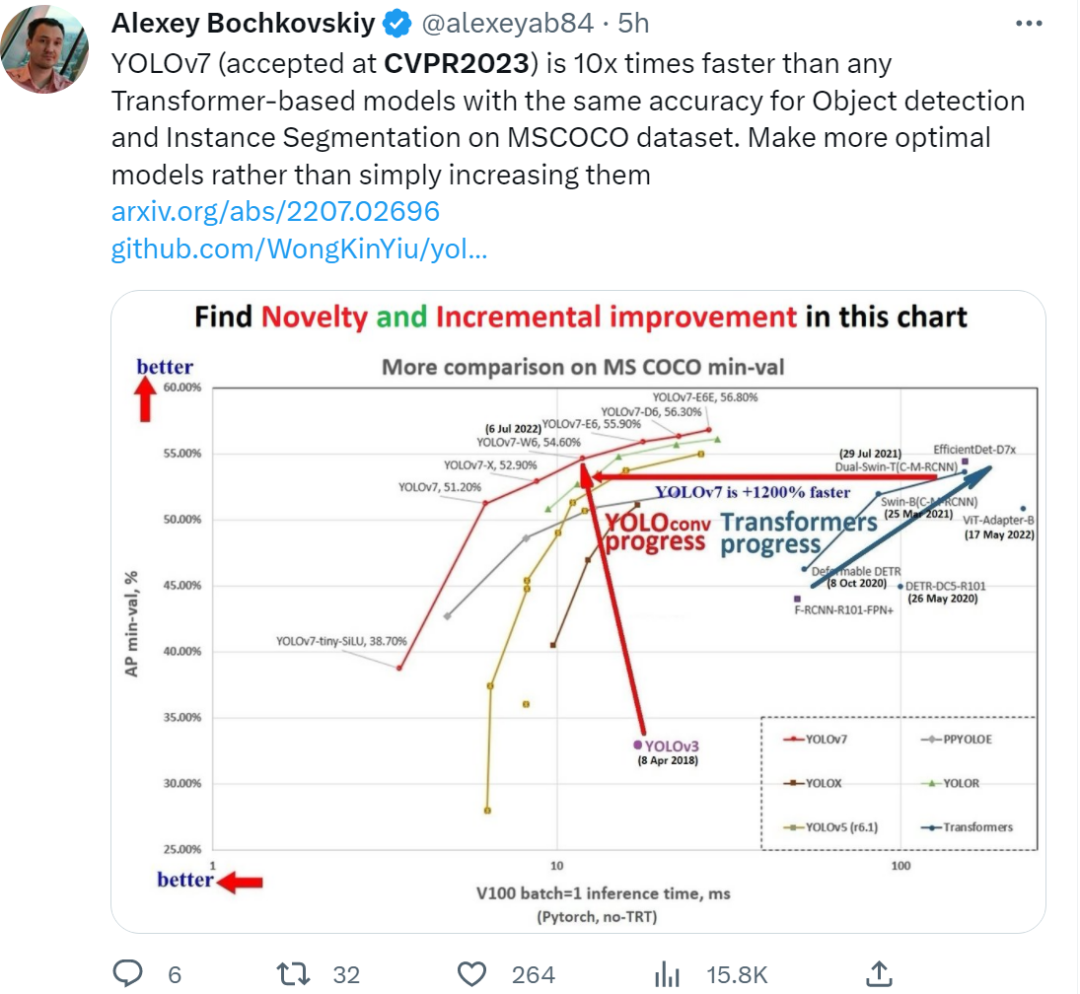
YOLO 项目维护大神 Alexey Bochkovskiy 表示,自己参与的论文《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》已被接收,该研究的三位作者 Chien-Yao Wang、Alexey Bochkovskiy 和 Hong-Yuan Mark Liao 还是 YOLOv4 的原班人马。
据了解,YOLOv7 在 5 FPS 到 160 FPS 范围内,速度和精度都超过了所有已知的目标检测器,并在 GPU V100 上,30 FPS 的情况下达到实时目标检测器的最高精度 56.8% AP。YOLOv7 是在 MS COCO 数据集上从头开始训练的,不使用任何其他数据集或预训练权重。由此看来,这篇入选也是意料之中的事。
https://www.zhuanzhi.ai/paper/30b8135e79b9c6e6ef1f294f88cb2e99

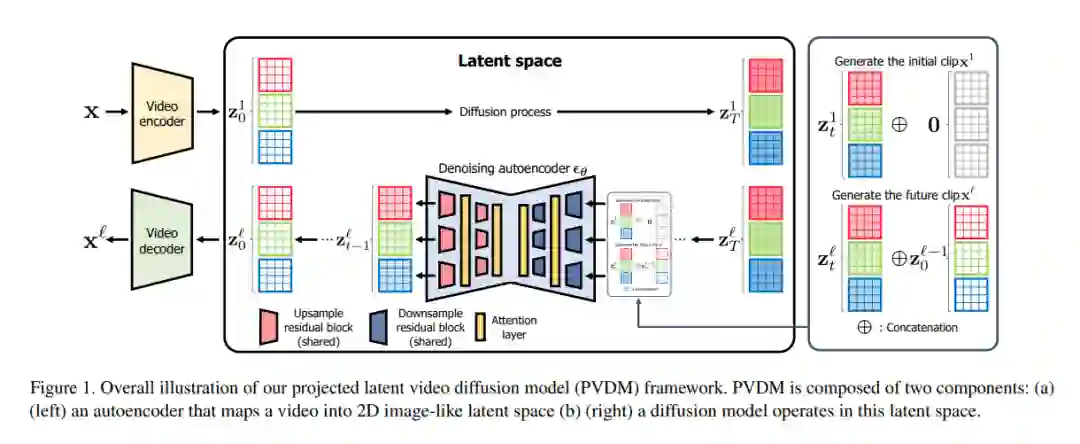
尽管深度生成模型取得了显著进展,但由于其高维和复杂的时间动态以及大的空间变化,合成高分辨率和时间连贯的视频仍然是一个挑战。最近关于扩散模型的工作显示了解决这一挑战的潜力,但它们存在严重的计算和内存效率低下,限制了可扩展性。为解决这个问题,本文提出一种新的视频生成模型,即投影潜视频扩散模型(PVDM),一种概率扩散模型,在低维潜空间中学习视频分布,因此可以在有限资源下有效地对高分辨率视频进行训练。PVDM由两个组件组成:(a)一个自动编码器,将给定视频投影为二维形状的潜向量,分解视频像素的复杂立方结构;(b)一个专门为新的分解潜空间设计的扩散模型架构,以及用单个模型合成任意长度视频的训练/采样程序。在流行的视频生成数据集上的实验结果表明,PVDM比之前的视频合成方法具有更好的性能;PVDM在UCF-101长视频(128帧)生成基准上获得了639.7的FVD分数,比之前的最先进水平提高了1773.4。
https://www.zhuanzhi.ai/paper/ccc7e644f328b7771b54c64b2992137c